MySQL DBA视角
1、MySQL部署前准备
-
关闭NUMA
NUMA(Non-Uniform Memory Access,非一致性内存访问)服务器的基本特征是 Linux 将系统的硬件资源划分为多个软件抽象,称为节点。每个节点上有单独的 CPU、内存和 I/O 槽口等。CPU 访问自身 Node 内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致内存访问 NUMA 的由来。
简单来比方就是如果是8G内存,4核CPU,那么一个核心分得2G内存,减少共享内存带来的资源争夺。但是MySQL分配了6G内存。某些线程超出节点本地内存部分会被 SWAP 到磁盘上,而不是使用其他节点的物理内存,引发性能问题。
bios级别关闭【推荐】 在bios层面numa关闭时,无论os层面的numa是否打开,都不会影响性能。一般在bios的Advanced下 使用如下命令可以查看numactl是否被关闭 numactl --hardware available: 1 nodes (0) #如果是2或多个nodes就说明numa没关掉 ============================================================================ OS级别关闭 注意:在os层numa关闭时,bios层是打开的话会影响性能,QPS会下降15-30%; vi /boot/grub2/grub.cfg 找到并安装如下设置numa=off kernel /boot/vmlinuz-2.6.18-128.1.16.0.1.el5 root=LABEL=DBSYS ro bootarea=dbsys rhgb quiet console=ttyS0,115200n8 console=tty1 crashkernel=128M@16M numa=off initrd /boot/initrd-2.6.18-128.1.16.0.1.el5.img ============================================================================ 数据库级别关闭 mysql> show variables like '%numa%'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | innodb_numa_interleave | OFF | +------------------------+-------+ 或者修改etc/init.d/mysqld 将$bindir/mysqld_safe --datadir="$datadir"这一行修改为: /usr/bin/numactl --interleave all $bindir/mysqld_safe --datadir="$datadir" --pid-file="$mysqld_pid_file_path" $other_args >/dev/null & wait_for_pid created "$!" "$mysqld_pid_file_path"; return_value=$? -
开启CPU高性能模式
Bios设置Operator Mode设置为Maximum Performance
-
阵列卡RAID配置
建议配置为raid10
-
关闭THP
THP(transparent_hugepage)即分配大页内存,MySQL有自己的内存分配机制。
chomd +x /etc/rc.d/rc.local 修改 /etc/rc.local 在文件末尾添加如下指令 if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi # 查看transparent hugepage是否关闭 cat /sys/kernel/mm/transparent_hugepage/enabled # 显示这样为关闭 always madvise [never] -
网卡绑定
bonding技术,业务数据库服务器都要配置bonding继续。建议是主备模式。交换机一定要堆叠。
-
系统层面参数优化
更改文件句柄和进程数 修改 /etc/sysctl.conf vm.swappiness = 5 # 交换分区(也可以设置为0)的攻击性。较高的值会更激进 vm.dirty_ratio = 20 # 文件系统缓存脏页数量达到系统内存百分之多少时,系统阻塞处理缓存脏页 vm.dirty_background_ratio = 10 # 文件系统缓存脏页数量达到系统内存百分之多少时,系统异步处理缓存脏页 net.ipv4.tcp_max_syn_backlog = 819200 # 半连接队列大小 net.core.netdev_max_backlog = 400000 # 内核从网卡收到数据包后,交由协议栈(如IP、TCP)处理之前的缓冲队列 net.core.somaxconn = 4096 # 指服务端所能accept即处理数据的最大客户端数量,即完成连接上限 net.ipv4.tcp_tw_reuse=1 # 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭 net.ipv4.tcp_tw_recycle=0 # 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭 ===================================================================== 防火墙 禁用selinux /etc/sysconfig/selinux 更改SELINUX=disabled. iptables如果不使用可以关闭。如果需要打开MySQL需要的端口号 ===================================================================== 文件系统优化 推荐使用XFS文件系统 MySQL数据分区独立 ,例如挂载点为: /data fdisk /dev/sdb 依次安装提示键入 p n l w 修改 /etc/fstab 加入 /dev/sdb /data xfs defaults,noatime,nodiratime,nobarrier - defaults 默认值包括rw、suid、dev、exec、auto、nouser和async,文件挂载配置的很多情况下都使用默认值 - noatime 不更新文件访问时间 - nodiratime 不更新目录访问时间 - nobarrier 不开启barrier ===================================================================== 不使用LVM ===================================================================== io调度 SAS: deadline SSD&PCI-E: noop - deadline 对读写请求进行了分类管理,并且在调度处理的过程中读请求具有较高优先级。这主要是因为读请求往往是同步操作,对延迟时间比较敏感,而写操作往往是异步操作,可以尽可能的将相邻访问地址的请求进行合并,但是,合并的效率越高,延迟时间会越长。 - noop电梯式调度器,实现了一个简单的FIFO队列,它像电梯的工作方式一样对I/O请求进行组织。它是基于先入先出(FIFO)队列概念的 Linux 内核里最简单的I/O 调度器。此调度程序最适合于固态硬盘。 centos 7 默认是deadline,使用如下命令查看 cat /sys/block/sda/queue/scheduler 修改调度算法 grubby --update-kernel=ALL --args="elevator=noop" -
预装MySQL前硬件烤机压测
yum install -y epel-release yum install -y stress # 烤机CPU stress -c 4 # 烤机 MEM stress -m 3 --vm-bytes 300M # 烤机多参数 stress -c 4 -m 2 -d 1 # 重要参数解读 -c # forks 产生多个处理sqrt()函数的CPU进程 -m # 产生多个处理malloc()内存分配 --vm-bytes bytes # 指定内存的byte数,默认值是1 -d # 写进程,写入固定大小,通过mkstemp()函数写入当前目录 --hdd-bytes bytes # 指定写的字节数,默认1G
2、MySQL8.0二进制安装过程
①、创建用户,用户组
# 创建用户组
groupadd mysql
# 创建用户加入用户组,且不允许登录
useradd -r -g mysql -s /bin/false mysql
# 安装基础库
yum install libaio
yum install library
②、解压
tar -xvf mysql-8.0.30-linux-glibc2.12-x86_64.tar.xz -C /opt/module/
mv /opt/module/文件夹 /opt/module/mysql80
ln -s /opt/module/mysql80 /usr/local/mysql
③、加入PATH
# 修改 /etc/profile,加入
PATH=/usr/local/mysql/bin:$PATH
# 更新环境变量
source /etc/profile
# 测试环境变量
mysql -V
④、挂载硬盘
# 查看未挂载的硬盘
fdisk -l
# 依次安装提示键入
# p n l w
fdisk /dev/未挂载的硬盘
# 格式化文件系统
mkfs.xfs 未挂载硬盘
# 挂载
mount /dev/未挂载硬盘 /data
# 开机挂载,修改/etc/fstab,加入
/dev/未挂载硬盘 /data defaults,noatime,nodiratime,nobarrier
# 查看挂载
df -hT /dev/未挂载的硬盘
⑤、修改目录权限
mkdir -p /data/mysql80
chown -R mysql:mysql /data
⑥、创建/etc/my.cnf
[mysqld]
user=mysql # 管理用户
datadir=/data/mysql80 # 数据路径
basedir=/usr/local/mysql # 软件路径
socket=/tmp/mysql.sock # socket文件位置
server_id=51 # 服务器ID,主从时标识不同主机
default_authentication_plugin=mysql_native_password #使用旧版本密码插件
log_bin=/data/mysql80/binlog # 二进制日志
binlog_format=row # 二进制日志行格式
gtid-mode=on # 开启gtid模式,会记录gtid的标识符
enforce-gtid-consistency=on # 强制GTID一致性,保证事务的安全
log-slave-updates=on # MySQL5.7之前必须配置
port=3306 # 端口
log_error=/data/mysql80/log/mysql-err.log # 错误日志路径
log_bin=/data/mysql80/log/mysql-bin # binlog日志路径
slow_query_log=on # 开启慢查询日志
slow_query_log_file=/data/mysql80/log/mysql-slow.log # 慢查询日志位置
long_query_time=0.5 # 记录执行时间(real time)超过该值以上的SQL,默认值为10秒
log_queries_not_using_indexes=1 # 未使用索引的查询是否写入慢日志
log_throttle_queries_not_using_indexes=1000 # 限制每分钟所记录的slow log数量
innodb_log_file_size=2048M # redo log大小,建议大小 512M-4G
innodb_log_files_in_group=4 # redo log组数,建议 2-4组
innodb_temp_data_file_path=ibtmp1:512M;ibtmp2:512M:autoextend:max:512M # 临时表空间,一般2-3个,大小512M-1G
innodb_undo_tablespaces=4 #undo文件个数,建议3-5个
[mysql]
[client]
[server]
[mysqld_safe]
[mysqldump]
⑦、初始化&启动&登录
初始化
# 不设置密码,root密码为空
mysqld --initialize-insecure
启动方式
systemd【系统管理】 -> /etc/init.d/mysqld 【系统管理】 ->mysql.server 【系统管理】-> mysqld_safe【安全启动,crash会重启服务】->mysqld
mysqld_safe --defaults-file=/etc/my.cnf &
可加参数
--skip-grant-tables :跳过授权表
--skip-networking :不启动网络
关闭命令shutdown
3、MySQL体系总览
架构介绍
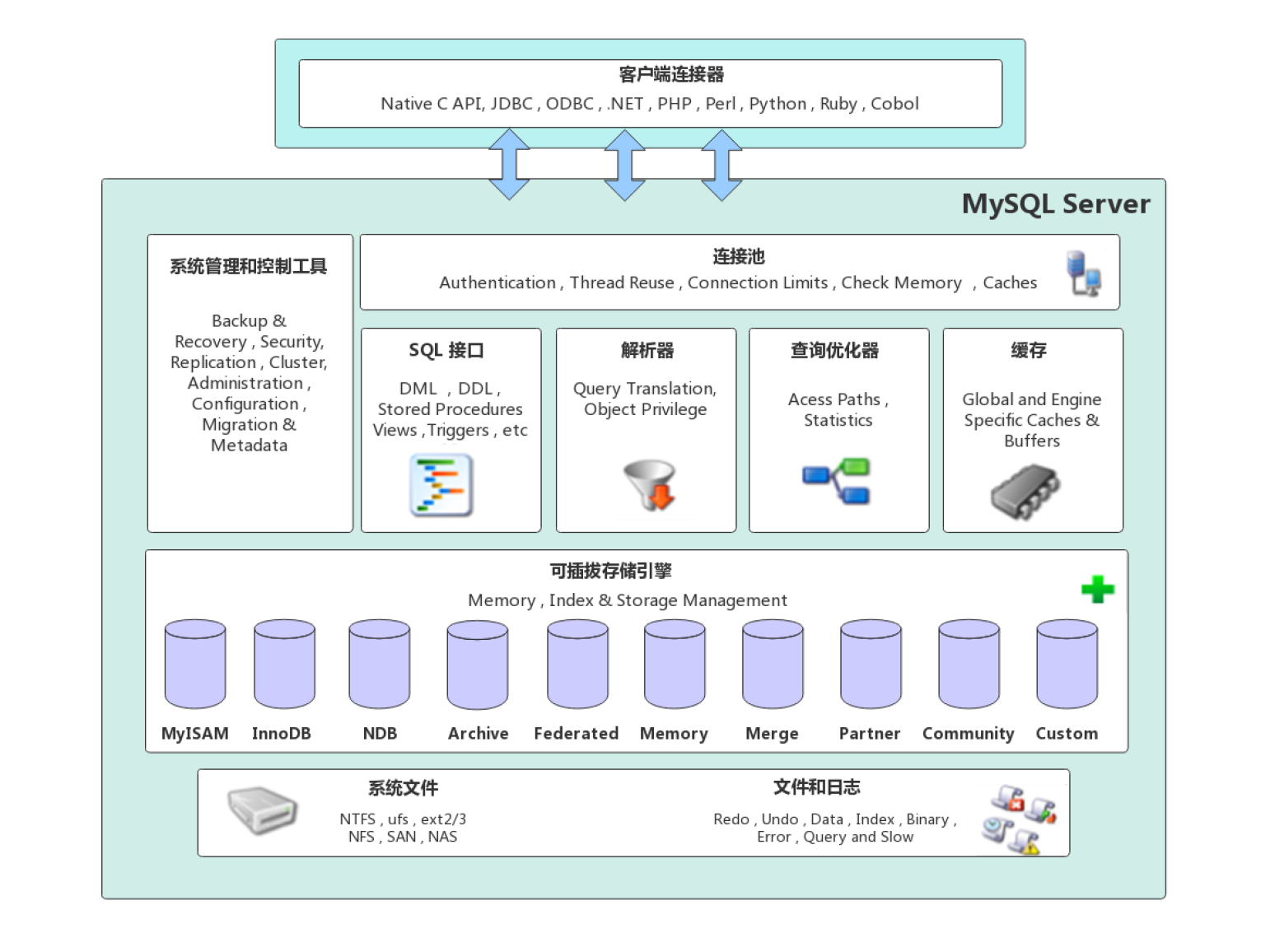
客户端连接器 【Connectors】
提供编程语言层级和MySQL交互的API接口,以及本地MySQL客户端程序和MySQL服务端连接交互
-
本地连接Socket方式:mysql -u用户名 -p密码 -S socket文件路径
-
TCP/IP远程连接:mysql -u用户名 -p密码 -h地址 -P端口
服务层【MySQL Server】 服务层是MySQL Server的核心,主要包含系统管理和控制工具、连接池、SQL接口、解析器、查询优化器和缓存六个部分
| 组件 | 功能 |
|---|---|
| 连接池(Connection Pool) | 负责存储和管理客户端与数据库的连接,一个线程负责管理一个连接 |
| 系统管理和控制工具(Management Services & Utilities) | 例如备份恢复、安全管理、集群管理等 |
| SQL接口(SQL Interface) | 用于接受客户端发送的各种SQL命令,并返回结果。比如DML、DDL、存储过程、视图、触发器等 |
| 解析器(Parser) | 负责将请求的SQL解析生成一个”解析树”。然后根据一些MySQL规则进一步检查解析树是否合法 |
| 查询优化器(Optimizer) | 当“解析树”通过解析器语法检查后,将交由优化器将其转化成执行计划,然后与存储引擎交互 |
| 缓存(Cache&Buffer) | 缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,权限缓存,引擎缓存等。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据 |
| 存储引擎层(Pluggable Storage Engines) | 储引擎负责MySQL中数据的存储与提取,与底层系统文件进行交互。MySQL存储引擎是插件式的,服务器中的查询执行引擎通过接口与存储引擎进行通信,接口屏蔽了不同存储引擎之间的差异 。现在有很多种存储引擎,各有各的特点,最常见的是MyISAM和InnoDB |
线程介绍
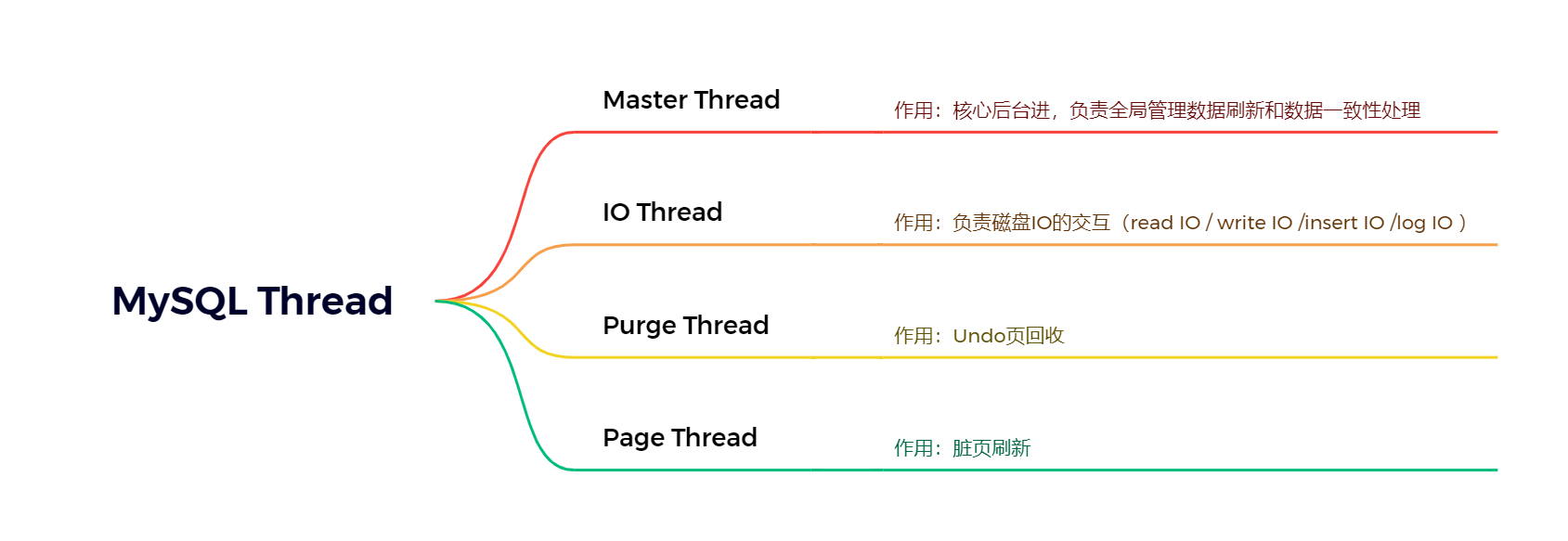
Master Thread
