PXC集群使用
一、Percona概览
Percona Server简介
Percona Server由领先的MySQL咨询公司Percona发布。Percona Server是一款独立的数据库产品,其可以完全与MySQL兼容,可以在不更改代码的情况了下将存储引擎更换成XtraDB。 Percona团队的最终声明是“Percona Server是由Oracle发布的最接近官方MySQL Enterprise发行版的版本”,因此与其他更改了大量基本核心MySQL代码的分支有所区别。Percona Server的一个缺点是他们自己管理代码,不接受外部开发人员的贡献,以这种方式确保他们对产品中所包含功能的控制。
Percona提供了高性能XtraDB引擎,还提供PXC高可用解决方案,并且附带了perconatoolkit等DBA管理工具。
XtraDB可以看作是InnoDB存储引擎的增强版本,它在InnoDB上进行了大量的修改和patched,它完全兼容InnoDB,且提供了很多InnoDB不具备的有用的功能。
PXC集群
PXC【Percona XtraDB Cluster】是基于Galera的面向OLTP的多主同步复制插件,即Galera替代了Replication技术完成主从复制工作,是实现主从复制的插件。
PXC集群特点:
- 同步复制【事务在所有节点要么同时提交,要么不提交】
- 多主复制【可以在任意节点写入】
- 同步的强一致性
- 集群同步速度取决于配置最低的节点
- PXC集群并不是节点越多越好【同步操作是要等待所有节点写入,即越多工作量越大】
MySQL各类衍生品的比较

二、安装Percona
安装Percona Server
第一步:安装前置依赖【Percona Server依赖jemalloc】
# 安装epel源方便直接安装jemalloc
yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
# 安装jemalloc
yum install jemalloc
第二步:解压完tar包直接安装所有rpm
yum localinstall *.rpm
第三步:配置Percona Server【/etc/my.cnf】
#################################添加以下配置#################################
character-set-server=utf8
bind-address=0.0.0.0
# 跳过DNS解析
skip-name-resolve
第四步:启动和禁止开机自启动
# 启动percona
systemctl start mysqld
# 禁止开机自启动,如果PXC一个宕机节点宕机时间较长,那么集群会阻塞操作等待这一台机器同步完成
chkconfig mysqld off
第五步:获取&修改ROOT密码
# 根据日志寻找初始密码
cat /var/log/mysqld.log | grep password
# 使用以下命令根据提示修改ROOT密码
mysql_secure_installation
第六步:创建用户,开放远程登陆权限
CREATE USER '[username]'@'%' IDENTIFIED BY 'password'
GRANT ALL PRIVILEGES ON *.* TO '[username]'@'%' IDENTIFIED BY '[password]' WITH GRANT OPTION;
忘记ROOT密码解决方案
修改 my.cnf 加入 skip-grant-tables 然后重启mysql服务,之后直接使用mysql命令进入不需要用户名和密码
执行 UPDATE user SET password=password(‘new-password’) WHERE user = ‘root’;FLUSH PRIVILEGES;
删除 my.cnf 加入的 skip-grant-tables 然后重启mysql服务
安装PXC集群
第一步:移除mariaDB
yum -y remove mari*
第二步:yum仓库源安装PXC
# 安装源解决依赖问题
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
yum install Percona-XtraDB-Cluster-57
第三步:修改配置文件【 /etc/percona-xtradb-cluster.conf.d/mysqld.cnf 】
#################################添加以下配置#################################
character-set-server=utf8
bind-address=0.0.0.0
# 跳过DNS解析
skip-name-resolve
第四步:禁止自启动和修改密码
第五步:修改配置文件【/etc/percona-xtradb-cluster.conf.d/wsrep.cnf】
#################################修改或添加以下配置#################################
# PXC集群中MySQL实例的唯一ID,不能重复,必须是数字
server-id=1
wsrep_provider=wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
# PXC集群名称
wsrep_cluster_name=pxc-cluster
# PXC集群中每一个节点的地址
wsrep_cluster_address==gcomm://IP1,IP2,IP3...