核心线程,负责缓冲池的数据异步入盘,包括脏页刷新、合并插入缓冲、undo页回收等
- 控制刷新脏页到磁盘(CKPT)
- 控制日志缓冲刷新到磁盘(log buffer –> redo)
- undo页回收
- 合并插入缓冲(change buffer)
- 控制IO刷新数量
参数说明:
-
innodb_io_capacity:表示每秒刷新脏页的数量,默认为200。 innodb_max_dirty_pages_pct:设置刷盘的脏页百分比,即当脏页占到缓冲区数据达到这个百分比时,就会刷新innodb_io_capacity个脏页到磁盘innodb_adaptive_flushing:自适应刷新MySQL根据当前运行信息绝对何时刷新,默认开启。回合innodb_max_dirty_pages_pct配合管理
IO Thread
在InnoDB存储引擎中大量使用Async IO来处理写IO请求,IO Thread的工作主要是负责这些IO请求的回调处理。写线程和读线程分别由innodb_write_threads和innodb_read_threads参数控制,默认都为4,使用show variables like '%innodb_%io_thread%';查看
Purge Thread
回收事务提交后不再需要的undo log,可以在配置文件中添加innodb_purge_threads=threadNum来开启独立的Purge Thread,等号后边控制该线程数量,默认为4个,通过show variables like '%innodb_purge_threads%'; 查看
Page clear thread
脏页的刷新操作,从master thread分离出来,减轻master thread的工作,提高性能
MySQL 8.0 Innodb结构
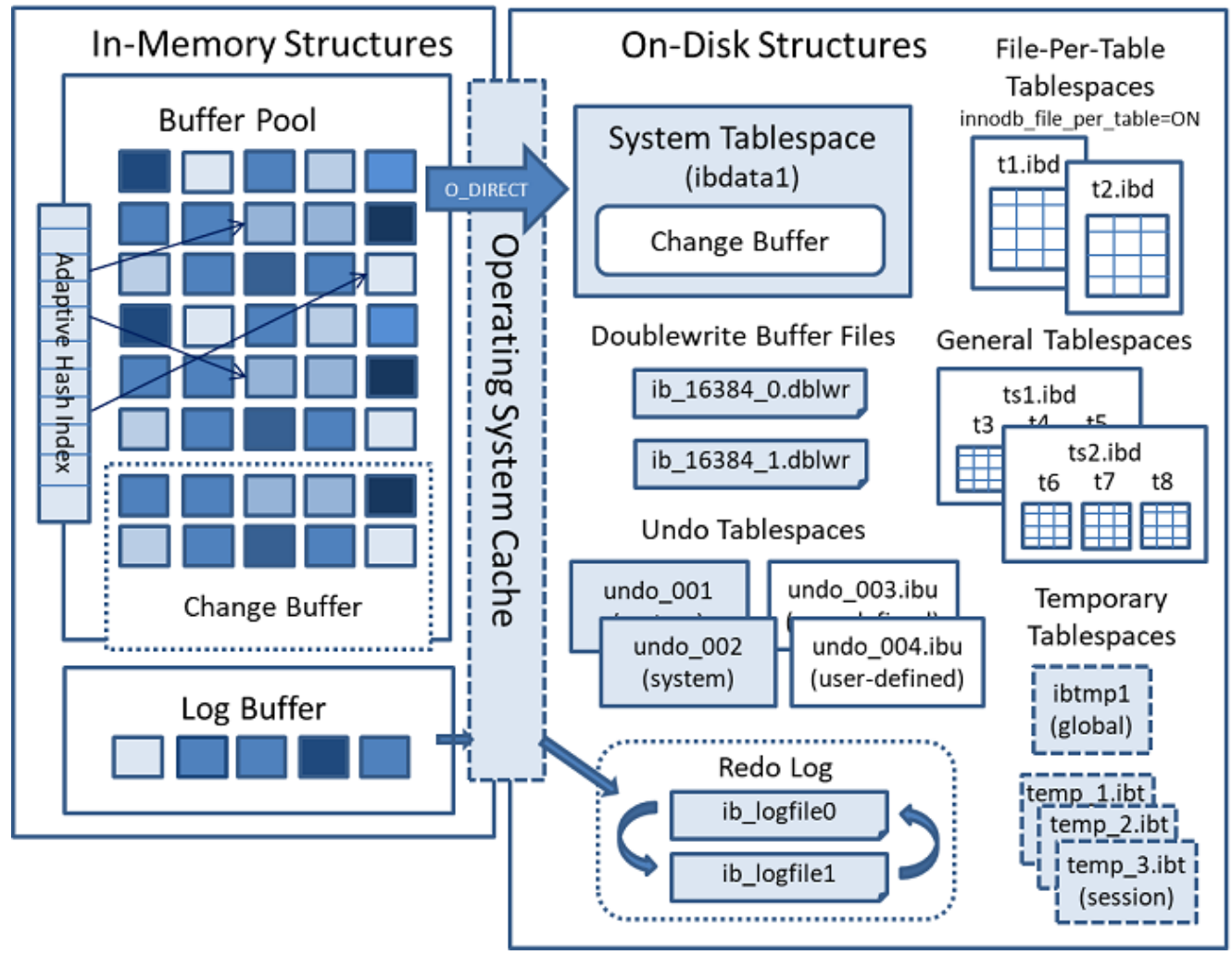
innodb buffer pool
查看MySQL的innodb_buffer_pool大小select @@innodb_buffer_pool_size/1024/1024; --单位M
Buffer Pool中存在三个双向链表。分别是FreeList、LRUList以及FlushList
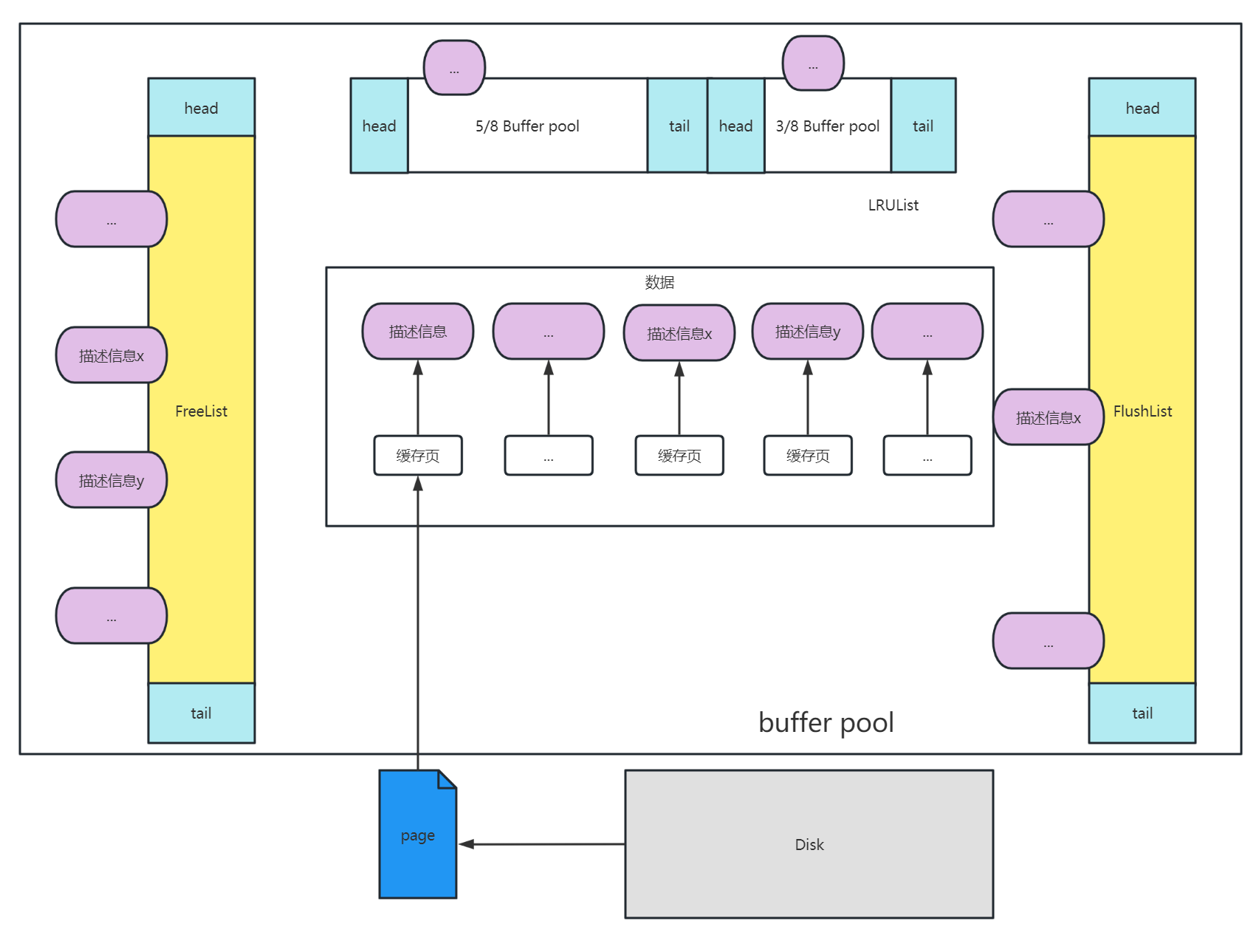
FreeList存放了空闲的缓存页的描述信息,即哪些区域是空闲状态,用于管理分配内存
LRUList冷热数据分离优化,5/8的区域是热数据区域,3/8的区域算是冷数据区域。新加载的数据页会被放在冷数据区的靠前的位置上。如果该数据页读取出来加载进缓存页中后,间隔没到1s,就使用该缓存页。那么是不会将这个描述信息移动到5/8的热数据区域的。但是当超过1s后,你又去读这个数据页。那这个数据页的描述信息就会被放到热数据区域。
FlushList中的节点存放的是被修改了脏数据页的描述信息块。随着MySQL被使用的时间越来越长,BufferPool的大小就越来越小。等它不够用的时候,就会将部分LRU中的数据页描述信息移除出去,这时如果发现被移除出来的数据页在FLushList中,就会触发fsync的操作,触发随机写磁盘。如果该数据页是干净的,那移除出去就好,不需要其它操作
change buffer
MySQL写的性能提升提升主要依赖change buffer,以前 change buffer称为insert buffer,因为以前只做了insert操作的性能优化,之后版本更新之后,也能对于修改和删除做缓存处理,所以改名为change buffer
例如:update xx set name = “赐我100w” where id = 5;【name是个非唯一的二级索引】
执行时不仅要更新聚簇索引,还要加载name这个辅助索引进行更新,如果现在name这个非唯一二级索引没有在内存中,将会进行IO操作,浪费性能。所以MySQL进行了改进:当这些二级索引页不在内存中时,对它们的操作会被缓存在change buffer中(目的是省去这次随机的磁盘IO)。等之后MySQL空闲了、或者是MySQL关闭前、或者是有读取操作时再将这部分缓存操作merge到B+Tree中
要求二级索引不能唯一。这个很好理解。如果name列是唯一的。那我每次DML之前都必须去看下有没有已经存在的相同值的索引。这也就意味着这个DML操作必须加载无法缓存
adaptive Hash Index
自适应哈希索引,InnoDB存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立自适应哈希索引,实现本质上就是一个哈希表:从某个检索条件到某个数据页的哈希表
Log Buffer
log buffer的作用是缓存redo log的写入操作,考虑到一个大事务,在事务期间可能会有很多次数据库操作,不需要在事务中的每一次操作都写入redo log,可以缓存一定量的redo log,在合适的时间进行写盘。
合适的时间取决于MySQL的配置(innodb_flush_log_at_trx_commit),值有0、1、2,默认是1
- 如果设置为0,每隔一秒把
log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。也就是说一秒之前的日志都保存在日志缓冲区,如果机器宕掉,可能丢失1秒的事务数据 - 如果设置为1,在每次事务提交的时候会把
log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。保证ACID - 如果设置为2,在每次事务提交的时候会把
log buffer刷到文件系统中去,但并不会立即刷写到磁盘
存储结构
文件存储结构(宏观)
表的存储结构(微观)
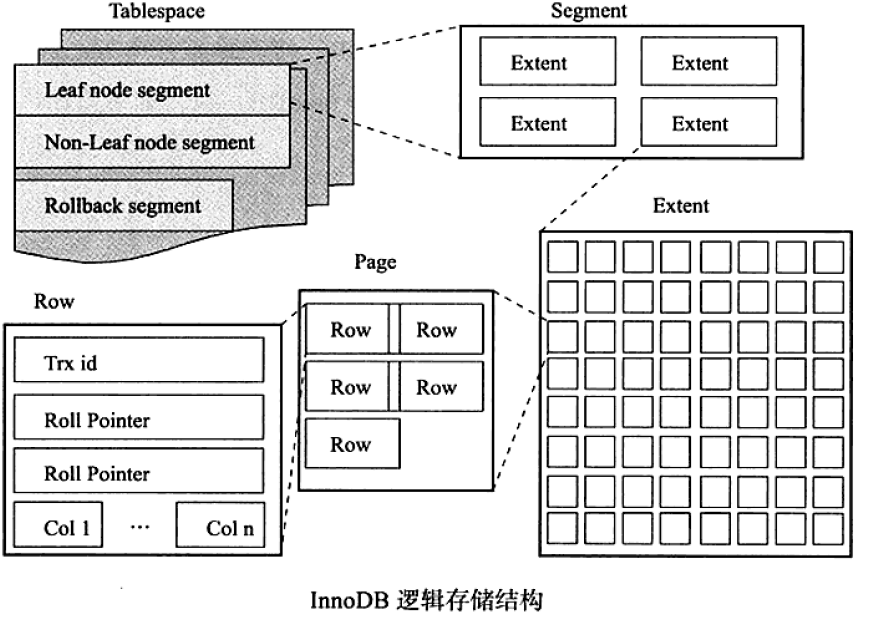
表抽象为表空间,表空间由segment、extend、page组成
Segment (段)
常见的segment有数据段、索引段、回滚段等, 数据段为B+树的叶子节点(Leaf node segment)、索引段为B+树的非叶子节点(Non-leaf node segment)
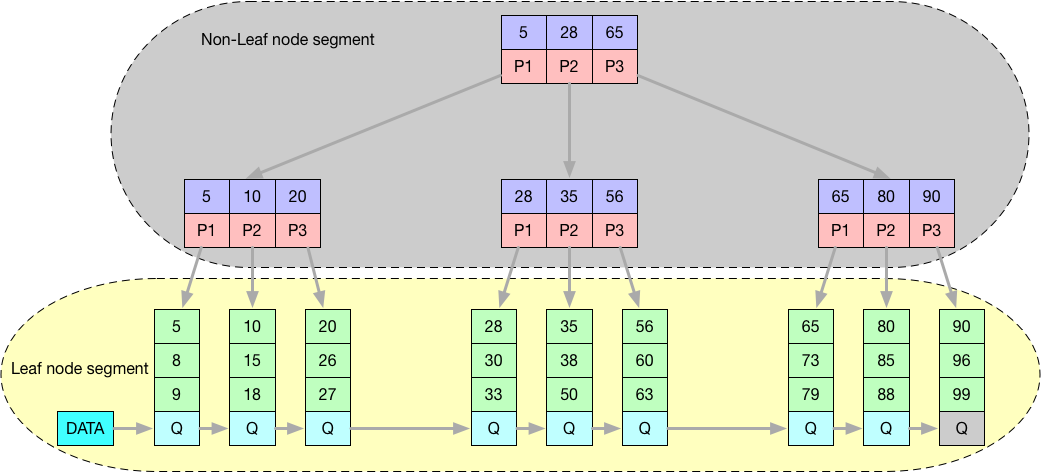
Extent(区、簇)
每个区大小固定为1MB,为保证区中page的连续性通常InnoDB会一次从磁盘中申请4-5个区。在默认page的大小为16KB的情况下,一个区则由64个连续的page组成
Page(数据页)
默认16KB。InnoDB最小的IO单元。MySQL有预读机制,就是当从磁盘上加载一个数据页的时候,可能会把这个它相邻的其他数据页也进行加载
系统库表介绍
MySQL 的数据字典 - information_schema
` information_schema`数据库保存着其他数据库的元信息
控制和管理信息库 - mysql
mysql库是MySQL 服务器的核心数据库,主要负责存储数据库的用户、权限、关键字等等
| 表名 | 介绍 |
|---|---|
| user | 用户信息、用户密码、针对所有库的权限 |
| db | 用户对某个数据库的操作权限信息 |
| tables_priv | 单个表进行权限设置时使用 |
| columns_priv | 单个数据列进行权限设置时使用 |
| procs_priv | 存储过程和存储函数进行权限设置 |
| slave_master_info | 主从信息存储的地方 |
| slave_relay_log_info | salve的中继日志信息 |
| slave_worker_info | slave的工作信息 |
| slow_log | 慢查询日志 |
服务器性能指标 - performance_schema
performance_schema是运行在较低级别的用于监控MySQL Server运行过程中的资源消耗、资源等待等情况
| 表名 | 介绍 |
|---|---|
| processlist | 当前连接信息 |
| threads | |
| events_statements_current | 当前语句事件表 |
| events_statements_history | 历史语句事件表 |
| events_statements_history_long | 长语句历史事件表 |
| summary 类表 | 聚合后的摘要表 |
DBA 的好帮手 - sys
sys库对information_schema和performance_schema统计的各种信息进行记录并生成新的视图表,通过 sys,我们可以快速的查询出:哪些语句使用了临时表、哪个线程占用了最多的内存、哪些索引是冗余的等等,sys库的功能需要单独配置开启
4、MySQL的日常管理
用户管理
-- 创建用户,MYSQL8.0的密码插件有更改,兼容不行(特别是主从),建议还是使用mysql_native_password
create user [用户名]@'[IP描述]' identified with mysql_native_password by '[密码]';
-- 查询用户
select user, host, plugin from mysql.user;
-- 删除用户
drop user [用户名]@'[IP描述]';
-- 修改用户密码
alter user [用户名]@'[IP描述]' identified with mysql_native_password by '[密码]';
-- 密码过期设置
select @@default_password_lifetime; -- 查看过期时间
ALTER USER [用户名]@'[IP描述]' PASSWORD EXPIRE INTERVAL [天数] DAY;
ALTER USER [用户名]@'[IP描述]' PASSWORD EXPIRE NEVER;
-- 锁定用户
ALTER USER [用户名]@'[IP描述]' ACCOUNT LOCK;
权限管理
-- 显示所有权限
show privileges;
-- 授予权限
GRANT 权限 ON 权限级别 TO 用户;
GRANT ALL ON *.* TO [用户名]@'[IP描述]'; -- 授予用户所有权限
GRANT select, update, delete, insert ON 数据库名称.* TO [用户名]@'[IP描述]'; -- 授予用户DML给指定数据库
-- 查看用户权限
SHOW GRANTS FOR [用户名]@'[IP描述]' ;
-- 回收权限
REVOKE 权限 ON *.* FROM [用户名]@'[IP描述]';
-- 角色创建及授权
CREATE ROLE [角色名]@'[IP描述]';
GRANT 权限 ON *.* TO [角色名]@'[IP描述]';
GRANT 角色名 TO [用户名]@'[IP描述]';
-- 查看角色和用户的映射关系
select * from mysql.role_edges;
-- 查看用户和角色的权限
select * from information_schema.user_privileges;
生产环境的权限分配
- 管理员:ALL
- 开发:create, create routine, create temporary tables, create view, show view, delete, event, execute, insert, references, select, trigger, update
- 监控:select, replication slave, replication client, super
- 备份:select, show databases, process, lock tables, reload
- 主从:replication slave, replication client
- 业务:insert, update, delete, select
5、MySQL系统的日志
日志类型
建议日志都设置到单独的文件夹,不要和数据目录混着
错误日志
默认位置:log_error=$DATDDIR/hostname.err,默认是开启的,看错误日志时主要关注 [ERROR],deadlock
log_error=/data/mysql80/log/mysql-err.log #错误日志路径
二进制日志(binlog)
记录了MySQL 发生过的修改的操作的日志。MySQL8.0 默认开启 binlog,默认在 datadir 文件夹内
①备份恢复必须依赖二进制日志;②复制环境必须依赖二进制日志
log_bin=/data/mysql80/log/mysql-bin #binlog日志路径
慢日志(slow_log)
记录MySQL工作中,运行较慢的语句。用来定位SQL语句性能问题,默认关闭,建议开启
slow_query_log=on # 开启慢查询日志
slow_query_log_file=/data/mysql80/log/mysql-slow.log # 慢查询日志位置
long_query_time=0.5 # 记录执行时间(real time)超过该值以上的SQL,默认值为10秒
log_queries_not_using_indexes=1 # 未使用索引的查询是否写入慢日志
log_throttle_queries_not_using_indexes=1000 # 限制每分钟所记录的slow log数量
也可用 set global 进行修改
普通日志(general_log)
普通日志,会记录所有数据库发生的事件及语句,文件信息较大,生成、测试都不建议打开,默认关闭
日志参数查询设置
show variables like 'log_output'; -- 看看日志输出类型 table或file
6、SQL知识相关
SQL_MODE
查看SQL_MODELselect @@sql_mode;
| SQL_MODE | Comments |
|---|---|
| ONLY_FULL_GROUP_BY | 对于GROUP BY聚合操作,如果在SELECT中的列、HAVING或者ORDER BY子句的列,没有在GROUP BY中出现,或者不在函数中聚合,那么这个SQL是不合法的 |
| STRICT_TRANS_TABLES | 严格模式,进行数据的严格校验,错误数据不能插入,报error错误。如果不能将给定的值插入到事务表中,则放弃该语句。对于非事务表,如果值出现在单行语句或多行语句的第1行,则放弃该语句 |
| NO_ZERO_IN_DATE | 在严格模式,不接受月或日部分为0的日期 |
| NO_ZERO_DATE | 在严格模式,不要将 ‘0000-00-00’做为合法日期 |
| ERROR_FOR_DIVISION_BY_ZERO | 在严格模式,在INSERT或UPDATE过程中,如果被零除(或MOD(X,0)),则产生错误(否则为警告) |
| NO_ENGINE_SUBSTITUTION | 如果需要的存储引擎被禁用或未编译,那么抛出错误 |
列的数据类型
数字类型-整型
| 类型 | 占用字节 | 无符号范围 | 有符号范围 | 数据长度 |
|---|---|---|---|---|
| tinyint | 1 | 0-255 | -128-127 | 3 |
| smallint | 2 | 0-65535 | -32768~32767 | 5 |
| mediumint | 3 | 0~16777215 | -8388608~8388607 | 8 |
| int | 4 | 0~2^32 | -2^31~ 2^32-1 | 10 |
| bigint | 5 | 0~2^64 | -2^63~ 2^63-1 | 20 |
解惑:int(11) 啥意思?不是长度已经一定了吗?
11 代表的并不是长度,而是字符的显示宽度,在无符号且填充零(
UNSIGNED ZEROFILL)下才有作用,例如:b INT(11) UNSIGNED ZEROFILL NOT NULL+-------------+ | b | +-------------+ | 00000000001 | | 01234567890 | +-------------+
数字类型-浮点型与定点数
建议:使用整形类型存储小数
- FLoat
Float:表示不指定小数位的浮点数
Float(M,D):表示一共存储M个有效数字,其中小数部分占D位
Float(10,2):整数部分为8位,小数部分为2位
- Double
Double又称之为双精度:系统用8个字节来存储数据,表示的范围更大,10^308次方,但是精度也只有15位左右
- Decimal
Decimal系统自动根据存储的数据来分配存储空间,每大概9个数就会分配四个字节来进行存储,同时小数和整数部分是分开的。
定点数:能够保证数据精确的小数(小数部分可能不精确,超出长度会四舍五入),整数部分一定精确
Decimal(M,D):M表示总长度,最大值不能超过65,D代表小数部分长度,最长不能超过30
字符串类型
-
Char(L)
系统一定会分配指定的空间用于存储数据,L取值范围0到255
-
Varchar(L)
变长字符:指定长度之后,系统会根据实际存储的数据长度和数据,所以每个varchar数据产生后,系统都会在数据后面增加1-2个字节的额外开销。如果数据本身小于255个字符:额外开销一个字节;如果大于255个,就开销两个字节
基本语法:Varchar(L),L的长度理论值位0到65535
如果数据长度超过255个字符,不论是否固定长度,都会使用text,不再使用char和varchar
-
长文本类型
Text:允许存放65535字节内的文字字符串字段类型
Mediumtext:允许存放16777215字节内的文字字符串字段类型
Longtext:允许存放2147483647字节内的文字字符串字段类型
时间类型
| 类型 | 占用字节 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期 |
| TIME | 3 | ‘-838:59:59’/’838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份 |
| DATETIME | 8 | 1000-01-01 00:00:00/ 9999-12-31 23:59:59 |
YYYY-MM-DD HH:MM:SS | 混合日期和时间 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/ 2038-1-19 11:14:07 |
YYYYMMDD | 时间戳 |
常用函数
字符函数
| 函数名 | 作用 | 示例 |
|---|---|---|
| length | 获取字节量,收到字符集影响 | length(‘abc’) |
| concat | 拼接字符串 | concat(‘%’, ‘abc’, ‘%’) |
| upper&lower | 转换大小写 | upper(‘abc’) |
| substr | 截取字符串 | substr(字符串,pos,[len]) |
| trim | 掐头去尾 | trim(‘ s ‘) |
| lpad&rpad | 左/右填充 | lpad(‘1’,2, 0) |
| replace | 替换 | replace(uuid(), ‘-‘, ‘’) |
数学函数
| 函数名 | 作用 | 示例 |
|---|---|---|
| round | 四舍五入 | round(3.1415, 2) |
| ceil | 向上取整 | ceil(3.14) |
| floor | 向下取整 | floor(9.99) |
| truncate | 小数点保留截断 | truncate(3.15, 1) |
| mod | 取模 | mod(10, 3) |
| rand | 生成(-∞, 0]范围内的随机整数 | rand()*10 |
日期函数
| 函数名 | 作用 | 示例 |
|---|---|---|
| now | 返回当前时间,类型DATETIME | now() |
| curdate | 返回日期,类型DATE | curdate() |
| curtime | 返回时间值,类型TIME | curtime() |
| current_timestamp | 返回时间戳,类型TIMESTAMP | current_timestamp() |
| month day hour minute second year |
截取时间信息 | year(now()) |
| str_to_date | 以指定格式识别日期 | str_to_date(‘2023-01-07 14:57:00’,’%y-%m-%d %h:%i:%s’) |
| date_format | 以指定字符串格式输出日期 | date_format(now(),’%y-%m-%d %h:%i:%s’) |
分组统计
| 函数名 | 作用 |
|---|---|
| sum | 数值型数据统计 |
| avg | 数值型数据平均值 |
| max | 任何类型数据最大值 |
| min | 任何类型数据最小值 |
| count | 非空值个数 |
| group_concat | 同一个分组中的值 |
流程控制函数
if函数,示例:
if(2>1, 'yes', 'no')
case函数,示例:
SELECT
CASE
110
WHEN 110 THEN '警察'
WHEN 119 THEN'消防队'
ELSE '其它号码'
END
7、索引&执行计划
SQL的执行流程
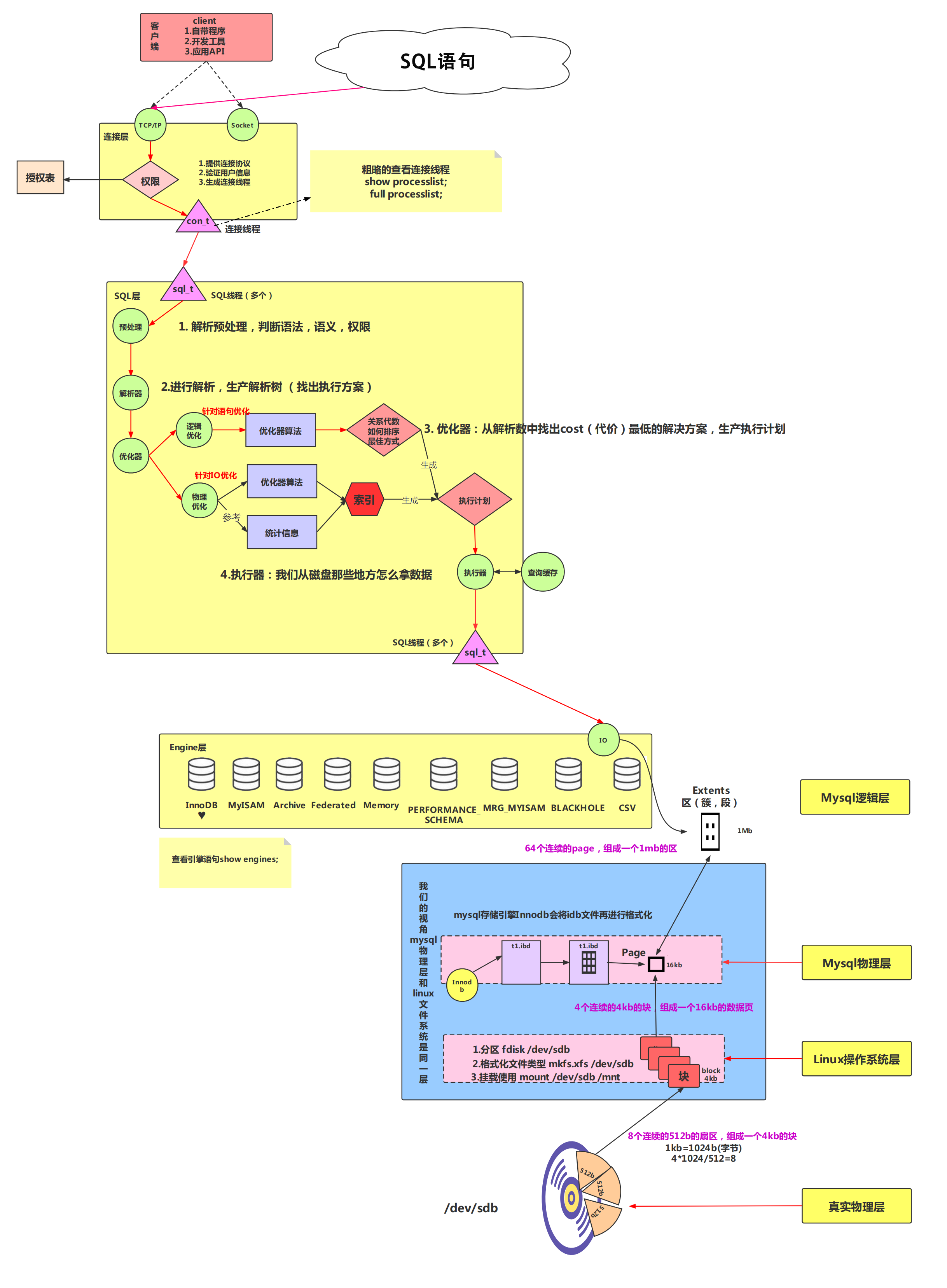
主要分为四个阶段:预处理、解析、优化、执行语句
预处理:判断语句中的语法、语义、权限处理等
解析 :校验OK,就生成“解析树”,把语句拆分成多个块,生成一种树形结构来表示执行顺序。解析出来的树叫抽像语法树AST
优化 :分为逻辑优化和物理优化。预估每条执行方式的成本,选择成本最小的执行方式,最终转化为执行计划explain
- 逻辑优化:将 SQL 语法树中的谓词转化为逻辑代数操作符,对条件表达式进行等价谓词重写、条件简化,对视图进行重写,对子查询进行优化,对连接语义进行了外连接消除、嵌套连接消除等
- 物理优化:统计信息(表的状态信息,比如表名、数据行、数据分布、索引状态信息)、选择索引和算法
执行 :根据执行计划去执行语句
索引
BTREE 查找算法演变
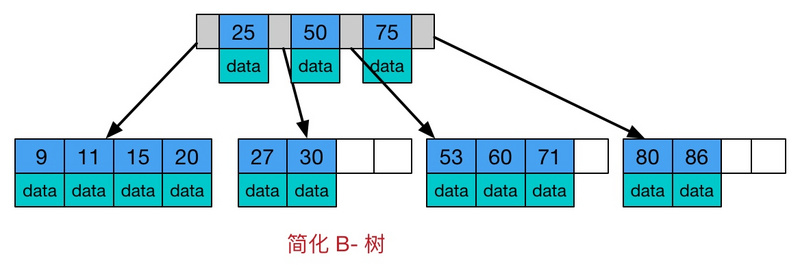
B-树有如下特点:
- 所有键值分布在整颗树中(索引值和具体data都在每个节点里)
- 任何一个关键字出现且只出现在一个结点中
- 搜索有可能在非叶子结点结束(最好情况O(1)就能找到数据)
- 在关键字全集内做一次查找,性能逼近二分查找
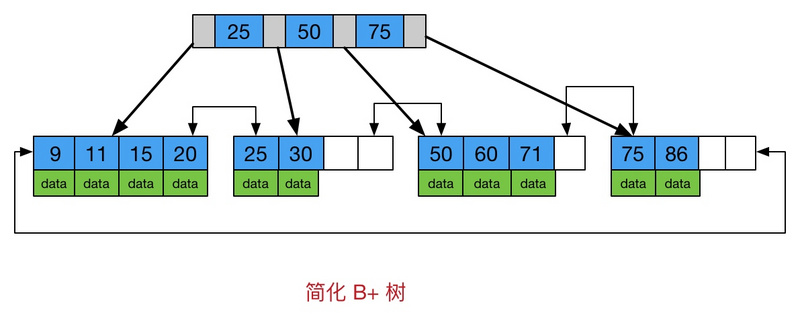
B+树有如下特点:
- 所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data)
- 为所有叶子结点增加了一个链指针
聚簇索引
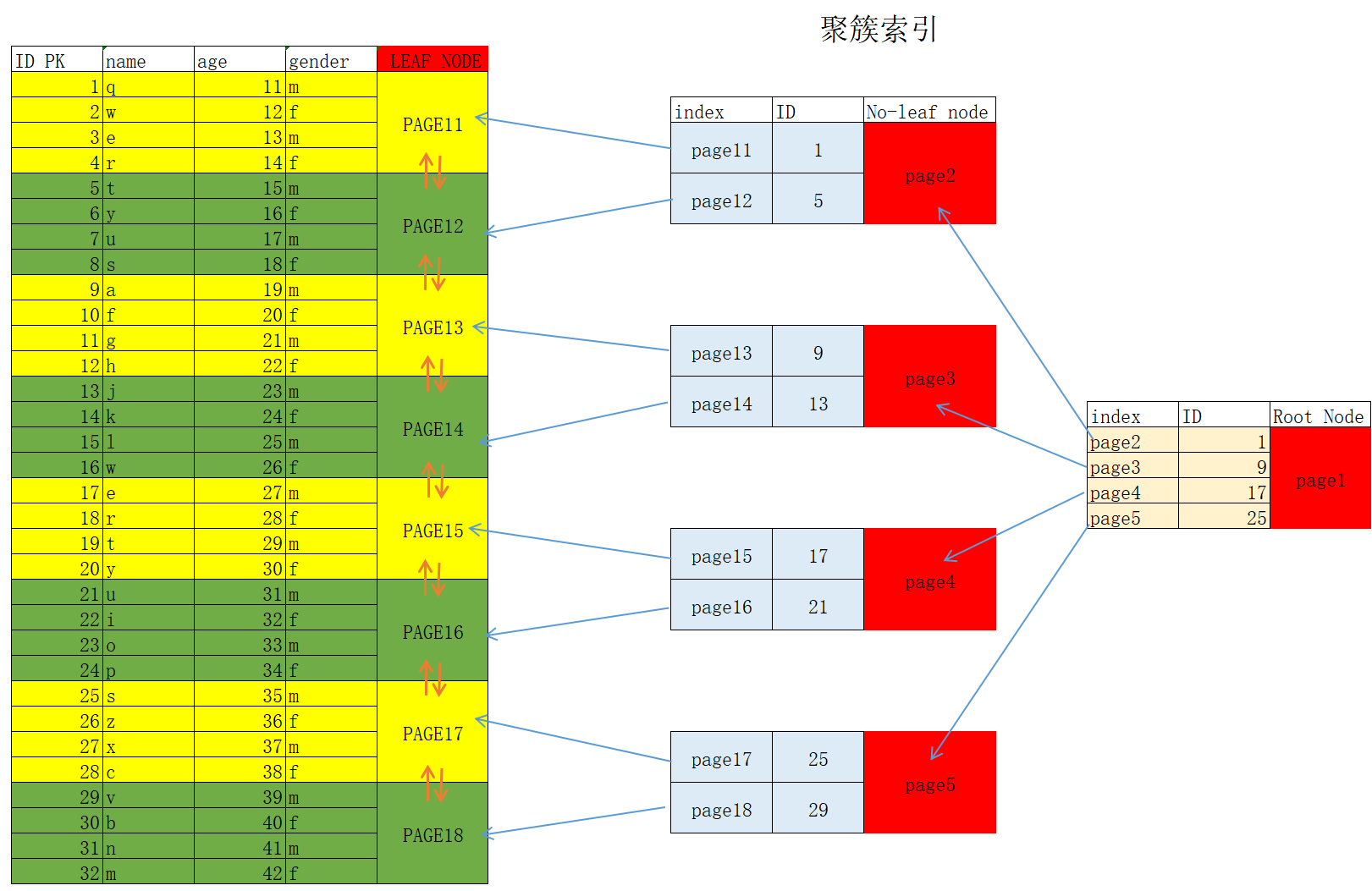
InnoDB表中一定是有聚簇索引的,聚簇索引的建立规则如下
1、 如果表中设置了主键(例如ID列),自动根据ID列生成聚簇索引
2、 如果没有设置主键,自动选择第一个非空唯一键的列作为聚簇索引
3、 自动生成隐藏(6字节row_id)的聚簇索引
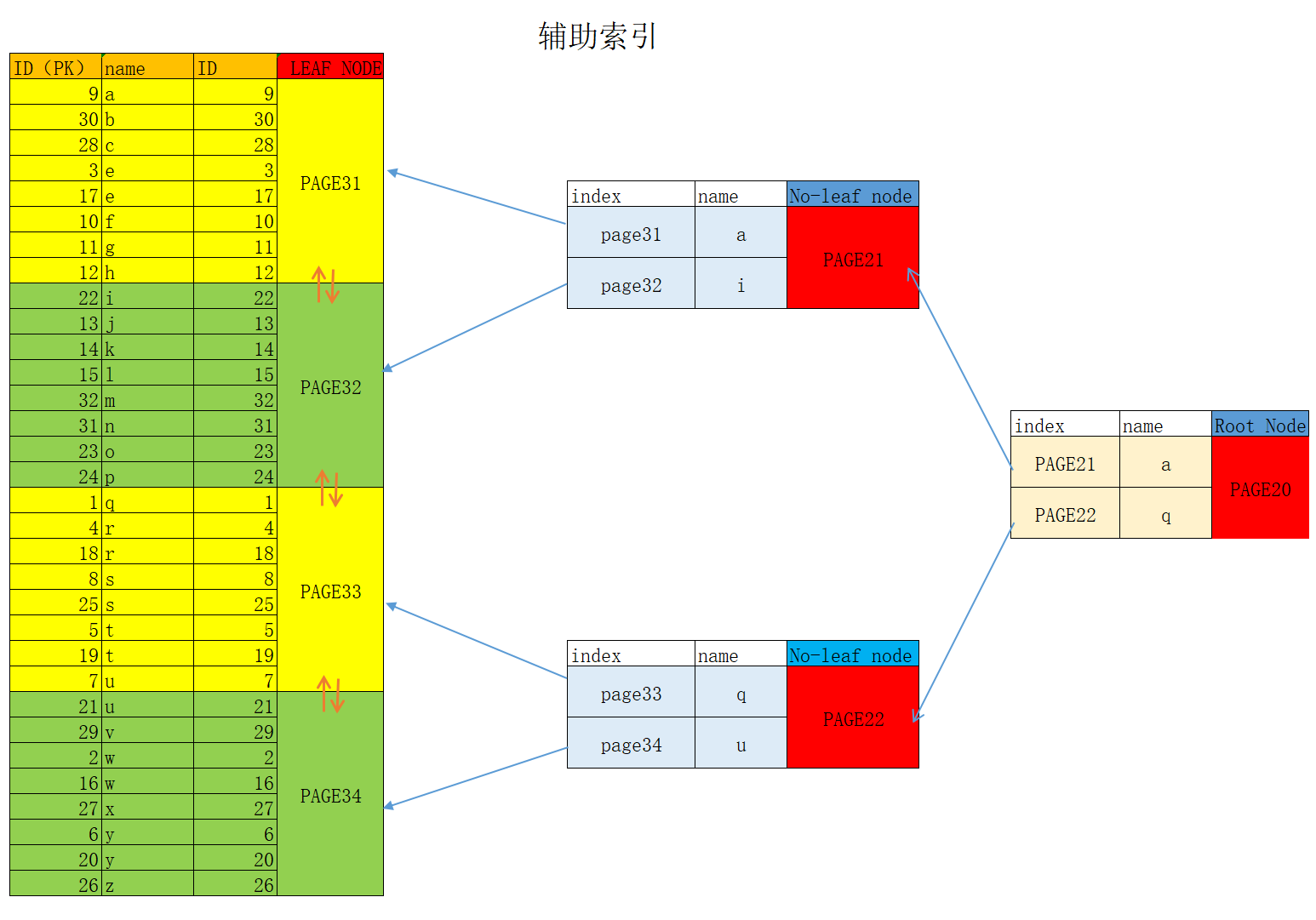
辅助索引
需要人为创建辅助索引,将经常作为查询条件的列创建辅助索引,起到加速查询的效果。叶子节点存储的是主键ID。使用辅助索引查出对应的主键ID,可能会用这些主键ID查询聚簇索引,这个过程叫做回表
执行计划
获取语句的执行计划工具,只针对索引应用和优化器算法应用部分信息,不会执行语句。
使用方式
explain/desc [formrt='json'/'tree'] SQL语句
执行计划信息介绍
-
id:查询的顺序,表示执行的顺序,id越大越先执行,id一样的从上往下执行
使用formrt=’tree’可更加直观看出执行顺序。从右到左,从上到下阅读
-
select_type:表示查询类型
值 描述 simple 表示不需要union操作或者不包含子查询的简单查询 primary 表示最外层查询 union union操作中第二个及之后的查询 dependent union union操作中第二个及之后的查询,并且该查询依赖于外部查询 subquery 子查询中的第一个查询 dependent subquery 子查询中的第一个查询,并且该查询依赖于外部查询 derived 派生表查询,既from字句中的子查询 materialized 物化查询 uncacheable subquery 无法被缓存的子查询,对外部查询的每一行都需要重新进行查询 uncacheable union union操作中第二个及之后的查询,并且该查询属于uncacheable subquery -
table:此次查询访问的表
-
partitions:分区信息,非分区表为null
-
type:查询时使用索引的类型
值 描述 ALL 没有使用到索引 index 全索引扫描,如果时聚簇索引列相当于全表扫描 range 索引范围扫描 ref 辅助索引等值查询 eq_ref 多表连接查询中,非驱动表的连接条件是主键或唯一键时 const / system 主键或唯一键等值查询 NULL 无需访问表或者索引 -
possible_keys:可能会应用的索引
-
key:最终选择的索引
-
key_len:用来判断联合索引应用的部分。值是真实字节数,如果不是非空约束列,记得要加1
format=json在used_key_parts字段上可以直观的看出
-
ref:表示连接查询的连接条件
-
rows:需要扫描的行数
-
filtered:某个表经过搜索条件过滤后剩余记录条数的百分比
-
Extra:额外信息,常见如下值
信息描述 解释 No tables used 当查询语句的没有 FROM 子句时将会提示该额外信息 Impossible WHERE 查询语句的 WHERE 子句永远为 FALSE 时将会提示该额外信息 Using index 索引覆盖的情况 Using index condition 有些搜索条件中虽然出现了索引列,但却不能使用到索引 Using where 全表扫描来执行对某个表的查询,并且该语句的 WHERE 子句中有针对该表的搜索条件时 Using filesort 用到了索引做排序 Using temporary 使用了临时表
优化器针对索引的算法
优化器算法及开启状态查询
select @@optimizer_switch;
索引下推(index_condition_pushdown,ICP)
作用:根据表数据分析,联合索引尽可能的多过滤数据,减少回表
原理:下推到引擎层过滤
例如:联合索引(a, b, c),执行查询条件 “ where a = and b > and c = “
SQL层做完过滤后,联合索引(a, b, c)只能用(a, b)部分,索引下推可将c列条件的过滤下推到engine层,进行再次过滤,排除无用的数据页,最终去磁盘上拿数据页
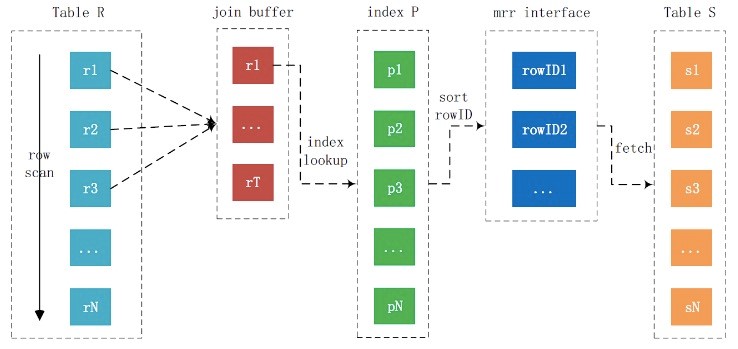
索引多范围查找(Multi Range Read,MRR)
作用:减少对磁盘的随机访问,进而对基表执行更多的顺序扫描
原理:由于MySQL 辅助索引的存储顺序并非与主键的顺序一致,所以根据辅助索引获取的主键来访问表中的数据会导致随机的IO。MRR将多个需要回表的二级索引根据主键进行排序,然后一起回表,将原来的回表时进行的随机IO,转变成顺序IO
表连接算法
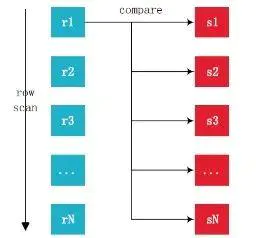
普通嵌套循环连接(Simple Nested-Loops Join,SNLJ)
优化器自动选择结果集小的表作为驱动表。对于两表连接,驱动表只会被访问一遍,被驱动表具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。这种驱动表只访问一次,但被驱动表却可能被多次访问的连接执行方式称之为嵌套循环连接。
可以用
left join强制驱动表
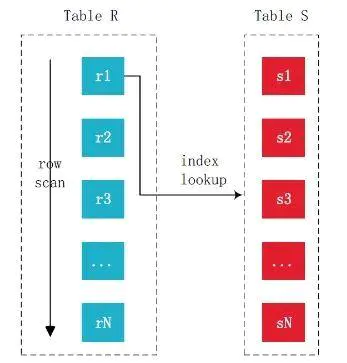
索引嵌套循环连接(Index Nested Loops Join, INLJ)
有一方在连接字段上有索引,优化器会考虑选择有索引的一方作为被驱动表,双方都有索引则选择索引高度低的,索引高度一样则选择记录数多的作为被驱动表,对于驱动表的每一条记录,在被驱动表中使用索引查询,大大减少了比较次数,提高了查询效率
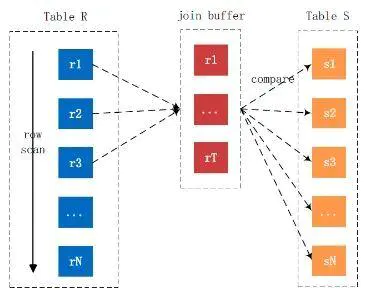
基于块的嵌套循环连接(Block Nested-Loop Join,BNL)
被驱动表要被访问好多次,如果被驱动表中的数据特别多而且不能使用索引访问的话,那就相当于从磁盘上读好多次这个表,这个IO代价就非常大,所以应该尽量减少访问被驱动表的次数。
在嵌套循环连接中,驱动表查询结果集中有多少条记录,就需要驱动表数据被加载多少次来进行匹配,那可不可以把被驱动表的记录加载到内存的时候,一次性和多条驱动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了。
所以提出可join buffer的概念,join buffer就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后扫描被驱动表,每一条被驱动表的记录一次性和join buffer中的多条驱动表记录进行匹配,因为匹配的过程是在内存中完成的,所以这样可以减少被驱动表的IO代价。
批量键访问联接(Batched Key Access Join,BKA)
当被驱动表的链接字段有非主键索引时,通过范围扫描读取一部分记录放入内存中,然后按照主键排序,这样匹配到数据后需要按对应的主键索引去查询被驱动表的真实数据时,可以按照排好序的主键进行顺序访问。相当于(BNL + MRR)
哈希连接(Hash Join)
Hash Join被应用的条件是那些不走索引,或者索引应用不好的时候。
Hash Join 包含两个部分:build构建阶段和probe探测阶段
SELECT persons.name, countries.country_name FROM persons JOIN countries ON persons.country_id = countries.country_id;
build 阶段
遍历驱动表,以join条件为key(countries.country_id),查询需要的列作为value(countries.country_id,countries.country_name)创建hash表。
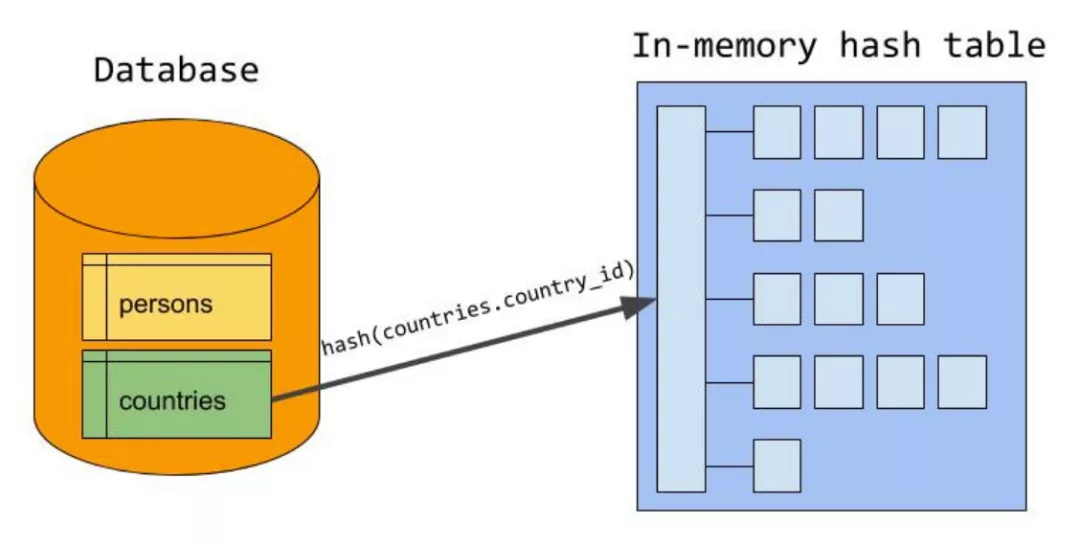
案例中对 countries.country_id 进行 hash 计算:hash(countries.country_id) 然后将值放入内存中 hash table 的相应位置。countries 表中的所有 country_id 都放入内存的哈希表中
probe 探测阶段
build阶段完成后,MySQL逐行遍历被驱动表,然后计算 join条件的hash值,并在hash表中查找,如果匹配,则输出给客户端,否则跳过。所有内表记录遍历完,则整个过程就结束了。
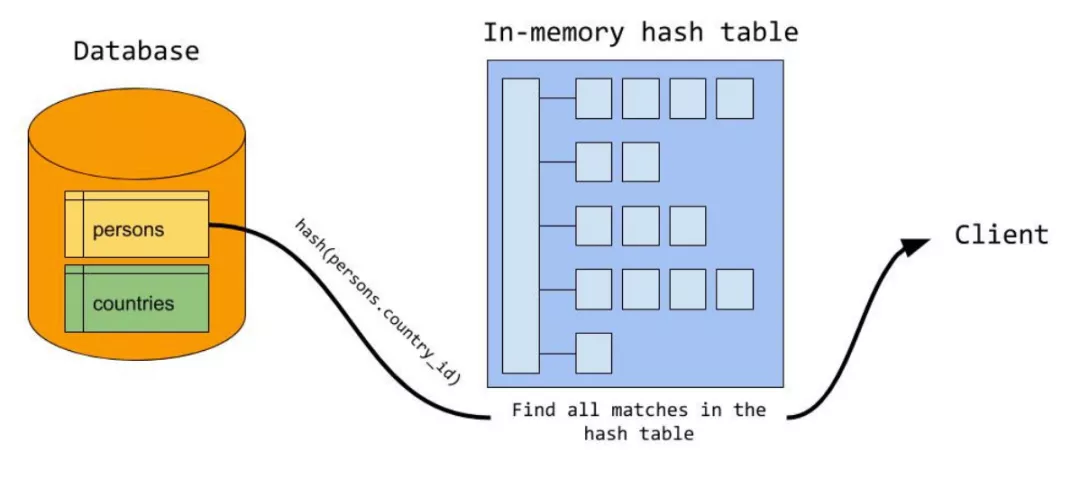
如图所示 ,MySQL 对 persons 表中每行中的 join 字段的值进行 hash 计算;hash(persons.country_id),拿着计算结果到内存 hash table 中进行查找匹配
如果驱动表的数据记录在内存中存不下时就会利用磁盘文件。此时MySQL 要构建临时文件做hash join。此时的过程如下:
-
build阶段会首先利用hash算将外表进行分区,并产生临时分片写到磁盘上
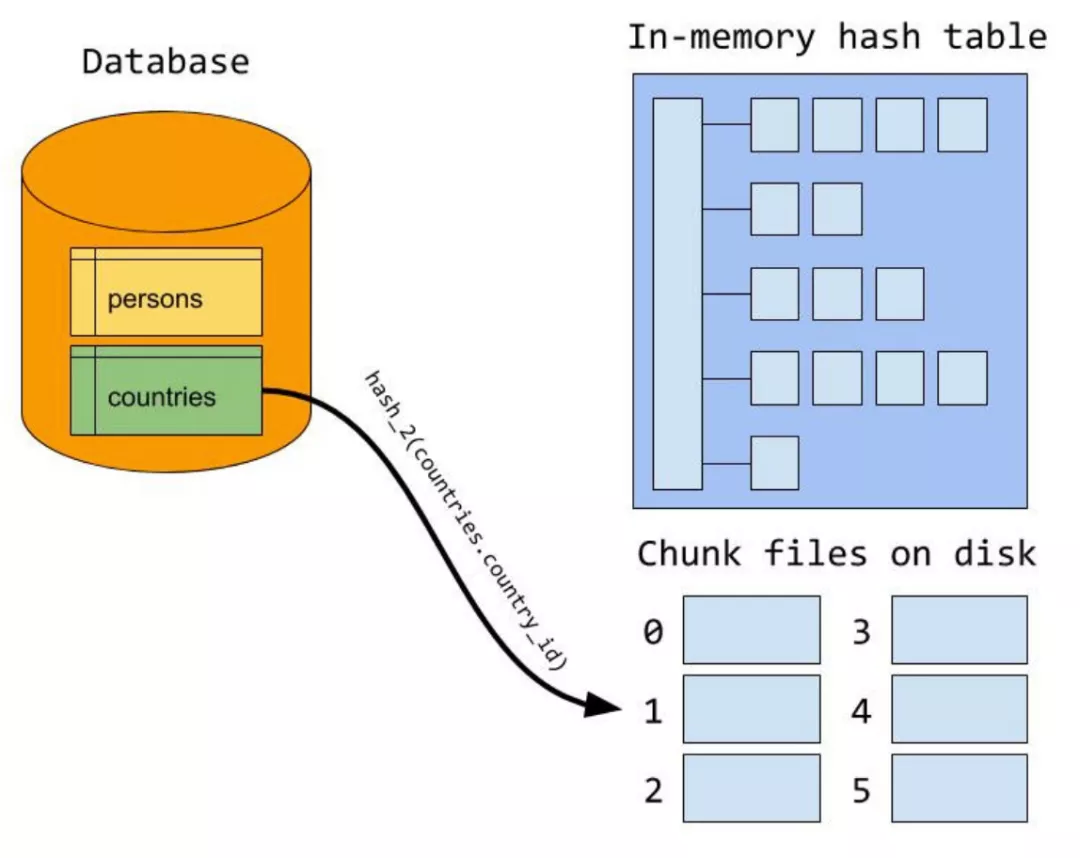
-
然后在probe阶段,对于内表使用同样的hash算法进行分区
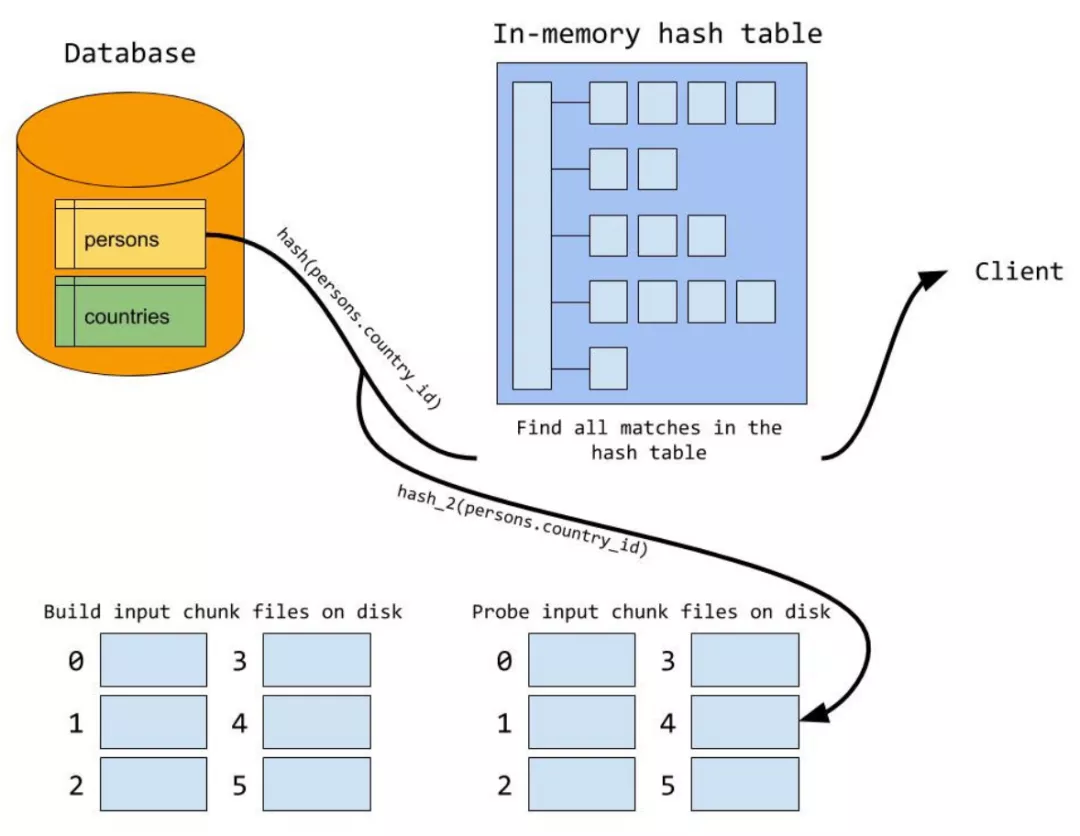
-
由于使用分片hash函数相同,那么key相同(join条件相同)必然在同一个分片编号中。接下来,再对外表和内表中相同分片编号的数据进行内存hash join的过程,所有分片的内存hash join做完,整个join过程就结束了
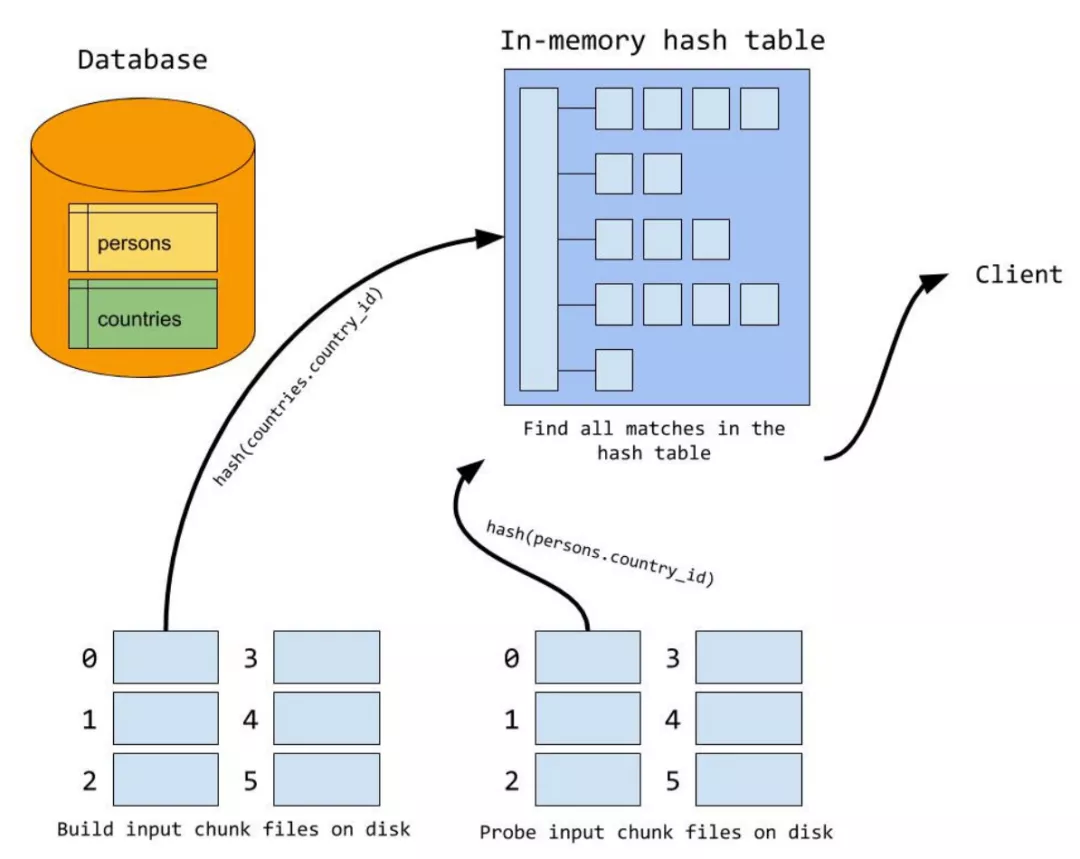
可以调整join_buffer_size和open_files_limit参数提高性能
8、InnoDB 存储引擎
核心特性总览
- MVCC: 多版本并发控制
- 聚簇索引 : 用来组织存储数据和优化查询
- 支持事务 : 数据最终一致提供保证
- 支持行级锁 : 并发控制
- 外键 : 多表之间的数据一致一致性
- 多缓冲区支持
- 自适应Hash索引: AHI
- 复制中支持高级特性
- 备份恢复: 支持热备
- 自动故障恢复:CR Crash Recovery
- 双写机制 : DWB Double Write Buffer
存储引擎的管理
查看碎片情况
-- 查看某个数据库下的碎片情况
select table_name,data_free,engine from information_schema.tables where table_schema='[数据库名称]';
整理碎片
-- 以下两个操作相当于重新生成表,并更新统计信息
alter table 表名 engine=InnoDB;
analyze table 表名;
-- 对数据表优化
optimize table 表名;
查询线程信息
-- 前台线程查询(连接层)
show processlist ;
show full processlist;
select * from information_schema.processlist;
-- 后台线程(Server\Engine)
select * from performance_schema.threads;
-- 查询连接线程和SQL线程关系
select * from information_schema.processlist ; ---> ID=10
select * from performance_schema.threads where processlist_id=10;
select * from performance_schema.events_statements_history where thread_id=?
表空间
表空间的分类
- system tablespace(系统表空间/共享表空间)
- file-per-table tablespace(独立表空间)
- undo tablespace(undo 表空间)
- temp tablespace(临时表空间)
system tablespace(系统表空间/共享表空间)
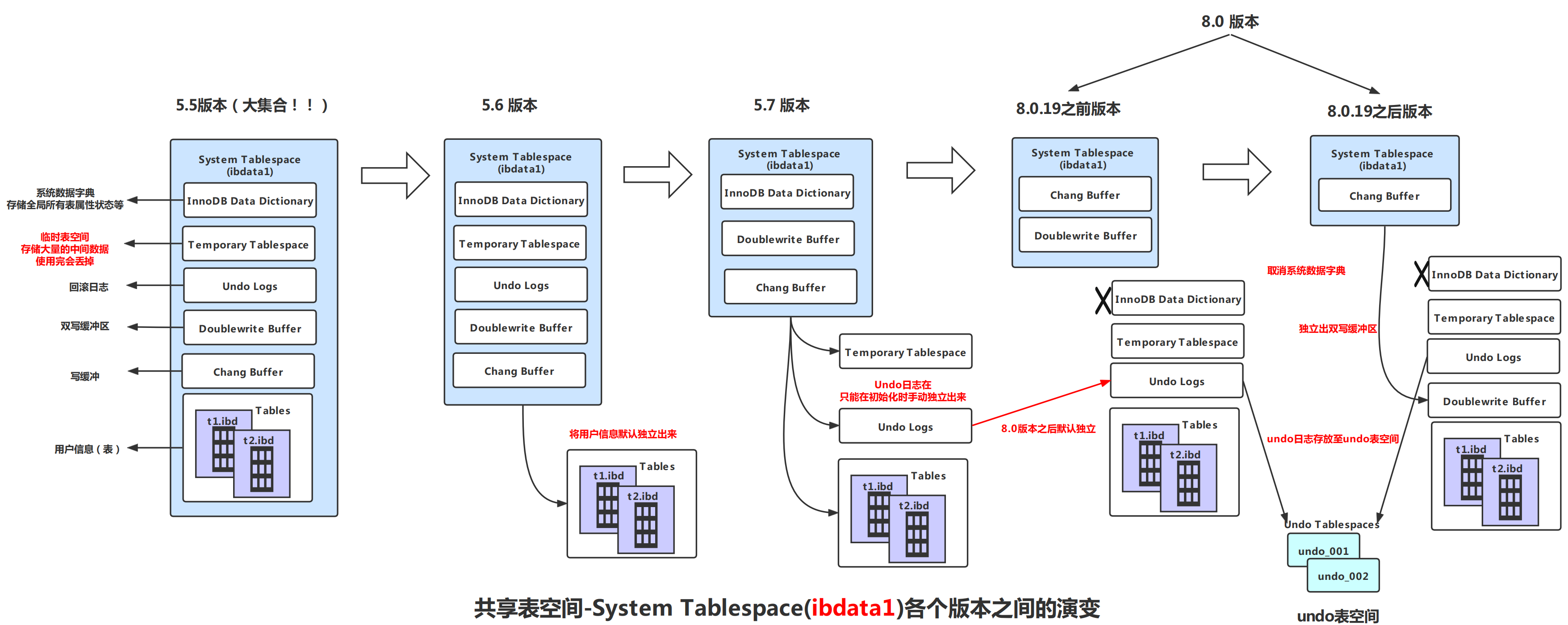
查询共享表空间信息
select @@innodb_data_file_path;默认(ibdata1:12M:autoextend)
select @@innodb_autoextend_increment;默认64M
即ibdata1文件,默认初始大小12M,不够用会自动扩展,默认每次扩展64M。不建议使用默认大小,并发太小
# 如果已经初始化,第一个大小必须和硬盘中的第一个文件实际大小一致,否则会报错
innodb_data_file_path=ibdata1:1024M;ibdata2:1024M:autoextend
5.7 中建议:设置共享表空间2-3个,大小建议512M或者1G,最后一个定制为自动扩展。
8.0 中建议:设置1-2个就ok,大小建议512M或者1G
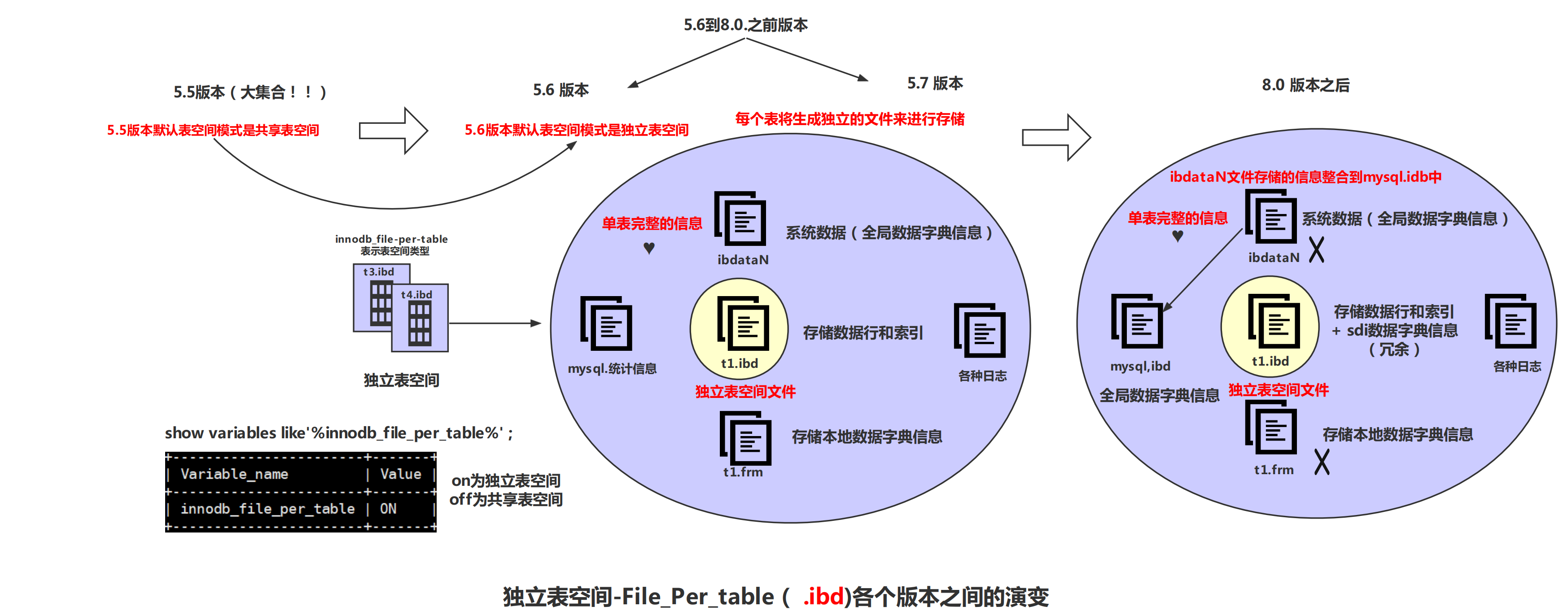
file-per-table tablespace(独立表空间)
每个表的表空间包含单个 InnoDB表的数据和索引,并存储在文件系统上的单个数据文件中。MySQL每创建一个表,就会生成一个独立表空间以 table_name.idb 命名的。
undo tablespace(undo 表空间)
用作撤销日志,回滚日志
5.7版本,默认存储在共享表空间中(ibdataN);8.0版本以后默认就是独立的(undo_001-undo_002)
SELECT @@innodb_undo_tablespaces; -- 打开独立undo模式,并设置undo的个数,建议3-5个
SELECT @@innodb_max_undo_log_size; -- undo日志的大小,默认1G。
SELECT @@innodb_undo_log_truncate; -- 开启undo自动回收的机制(undo_purge)。
SELECT @@innodb_purge_rseg_truncate_frequency; -- 触发自动回收的条件,单位是检测次数。
temp tablespace(临时表空间)
把临时表的数据从系统表空间中抽离出来,形成独立的表空间参数innodb_temp_data_file_path,独立表空间文件名为 ibtmp1,默认大小 12MB。建议进行修改。
# 建议数据初始化之前设定好,一般2-3个,大小512M-1G
innodb_temp_data_file_path=ibtmp1:512M;ibtmp2:512M:autoextend:max:512M
行格式
CREATE TABLE record_format_demo (
c1 VARCHAR (10),
c2 VARCHAR (10) NOT NULL,
c3 CHAR(10),
c4 VARCHAR(10)) CHARSET=ascii ROW_FORMAT = COMPACT;
-- 记录1
INSERT INTO record_format_demo(c1, c2, c3, c4) VALUES('aaaa', 'bbb', 'cc', 'd');
-- 记录2
INSERT INTO record_format_demo(c1, c2, c3, c4) VALUES('eeee', 'fff', NULL, NULL);
COMPACT行格式
一条完整的记录其实可以被分为记录的额外信息和记录的真实数据两大部分

记录的额外信息:为了描述这条记录而不得不额外添加的一些信息,这些额外信息分为3类,分别是变长字段长度列表、NULL值列表和记录头信息
-
变长字段长度列表
所有变长字段的真实数据占用的字节长度都存放在记录的开头部位,从而形成一个变长字段长度列表,各变长字段数据占用的字节数按照列的顺序逆序存放,变长字段长度列表中只存储值为 非NULL 的列内容占用的长度,值为 NULL 的列的长度是不储存的

-
NULL值列表
表中如果没有允许存储 NULL 的列,则 NULL值列表也不存在了。否则将每个允许存储NULL的列对应一个标记【1-NULL,0-Not NULL】,标记位按照列的顺序逆序排列。NULL值列表必须用整数个字节的位表示,如果使用的二进制位个数不是整数个字节,则在字节的高位补0

-
记录头信息
由固定的5个字节组成。5个字节也就是40个二进制位,不同的位代表不同的意思

名称 大小(bit) 描述 预留位1 1 没有使用 预留位2 1 没有使用 delete_mask 1 标记该记录是否被删除 min_rec_mask 1 B+树的每层叶子节点中的最小记录都会添加该记标记 n_owned 4 表示当前记录拥有的记录数 heap_no 13 表示当前记录在记录堆的位置信息 record_type 3 表示当前记录的类型,0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录 next_record 16 表示下一条记录的相对位置
记录的真实数据:除了报错了自己定义列的存储数据以外,MySQ还L会为每个记录默认的添加一些列(也称为隐藏列),具体的列如下
| 列名 | 是否必须 | 占用空间(单位:B) | 描述 |
|---|---|---|---|
| DB_ROW_ID | 否 | 6 | 行ID,唯一标识一条记录 |
| DB_TRX_ID | 是 | 6 | 事务ID |
| DB_ROLL_PTR | 是 | 7 | 回滚指针 |

DYNAMIC和COMPRESSED行格式
默认存储格式是DYNAMIC,这俩行格式和Compact行格式挺像,只不过在处理行溢出数据时有点儿分歧,它们不会在记录的真实数据处存储字段真实数据的前768个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址。Compressed行格式和Dynamic不同的一点是,Compressed行格式会采用压缩算法对页面进行压缩,以节省空间。
页结构
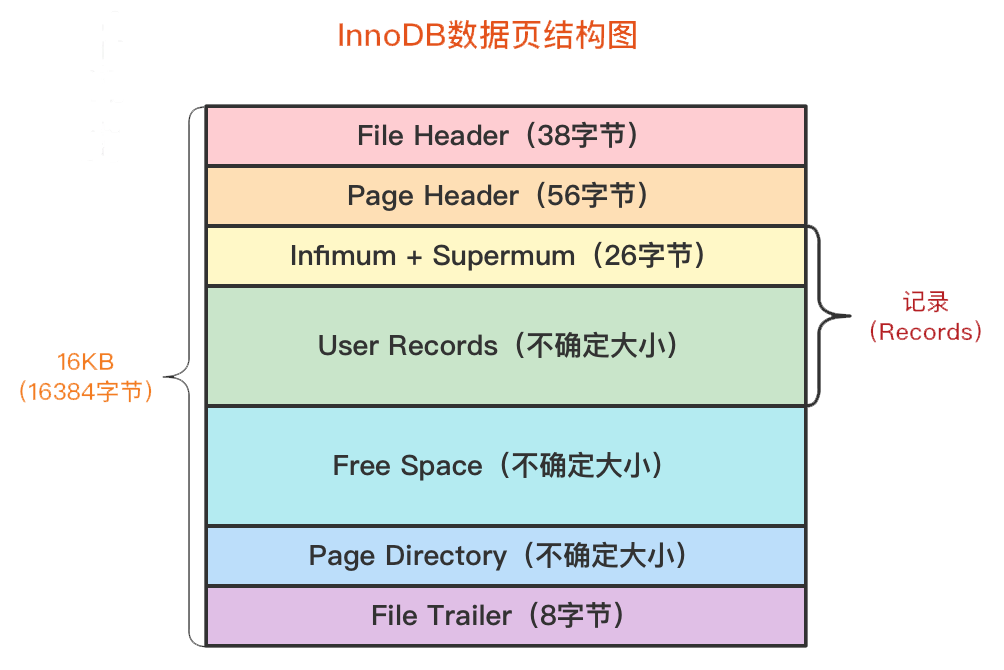
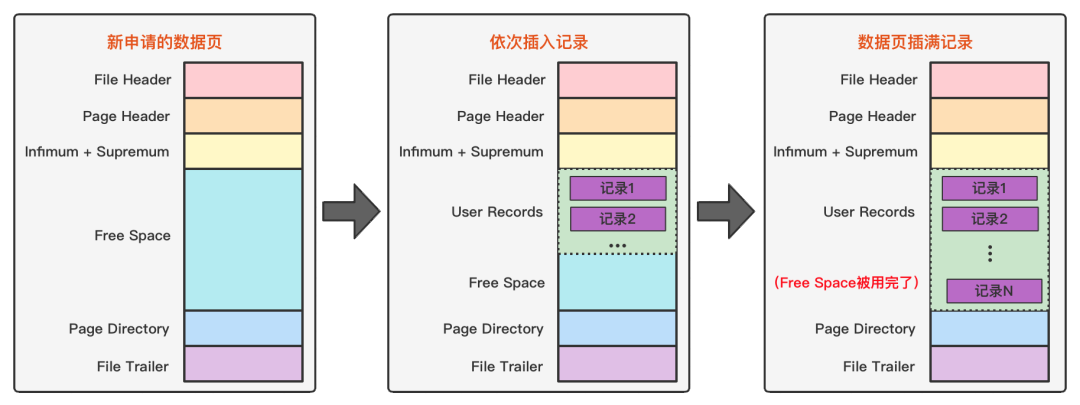
页中使用/未使用空间(User Records / Free Space)
开始生成页的时候,其实并没有User Records这个部分,每当我们插入一条记录,都会从Free Space部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到User Records部分,当Free Space部分的空间全部被User Records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了
最小记录和最大记录(Infimum+Supremum)
Infimum和Supremum本质上就是两条数据行,只不过是虚拟的。Infimum记录(也就是最小记录) 的next_record记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的next_record记录就是Supremum记录(也就是最大记录)
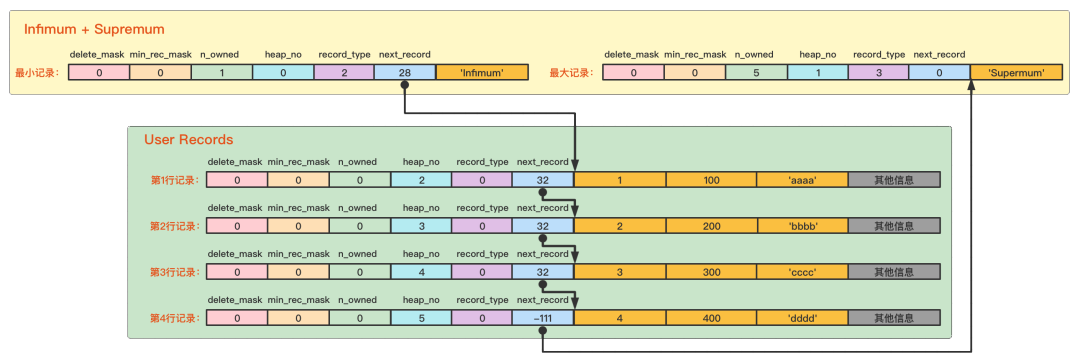
InnoDB会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的
当数据页中存在多条被删除掉的记录时,这些记录的next_record属性将会把这些被删除掉的记录组成一个垃圾链表,以备之后重用这部分存储空间。上面删除了一行记录,又将记录原封不动插回来的情况,原来的存储空间是会被重用的。
还有一种情况是不会被重用的:删除原记录后,新插入的记录真实数据所占存储空间大于原先记录存储空间的时候,这时原空间不会被重用且被加入垃圾链表,新插入的记录会从Free Space申请新的空间,和已有的记录组合成新的链表。
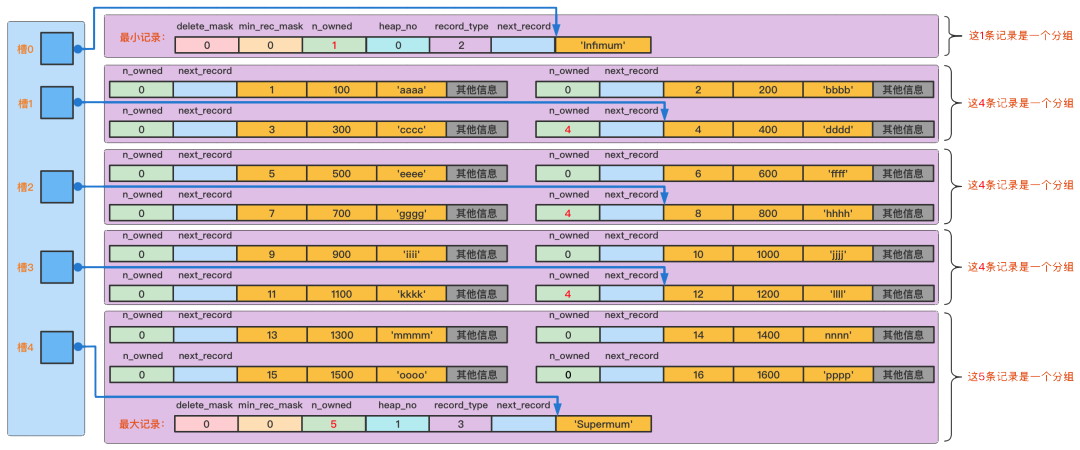
页目录(Page Directory)
做出页目录结构,用于在页内快速定位数据
- 将所有正常的记录(包括最大和最小记录,不包括标记为已删除的记录)划分为几个组,有点类似与跳表思想
- 每个组的最后一条记录(也就是组内最大的那条记录)的头信息中的n_owned属性表示该记录拥有多少条记录,也就是该组内共有几条记录
- 将每个组的最后一条记录的地址偏移量单独提取出来按顺序存储到靠近页的尾部的地方,这个地方就是所谓的Page Directory,也就是页目录。页面目录中的这些地址偏移量被称为槽(Slot),所以这个页面目录就是由槽组成的
页面头部(page Header)
InnoDB为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫Page Header的部分
| 名称 | 大小(Byte) | 描述 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | 页目录的插槽数 |
| PAGE_HEAP_TOP | 2 | 还未使用的空间最小地址,也就是说从该地址之后就是Free Space |
| PAGE_N_HEAP | 2 | 本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
| PAGE_FREE | 2 | 第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
| PAGE_GARBAGE | 2 | 已删除记录占用的字节数 |
| PAGE_LAST_INSERT | 2 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2 | 记录插入的方向 |
| PAGE_N_DIRECTION | 2 | 一个方向连续插入的记录数量 |
| PAGE_N_RECS | 2 | 页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
| PAGE_MAX_TRX_ID | 8 | 修改当前页的最大事务ID,该值仅在二级索引中定义 |
| PAGE_LEVEL | 2 | 当前页在B+树中所处的层级 |
| PAGE_INDEX_ID | 8 | 索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF | 10 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
| PAGE_BTR_SEG_TOP | 10 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |
文件头部(File Header)
File Header是针对各种类型的页都通用数据部分,也就是说不同类型的页都会以File Header作为第一个组成部分,它描述了一些针对各种页都通用的一些信息,比方说这个页的编号是多少,它的上一个页、下一个页是谁等信息,这个部分占用固定的38个字节,是由下边这些内容组成的
| 名称 | 大小(Byte) | 描述 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 | 页的校验和(checksum值) |
| FIL_PAGE_OFFSET | 4 | 页号 |
| FIL_PAGE_PREV | 4 | 上一个页的页号 |
| FIL_PAGE_NEXT | 4 | 下一个页的页号 |
| FIL_PAGE_LSN | 8 | 页面被最后修改时对应的日志序列位置 |
| FIL_PAGE_TYPE | 2 | 该页的类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 | 页属于哪个表空间 |
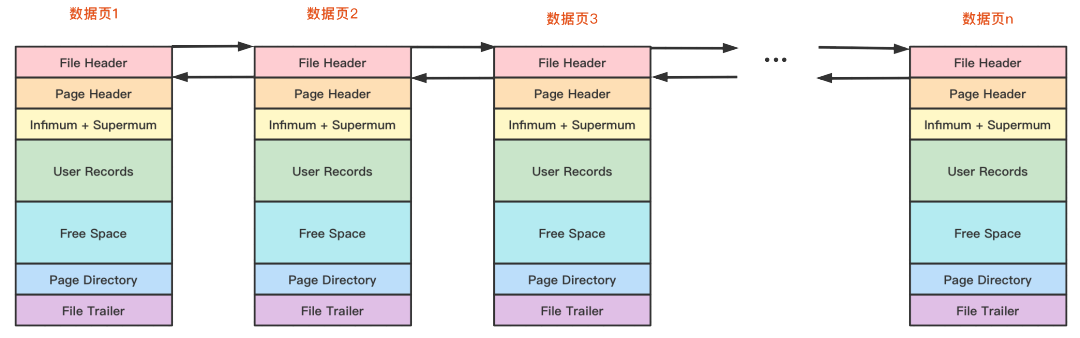
文件尾部(File Trailer)
- 前4个字节代表页的校验和,和File Header的遥相呼应,刷盘时先写File Header的校验和,再写File Trailer的,如果不一致证明页面出现损坏
- 后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
日志与数据刷新
DWB(double write bufffffer)
MySQL的一页的大小是16K,文件系统一页的大小是4K,即MySQL将buffer中一页数据刷入磁盘,要写4个文件系统里的页
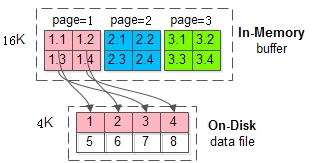
这个操作并非原子,如果执行到一半断电,会不会出现问题呢?会,这就是所谓的“页数据损坏”
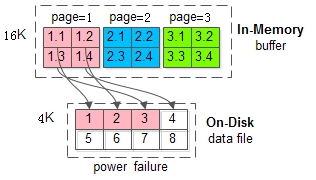
redo无法修复这类”页数据损坏”的异常,修复的前提是”页数据正确”并且redo日志正常
于是就有了解决方案Double Write Buffer,但它与传统的buffer不同,它分为内存和磁盘的两层架构。即传统的buffer,大部分是内存存储,而DWB里的数据,是需要落地的
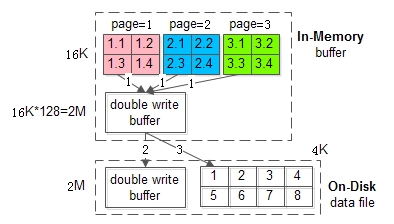
第一步:页数据内存的数据先拷贝到DWB的内存里
第二步:DWB的内存刷到DWB的磁盘上
第三步:DWB的内存刷到数据磁盘存储上
假设步第二步出现问题,磁盘里依然是1+2+3+4的完整数据,只要有页数据完整,就还能通过redo还原数据
假设步第三步出现问题,DWB里存储着完整的数据,可通过DWB的数据恢复磁盘数据
REDO日志
在页面修改完成之后,在脏页刷出磁盘之前,要先写入Redo日志,防止异常情况导致数据错误,而且Redo日志一定是先行的(聚簇索引、二级索引、Undo页面修改,均需要记录Redo日志)
存储位置:数据路径下,进行轮序覆盖记录日志(名称ib_logfileN)
查询Redo log文件配置:show variables like '%innodb_log_file%';
生产建议:512M-4G 2-4组
从MySQL 8.0.30开始,InnoDB的重做日志架构发生了重大变化,重做日志文件被固定为32个,并存放在一个专门的目录(#innodb_redo)下面,用户可以使用系统变量innodb_redo_log_capacity(默认100M)在线修改重做日志容量,原来的innodb_log_files_in_group和innodb_log_file_size两个系统变量已经废弃。
UNDO 日志
当事务执行过程中突然中止,为了保证事务的原子性,需要回滚回原来的样子,每当要对一条记录进行改动时,都需要记录下一些信息,为了回滚而记录的东西称为撤销日志,即undo日志。二级索引记录的修改,不记录Undo日志。
LSN(日志序列号)
LSN(log sequence number)日志序列号,占用8字节,LSN主要用于发生宕机时对数据进行恢复,LSN是一个一直递增的整型数字,表示事务写入到日志的字节总量。LSN不仅只存在于重做日志中,在每个数据页头部也会有对应的LSN号,该LSN记录当前页最后一次修改的LSN号,用于在恢复时对比重做日志LSN号决定是否对该页进行恢复数据。checkpoint也是有LSN号记录的,LSN号串联起一个事务开始到恢复的过程
-- 查看LSN信息
show engine innodb status\G;
-- 返回信息说明:
-- Log sequence number: 当前系统最大的LSN号
-- log flushed up to:当前已经写入redo日志文件的LSN
-- pages flushed up to:已经将更改写入脏页的lsn号
-- Last checkpoint at就是系统最后一次刷新buffer pool脏中页数据到磁盘的checkpoint
-- 以上4个LSN是递减的: LSN1>=LSN2>=LSN3>=LSN4
checkpoint(检查点)
按照类型分类
- sharp checkpoint:完全检查点,数据库正常干净关闭时,会触发把所有的脏页都写入到磁盘上(这时候logfile的日志就没用了,脏页已经写到磁盘上了)
- fuzzy checkpoint:模糊检查点,部分页写入磁盘。
按照触发源头分类
-
master thread checkpoint:差不多以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,这个过程是异步的,不会阻塞用户查询
-- PCI-E建议 2000-3000 4000-6000 -- flash建议 5000-8000 10000-16000 select @@innodb_io_capacity; -- 默认200 select @@innodb_io_capacity_max; -- 默认2000 -
flush_lru_list checkpoint:控制lru列表中可用页的数量,默认是1024
select @@innodb_lru_scan_depth; -
async/sync flush checkpoint:log file快满了,会批量的触发数据页回写,这个事件触发的时候又分为异步和同步
redo log 占 log file 的比值大于75%是异步;大于90%是同步
-
dirty page too much checkpoint:脏页太多检查点,为了保证buffer pool的空间可用性的一个检查点
-- Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total:表示脏页在buffer的占比 select @@Innodb_buffer_pool_pages_dirty; select @@Innodb_buffer_pool_pages_total; -- 如果>0,说明出现性能负载,buffer pool中没有干净可用块 show global status like '%Innodb_buffer_pool_wait_free';
InnoDB 事务详解
事务的ACID
Atomicity:原子性,一个事务生命周期中的DML语句,要么全成功要么全失败,不可以出现中间状态
实现机制:undo保证的
Consistency:一致性,事务发生前,中,后,数据都最终保持一致
实现机制:CR + DWB
Isolation:隔离性,事务操作数据行的时候,不会受到其他事务的影响
实现机制:MVCC、锁
Durability:持久性,一但事务提交,永久生效(落盘)
实现机制:redo、ckpt
隔离级别
READ-UNCOMMITTED(RU):读未提交,可以读取到事务未提交的数据。隔离性差,会出现脏读(当前内存读),不可重复读,幻读问题
READ-COMMITTED(RC):读已提交(生成一般使用)。可以读取到事务已提交的数据。隔离性一般,不会出现脏读问题,但是会出现不可重复读,幻读问题
REPEATABLE-READ(RR ):可重复读(默认)。防止脏读(当前内存读),不可重复读,幻读问题。需要配合锁机制来避免幻读
SERIALIZABLE(SE):可串行化
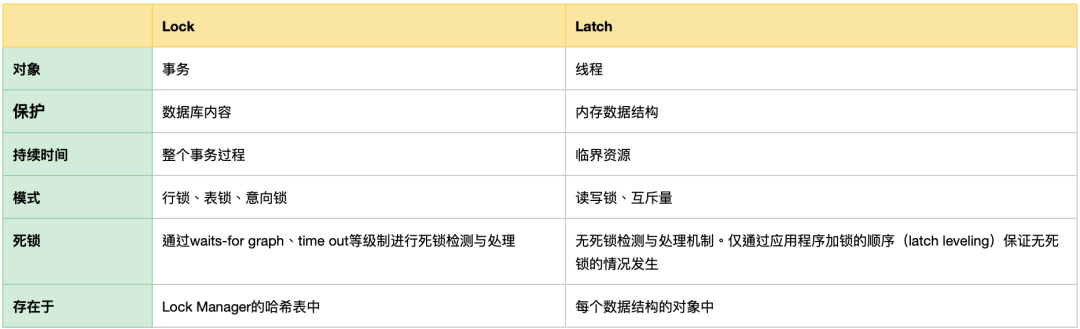
InnoDB 锁机制
latch
latch,闩(shuān)锁,直译过来就是锁,但latch的作用是用于控制内存中的数据结构并发访问的(通俗来讲,就是保护内存中数据结构完整性的)。与数据库的锁(Lock)不同,数据库中的锁对象不是内存结构,锁住的是一行一行的记录,而latch锁住的是并发资源的对象,也称作临界区。并且二者持续的时间不一样,Lock是贯穿整个事务,事务提交了,Lock才会释放。其实任何系统中都有latch,无处不在。就像java中的Lock
在InnoDB存储引擎中,latch又可以分为mutex(互斥量)和rwlock(读写锁)。其目的是用来保证并发线程操作临界资源的正确性,并且通常没有死锁检测机制
InnoDB的S锁、X锁
共享锁(S)和排他锁(X)都属于行级别(row-level)的锁,且都比较好理解,S锁与X锁互相冲突,X锁与X锁也是互相冲突,S锁与S锁不会冲突
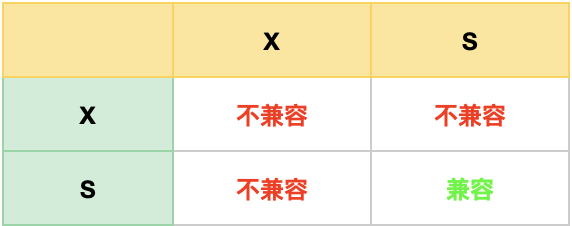
- 当读取一行记录时,为了防止别人修改,需要添加S锁。
- 当修改一行记录时,为了防止别人同时进行修改,需要添加X锁
通常情况下,普通的查询属于非锁定读,不会添加任何锁(即一致性读,利用MVCC)。还有一种是锁定读(即当前读),那么以下两种当前读情况会触发锁:
SELECT ... LOCK IN SHARE MODE;这个语法会添加S锁,对于其他事务可以读但不可以修改SELECT ... FOR UPDATE;这个语法会添加X锁,其他事务修改或者执行SELECT ... FOR UPDATE操作都会被阻塞
使用SET GLOBAL innodb_status_output_locks='ON'; SHOW ENGINE INNODB STATUS ;可以查看当前锁是什么
InnoDB的IS锁和IX锁
S锁和X锁都是行级别,是加在索引(记录)上的。InnoDB存储引擎是支持多粒度锁定的,这种锁定允许事务在行级别上和表级别上同时存在。为了支持在不同粒度上进行加锁操作,InnoDB存储引擎支持一种额外的锁方式,称之为意向锁(INTENTION LOCK)。意向锁是将锁定的对象分为多个层次,意味着事务希望在更细粒度上进行加锁。
如果需要对行记录r加X锁,那么分别需要对数据库、表、页上先加 IX 或者 IS锁,最后对记录r上加X锁。
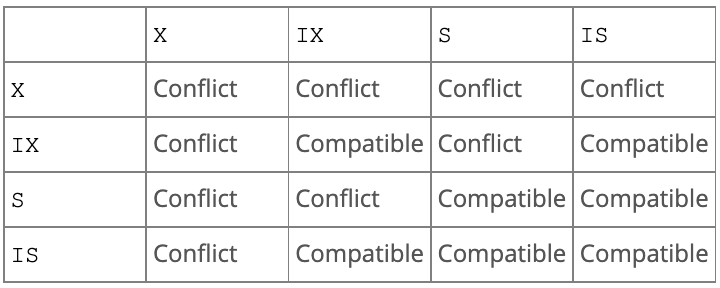
InnoDB存储引擎层的加锁顺序是:库 → 表 → 页 → 记录
InnoDB存储引擎设计意向锁的主要目的就是:为了在一个事务中揭示下一层将被请求的锁类型。即意向锁表示的是下一层级要加什么锁,对于当前这个层级,大家都是互相兼容的(大家加的都是锁的意向【有想法,但还未落实,落实的事情交给下一层手下的人去做】),所以锁兼容矩阵中 → 意向锁之间都是互相兼容的
也可手动给表级别加S/X锁,非常特殊情况才会使用
lock tables t read:
lock tables t write:对表t加X锁
InnoDB engine级别锁
RC隔离级别下,只有Record Lock(记录锁),没有Gap Lock(间隙锁)和Next-Key Lock(临键锁)
使用非聚集索引列进行数据更新时,MySQL会使用非聚集索引进行查找,对于查找到满足过滤条件的每一行索引记录
- 在查找到的非聚集索引记录上加锁
- 根据非聚集索引记录上包含的聚集索引键值进行回表查找
- 在查找到的聚集索引记录上加锁
- 循环1、2、3步处理下一条满足过滤条件的数据
Record Lock (记录锁):单个索引记录上的锁。锁定的是一条记录
GAP (间隙锁):锁定一个范围,但不包含记录本身(x, y)。间隙锁存在于RR(可重复读)隔离级别下,为防止幻读发生设计出来的一种手段,因RC(读已提交)隔离级别可能发生幻读,故RC隔离级别下没有间隙锁。
Next-Key Lock(临键锁):Gap Lock + Record Lock,锁定一个范围,并且锁定记录本身(x, y]。间隙锁存在于RR(可重复读)隔离级别下,为防止幻读发生设计出来的一种手段,因RC(读已提交)隔离级别可能发生幻读,故RC隔离级别下没有间隙锁。
performance_schema.data_locks表能看到加了哪些锁
在RR级别下的加锁细节
原则 1:加锁的基本单位是 next-key lock。并且next-key lock 是前开后闭区间。(5,10]
原则 2:查找过程中访问到的索引才会加锁
原则 3:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁
常见场景:
update ... where id=?,RC\RR模式下都是Record Lock
update ... where id in (?,?,?),RC\RR模式下都是Record Lock
update ... where id < ?,RC模式下Record Lock,RR模式下GAP
update ... where id <= ?,RC模式下Record Lock,RR模式id存在是Next-Key Lock,否则是GAP
不同情况下的锁处理示例
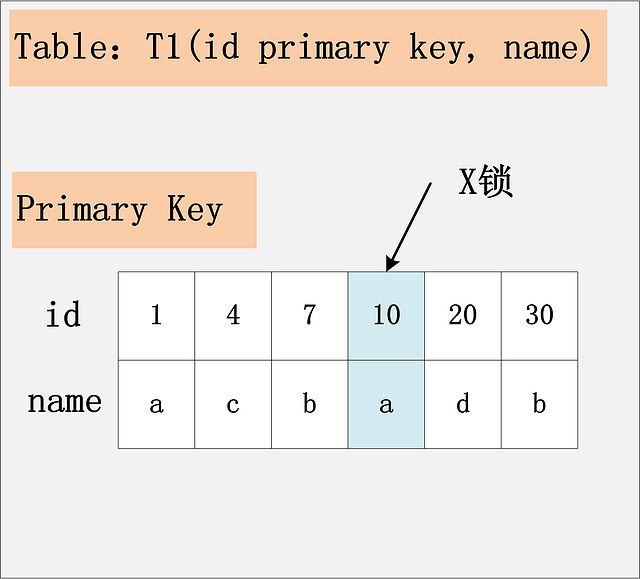
组合一:id主键+RC
给定SQL:delete from t1 where id = 10; 只需要将主键上,id = 10的记录加上X锁即可。如下图所示
组合二:id唯一索引+RC
这个组合,id不是主键,而是一个Unique的二级索引键值。那么在RC隔离级别下,delete from t1 where id = 10;
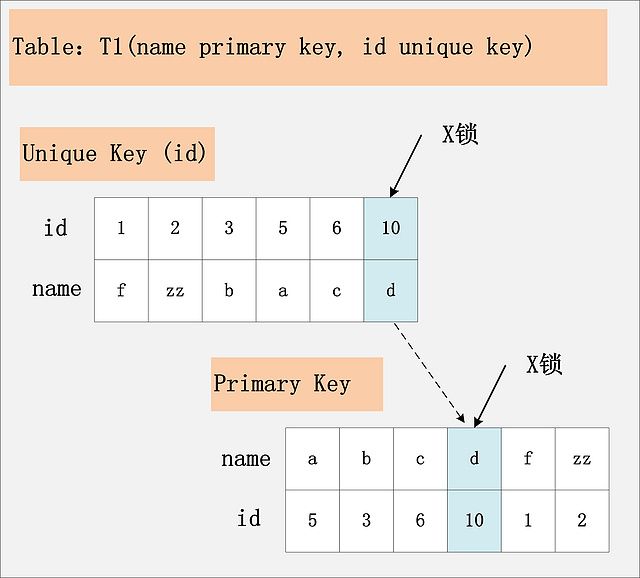
此时,加锁的情况由于组合一有所不同。由于id是unique索引,因此delete语句会选择走id列的索引进行where条件的过滤,在找到id=10的记录后,首先会将unique索引上的id=10索引记录加上X锁,同时,会根据读取到的name列,回主键索引(聚簇索引),然后将聚簇索引上的name = ‘d’ 对应的主键索引项加X锁。
组合三:id非唯一索引+RC
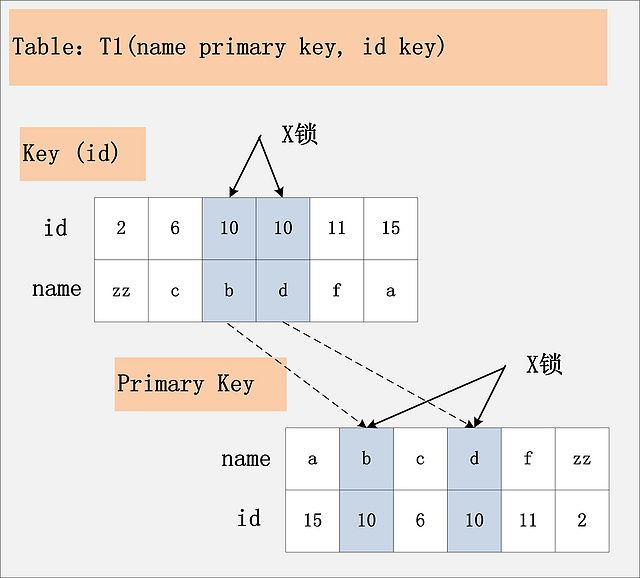
首先,id列索引上,满足id = 10查询条件的记录,均已加锁。同时,这些记录对应的主键索引上的记录也都加上了锁。与组合二唯一的区别在于,组合二最多只有一个满足等值查询的记录,而组合三会将所有满足查询条件的记录都加锁、
组合四:id无索引+RC
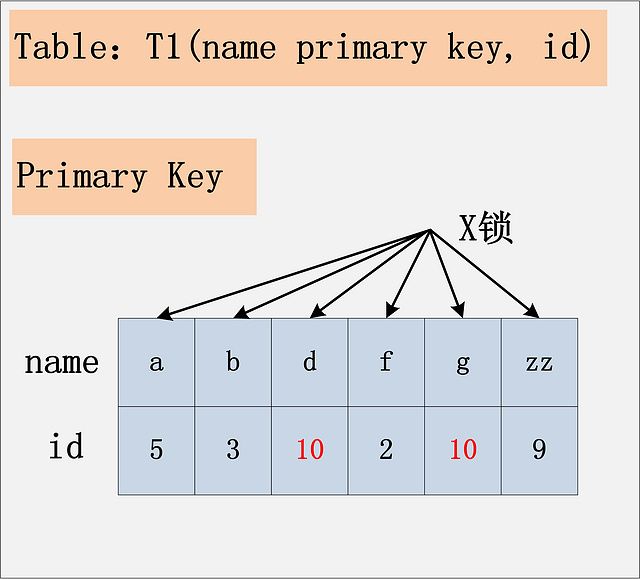
由于id列上没有索引,因此只能走聚簇索引,进行全部扫描。从图中可以看到,满足删除条件的记录有两条,但是,聚簇索引上所有的记录,都被加上了X锁。无论记录是否满足条件,全部被加上X锁。既不是加表锁,也不是在满足条件的记录上加行锁。
为什么不是只在满足条件的记录上加锁呢?这是由于MySQL的实现决定的。如果一个条件无法通过索引快速过滤,那么存储引擎层面就会将所有记录加锁后返回,然后由MySQL Server层进行过滤。因此也就把所有的记录,都锁上了。在实际的实现中,MySQL有一些改进,在MySQL Server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录放锁 (违背了2PL的约束)。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。
组合五:id主键+RR
组合一:[id主键,Read Committed]一致
组合六:id唯一索引+RR
与组合二[id唯一索引,Read Committed]一致。两个X锁,id唯一索引满足条件的记录上一个,对应的聚簇索引上的记录一个
组合七:id非唯一索引+RR
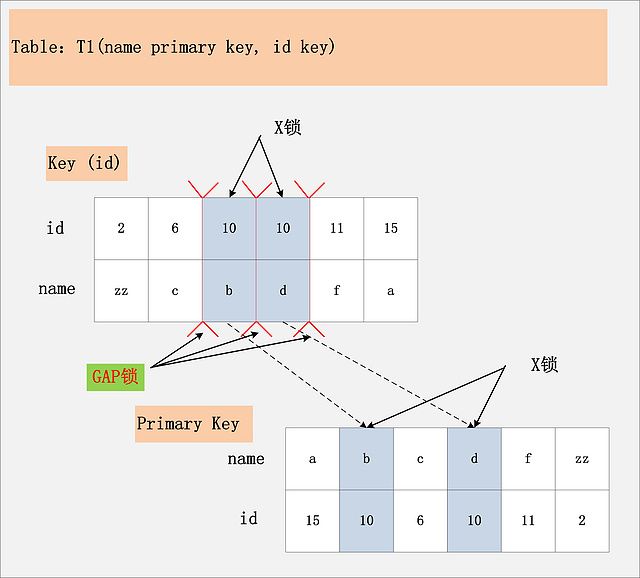
Key(id) 锁定了(【6, c】, 【10, b】) + 【10, b】; (【10, b】, 【10, d】) + 【10, d】; + (【10, d】, 【11, f】)
Primary Key 锁定了【b】,【d】
RR隔离级别下,id列上有一个非唯一索引,对应SQL:delete from t1 where id = 10; 首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束
组合八:id无索引+RR
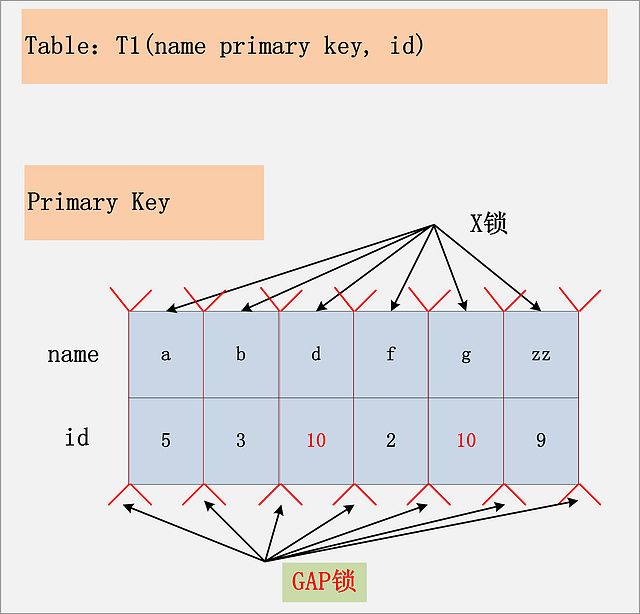
这是一个很恐怖的现象。首先,聚簇索引上的所有记录,都被加上了X锁。其次,聚簇索引每条记录间的间隙(GAP),也同时被加上了GAP锁。这个示例表,只有6条记录,一共需要6个记录锁,7个GAP锁。试想,如果表上有1000万条记录呢!
MVCC 多版本并发控制
在InnoDB中的每一条记录实际都会存在三个隐藏列:
- DB_TRX_ID:事务 ID,是根据事务产生时间顺序自动递增的,是独一无二的。如果某个事务执行过程中对该记录执行了增、删、改操作,那么InnoDB存储引擎就会记录下该条事务的 id
- DB_ROLL_PTR:回滚指针,本质上就是一个指向记录对应的undo log的一个指针,InnoDB 通过这个指针找到之前版本的数据
- DB_ROW_ID:主键,如果有自定义主键,那么该值就是主键;如果没有主键,那么就会使用定义的第一个唯一索引;如果没有唯一索引,那么就会默认生成一个隐藏列作为主键
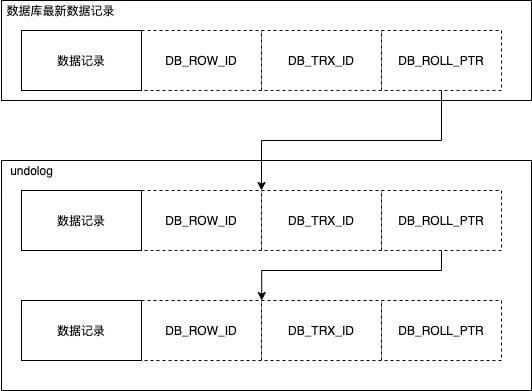
Read View
Read View是InnoDB在实现MVCC时用到的一致性读视图,用于支持读提交和可重复读隔离级别的实现,作用是执行期间判断版本链中的哪个版本是当前事务可见的。本质上是InnoDB为每个事务构造了一个数组,用来保存当前正在活跃(启动了但还没提交)的所有事务ID。
数组里面事务ID的最小值记为低水位,当前系统里面已经创建过的事务ID的最大值加1记为高水位;这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)。
MVCC与隔离级别
MVCC 只在 **Read Commited(读已提交) 和 Repeatable Read(可重读读) **两种隔离级别下工作。
- 在RC隔离级别下,是每个快照读都会生成并获取最新的Read View,这就是我们在RC级别下的事务中可以看到别的事务提交的更新的原因
- 在RR隔离级别下,则是同一个事务中的第一个快照读才会创建Read View, 之后的快照读获取的都是同一个Read View,从而做到可重复读
RR级别下当前读的幻读问题
| 时刻 | 事务1 | 事务2 |
|---|---|---|
| T1 | select * from user where id>100; | |
| T2 | # 输出N条记录 | insert into user values(103, ‘wangwu’, 20); |
| T3 | commit; | |
| T4 | update user set age=21 where id>100; | |
| T5 | select * from user where id>100; | |
| T6 | # 输出N+1条记录 |
产生幻读的原因:
在T4时刻,由于update语句采用的是当前读,会对事务2新增的记录进行加锁、修改age字段值、修改DB_TRX_ID隐藏字段值。
在T5时刻使用快照读时,根据可见性算法,这条新增记录的DB_TRX_ID是当前事务,所以是可见的,所以输出了N+1条记录
解决方案:select的时候加for update;或者lock in share mode;
9、备份恢复与迁移
binlog 日志的格式
-
Statement(Statement-Based Replication,SBR):每一条会修改数据的 SQL语句 都会记录在 binlog 中,如果使用uuid()等函数会出现问题
-
Row(Row-Based Replication,RBR):不记录 SQL 语句上下文信息,仅保存哪条记录被修改
-
Mixed(Mixed-Based Replication,MBR):Statement 和 Row 的混合体,系统会自动判断执行语句该用 Statement (优先使用)还是 Row
GTID
在传统的mysql基于二进制日志的模式复制中,从库需要告知主库要从哪个二进制日志文件中的那个偏移量进行增量同步,如果指定错误会造成数据的遗漏,从而造成数据的不一致。借助gtid,在发生主备切换的情况下,mysql的其它从库可以自动在新主库上找到正确的复制位置,这大大简化了复杂复制拓扑下集群的维护,也减少了人为设置复制位置发生误操作的风险。另外,基于gtid的复制可以忽略已经执行过的事务,减少了数据发生不一致的风险。所以说,相比mysql传统的主从复制模式,gtid模式的复制对于 DBA/开发人员/运维 等相关技术人员更加友好。
binlog操作
基本操作
-- 查看二进制文件列表
show binary logs;
-- 查看正在使用的二进制文件,包含了偏移量和GTID信息
show master status;
-- 查看二进制文件存储的内容
show binlog events in '二进制日志文件'\G;
# 使用工具查看
mysqlbinlog --read-from-remote-server -h地址 -P端口 -u用户名 -p密码 -d 数据库 二进制文件
自动清理日志
-- 查看日志自动清理时间
-- 8.0之前expire_logs_days
-- 8.0之后expire_logs_days
-- 企业建议,至少保留两个全备周期+1的binlog
show variables like '%expire%';
my2sql 应用
# 安装配置
wget https://github.com/liuhr/my2sql/blob/master/releases/centOS_release_7.x/my2sql
# 解析日志事件SQL
./my2sql -user 用户名 -password 密码 -host 地址 -port 端口 -mode repl -work-type 2sql -start-file 二进制文件 -start-datetime 开始时间 -output-dir ./tmpdir
#生成指定事件回滚语句
./my2sql -user 用户名 -password 密码 -host 地址 -port 端口 -mode repl -work-type rollback -start-file 二进制文件 -start-pos 开始位置 -stop-file 二进制文件 -stop-pos 结束位置 -output-dir ./tmpdir
slow log的查看
# -s c 安装执行个数排序
# -t top
mysqldumpslow -s c -t 10 慢查询文件路径
物理备份
Clone Plugin
MySQL 8.0推出了Clone Plugin插件有两种模式
本地克隆:启动克隆操作的MySQL服务器实例中的数据,克隆到同服务器或同节点上的一个目录里
远程克隆:默认情况下,远程克隆操作会删除接受者(recipient)数据目录中的数据,并将其替换为捐赠者(donor)的
克隆数据。您也可以将数据克隆到接受者的其他目录,以避免删除现有数据。(可选)
-- 加载插件
-- 或者配置my.cnf
-- plugin-load-add=mysql_clone.so
-- clone=FORCE_PLUS_PERMANENT
INSTALL PLUGIN clone SONAME 'mysql_clone.so';
-- 查看插件信息
SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE 'clone';
-- 创建克隆专用用户
CREATE USER clone_user@'%' IDENTIFIED with mysql_native_password by 'password';
GRANT BACKUP_ADMIN ON *.* TO 'clone_user';
-- 本地克隆
mkdir -p /data/backup/
chown -R mysql.mysql /data/
mysql -uclone_user -ppassword -e"CLONE LOCAL DATA DIRECTORY = '/data/backup/clonedir'";
-- 观察状态
SELECT STAGE, STATE, END_TIME FROM performance_schema.clone_progress;
-- 日志观测
set global log_error_verbosity=3;
tail -f 错误日志
-- 克隆远程数据
-- 创建远程clone用户
-- 捐赠者授权(源端)
create user clone_s@'%' identified by '源端密码';
grant backup_admin on *.* to clone_s@'%';
-- 接受者授权(目标端)
create user clone_t@'%' identified by '目标端密码';
grant clone_admin on *.* to clone_t@'%';
-- 目标端开始克隆
SET GLOBAL clone_valid_donor_list='源端ip:源端口';
mysql -uclone_t -p123 -h目标端IP -P目标端端口 -e "CLONE INSTANCE FROM clone_s@'源端IP':端口 IDENTIFIED BY '源端密码';"
10、各种架构体系
| 无故障时间 | 故障时间 | 方案 |
|---|---|---|
| 99.9% | 0.1% = 525.6 min | KA+双主 :人为干预 |
| 99.99% | 0.01% = 52.56 min | MHA |
| 99.999% | 0.001% = 5.256 min | PXC、 MGR |
| 99.9999% | 0.5256 min | 自动化、云化、平台化、分布式 |
附录
8.0版本相对于5.7版本的变化
-
支持事务性DDL,崩溃可以回滚,保证一致
- 保留一份数据字典信息,取消frm数据字典。
- 数据字典存放至InnoDB表中
-
采用套锁机制,管理数据字典的并发访问(MDL)
-
全新的Plugin支持,8.0.17+ 加入Clone Plugin,更好的支持MGR,InnoDB Cluster的节点管理
- 安全加密方式改变,改变加密方式为caching_sha2_password
- 改变授权管理方式
- 加入role角色管理
- 取消Query Cache
各版本InnoDB表文件结构的变化
8.0 以前 InnoDB表:
- ibd : 数据和索引
- frm : 存私有的数据字典信息
8.0 之后 InnoDB表:
-
ibd:数据和索引
-
公共sdi(冗余的私有数据字典信息)
MySQL5.7升级到8.0
升级前一定要先做冷备,方便失败回退。
下载安装mysql-shell工具,8.0以后可以调用这个命令,升级之前的预检查。
-
创建连接用户
grant all on *.* to root@'%' identified by '密码'; -
预检查
mysqlsh root:密码@'%':端口 -e "util.checkForServerUpgrade()" >/tmp/up.log -
停原库
# 0代表当MYSQL关闭时,Innodb需要完成所有full purge和merge insert buffer操作。如果做升级,通常需要将这个参数调为0,然后在关闭数据库 set global innodb_fast_shutdown=0; mysqladmin -S socket文件路径 shutdown -
使用高版本软件挂低版本数据启动
# 让数据库升级
/usr/local/mysql/bin/mysqld_safe --defaults file=5.7库配置文件路径 --skip-grant-tables --skip-networking &
# 关闭数据库,并重新启动数据库
/usr/local/mysql/bin/mysqld_safe --defaults file=5.7库配置文件路径 &
# 设置回默认值
set global innodb_fast_shutdown=1;
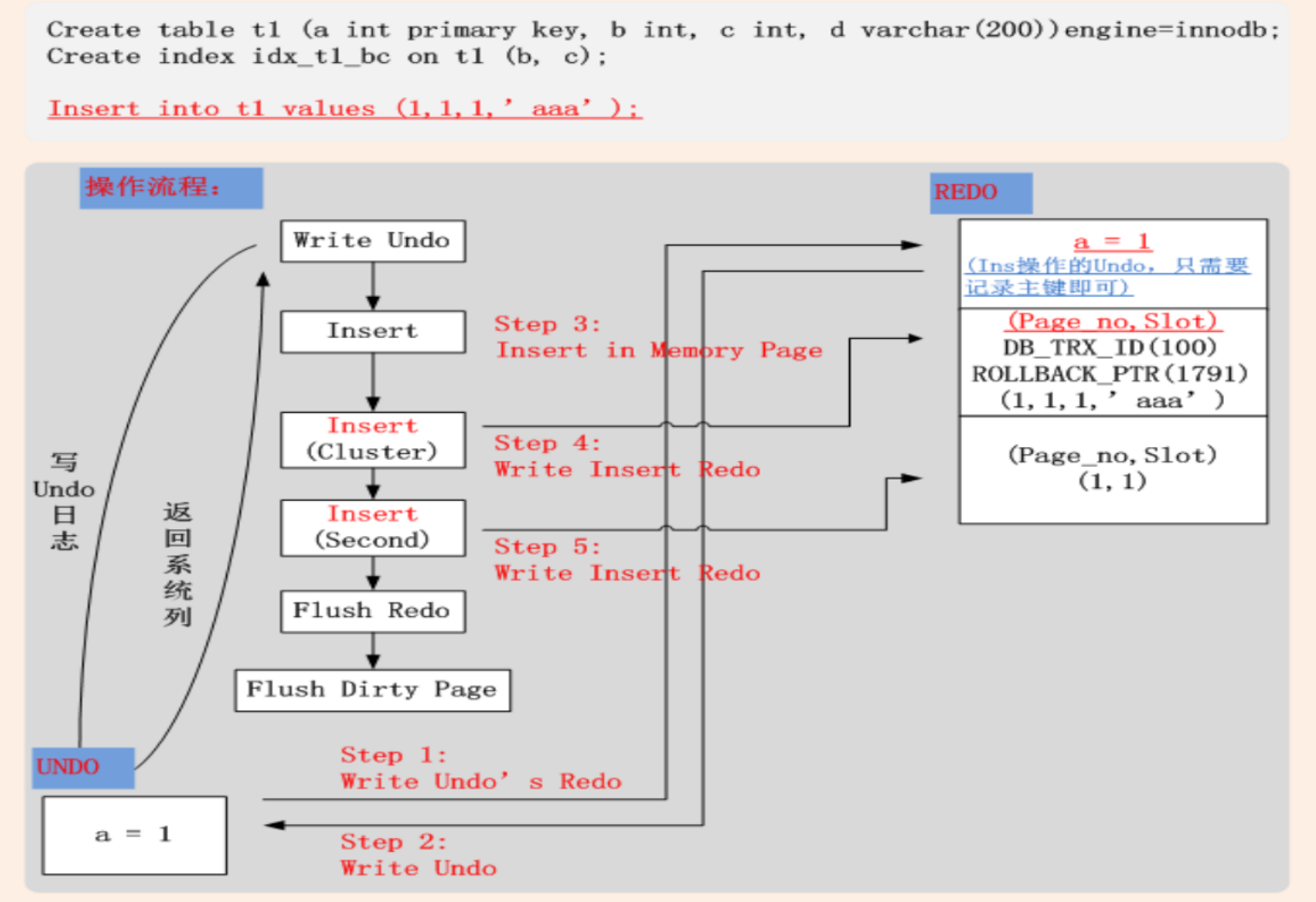
InnoDB Undo、Redo在增删改操作时的工作
INSERT
-
Undo
将插入记录的主键值,写入Undo;
-
Redo
将完整数据行信息写入Redo;
DELETE
-
Undo
- Delete,在InnoDB内部为Delete Mark操作,将记录上标识Delete_Bit,而不删除记录
- 将当前记录的系统列写入Undo
- 将当前记录的主键列写入
- 将当前记录的所有索引列写入Undo
- 将Undo Page的修改,写入Redo
-
Redo
将完整数据行信息写入Redo
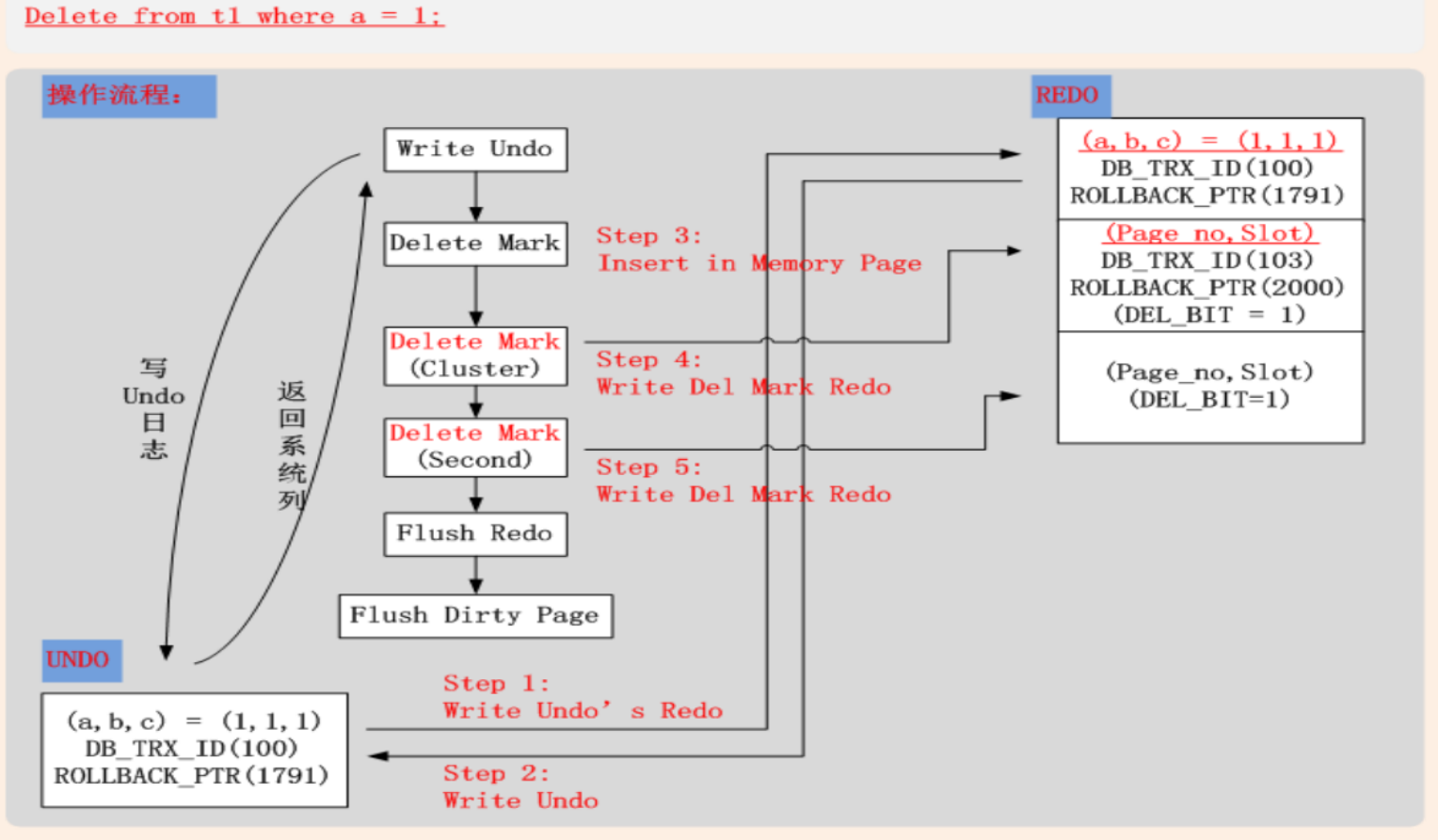
UPDATE
情况一:Update(未修改聚簇索引键值,属性列长度未变化)
- Undo(聚簇索引)
- 将当前记录的系统列写入Undo
- 将当前记录的主键列写入Undo
- 将当前Update列的前镜像写入Undo
- 若Update列中包含二级索引列,则将二级索引其他未修改列写入Undo
- 将Undo页面的修改,写入Redo
- Redo
- 进行In Place Update,记录Update Redo日志(聚簇索引)
- 若更新列包含二级索引列,二级索引肯定不能进行In Place Update,记录Delete Mark + Insert 日志
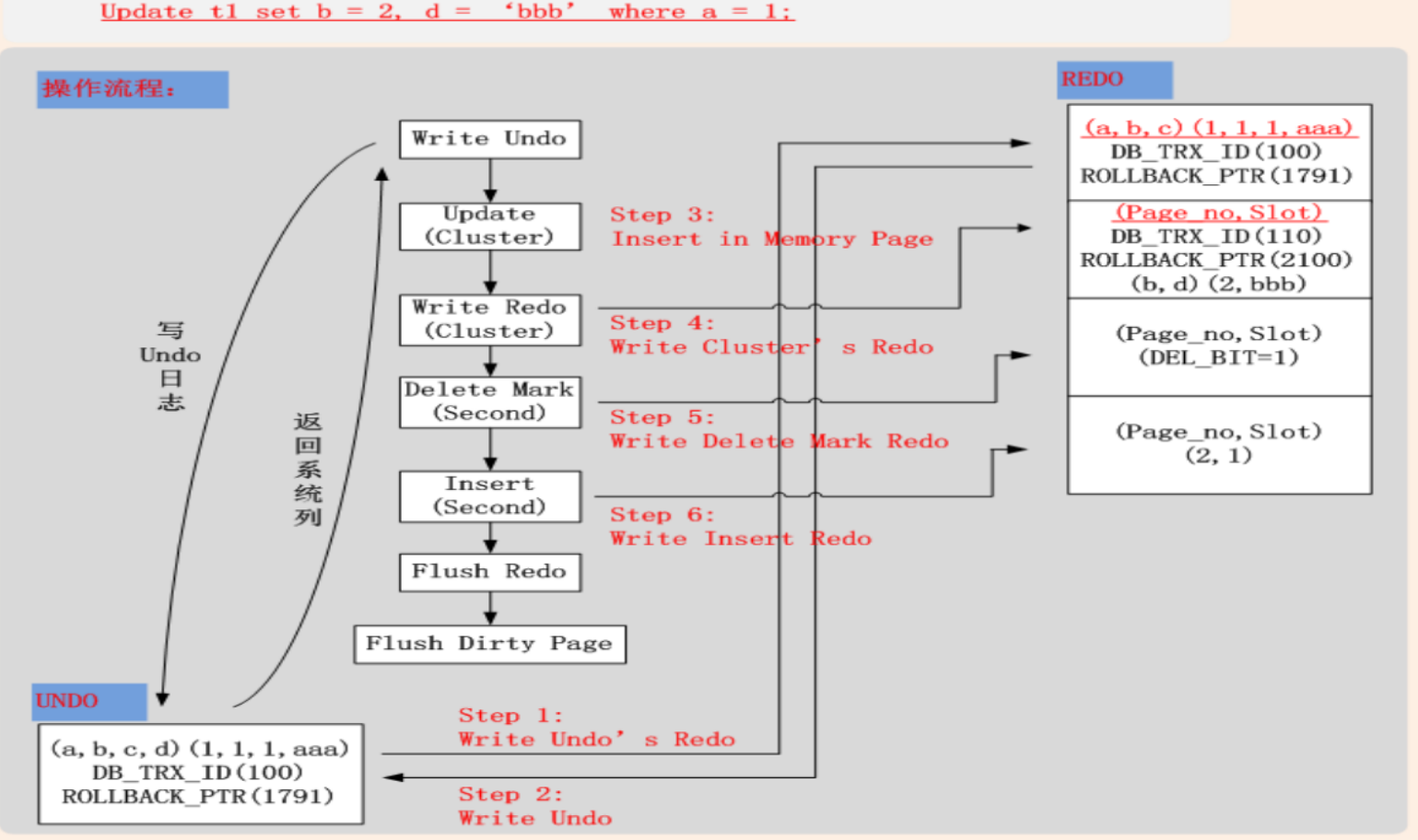
情况二: Update(未修改聚簇索引键值,属性列长度发生变化)
- Undo(聚簇索引)
- 将当前记录的系统列写入
- 将当前记录的主键列写入
- 将当前Update列的前镜像写入
- 若Update列中包含二级索引列,则将二级索引其他未修改列写入Undo
- 将Undo页面的修改,写入Redo
- Redo
- 不可进行In Place Update,记录Delete + Insert Redo日志(聚簇索引)
- 若更新列包含二级索引列,二级索引肯定不能进行In Place Update,记录Delete Mark + Insert Redo日志
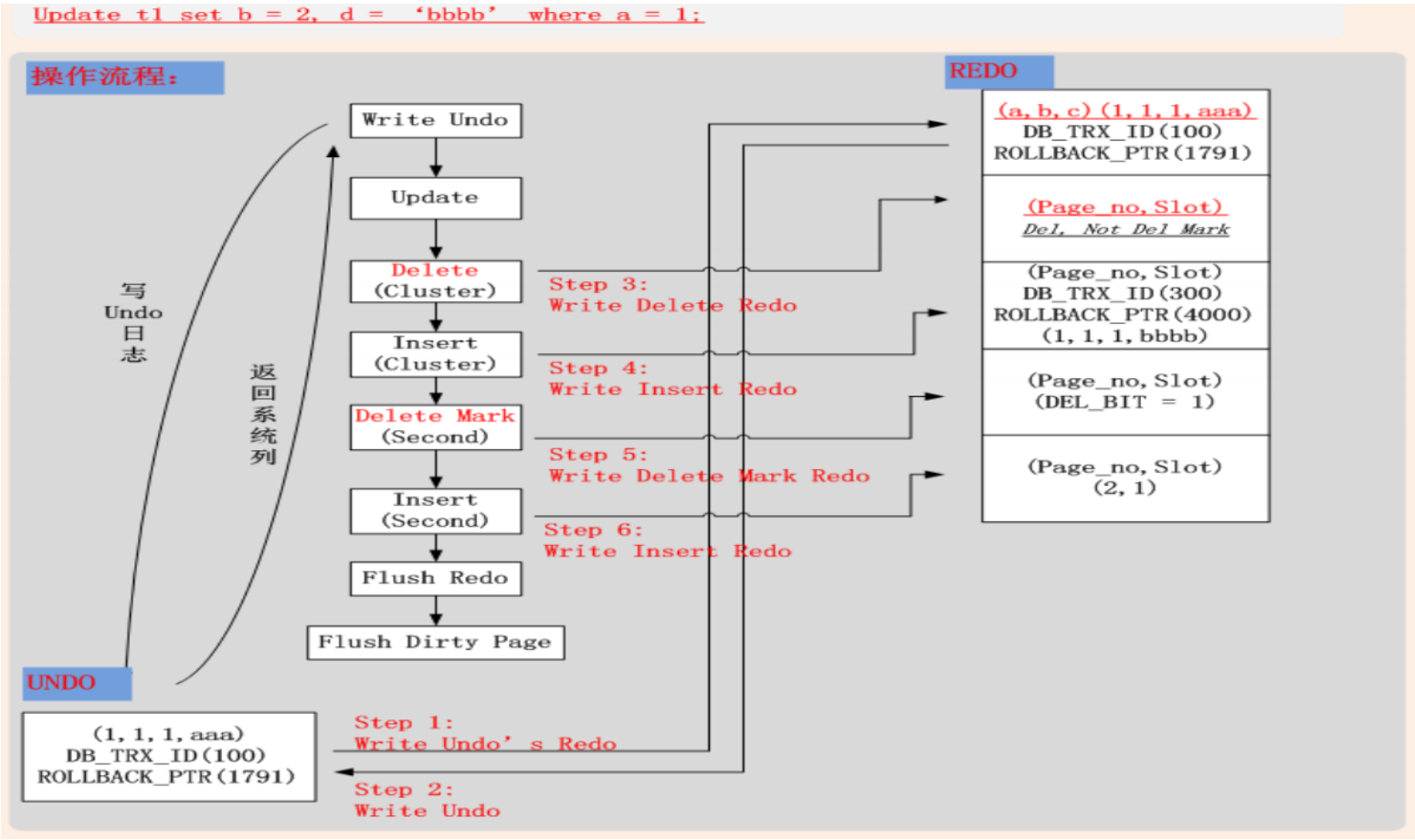
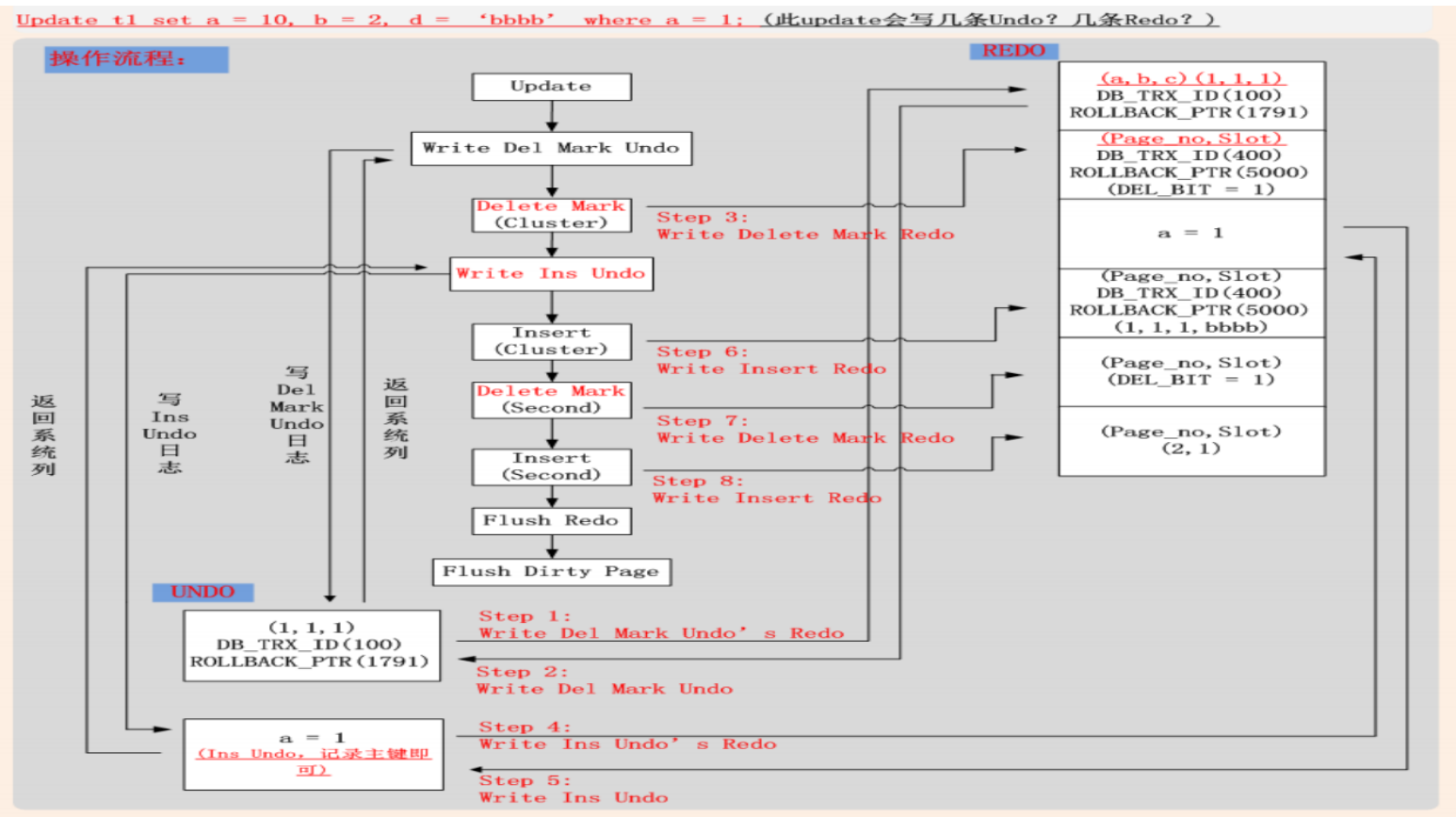
情况三:Update(修改聚簇索引键值)
- Undo (聚簇索引)
- 不可进行In Place Update。Update = Delete Mark + Insert
- 对原有记录进行Delete Mark操作,写入Delete Mark操作Undo
- 将新纪录插入聚簇索引,写入Insert操作Undo
- 将Undo页面的修改,写入Redo
- Redo
- 不可进行In Place Update,记录Delete Mark + Insert Redo日志(聚簇索引)
- 若更新列包含二级索引列,二级索引肯定不能进行In Place Update,记录Delete Mark + Insert 日志