# 当前节点的名称
wsrep_node_name=pxc-cluster-node-1
# 当前节点的IP
wsrep_node_address=IP
# 同步方法(mysqldump、rsync、xtrabackup)
wsrep_sst_method=xtrabackup-v2
# 同步使用的账户
wsrep_sst_auth="[username]:[password]"
# 同步严厉模式
pxc_strict_mode=ENFORCING
# 基于ROW复制,PXC不支持MIXED
binlog_format=ROW
# 默认引擎
default_storage_engine=InnoDB
# 主键自增长不锁表
innodb_autoinc_lock_mode=2
第六步:启动PXC集群
# 第一个节点使用
systemctl start mysql@bootstrap.service
# 其余几点
systemctl start mysqld
第七步:查看集群规模
show status like '%wsrep_cluster%'
注:服务器环境下需要开放以下端口
| 端口 | 描述 |
|---|---|
| 3306 | MySQL服务端口 |
| 4444 | 请求全量同步(SST)端口 |
| 4567 | 数据库节点之间通信端口 |
| 4568 | 请求增量同步端口 |
firewall-cmd –zone=public –add-port=[port]/tcp –permanent
关闭节点
手动关闭使用什么命令启动,就使用什么命令关闭,如果主节点直接使用systemctl stop mysql则不会关闭,命令无效。非最后一个节点退出 /var/lib/mysql/grastate.dat下safe_to_bootstrap:0,下次按照非主节点启动。最后一个正常退出的节点safe_to_bootstrap:1,下次按照主节点启动。
PXC节点退出情况
-
PXC节点都是安全推出的,需要先启动最后一个退出的节点作为主节点启动。
-
PXC所有节点都是意外退出的,但是和最后节点意外退出时间间隔较长,最后节点意外退出还是会将
safe_to_bootstrap置为1,依旧先启动最后一个退出的节点作为主节点启动。 - PXC所有节点同时异常退出,需要挑选出一个节点将
safe_to_bootstrap改为1,在启动。、 - 如果还有集群还在服务,可以直接启动MySql服务
三、PXC集群相关信息
- 数据复制相关信息
| 参数名称 | 含义 |
|---|---|
| wsrep_replicated | 发送给节点同步消息次数 |
| wsrep_received | 接收的节点同步消息次数 |
| wsrep_last_applied | 同步应用次数 |
| wsrep_last_committed | 事务提交的次数 |
- 队列相关信息
| 参数名称 | 含义 |
|---|---|
| wsrep_local_send_queue | 发送队列的目前长度 |
| wsrep_local_send_queue_max | 发送队列的最大长度 |
| wsrep_local_send_queue_min | 发送队列的最小长度 |
| wsrep_local_send_queue_avg | 发送队列的平均长度 |
| wsrep_local_recv_queue | 接收队列的目前长度 |
| wsrep_local_recv_queue_max | 接收队列的最大长度 |
| wsrep_local_recv_queue_min | 接收队列的最小长度 |
| wsrep_local_recv_queue_avg | 接收队列的平均长度 |
- 流量控制相关信息
| 参数名称 | 含义 |
|---|---|
| wsrep_flow_control_paused_ns | 流控暂停状态下花费的总时间(秒) |
| wsrep_flow_control_paused | 流量控制的暂停时间的占比(0~1) |
| wsrep_flow_control_sent | 发送的流控暂停事件的数量 |
| wsrep_flow_control_recv | 接收的流控暂停事件的数量 |
| wsrep_flow_control_interval | 流控的上限和下限。上限是队列中允许的最大请求数,如果队列达到上限,则拒绝新的请求。当处理现有请求时,队列数量会减少,达到下限将再次允许新的请求 |
| wsrep_flow_control_status | 流量控制状态 |
执行同步的线程数一般可设置为CPU核心线程的1~1.5倍
wsrep_slave_threads=num
- 节点状态
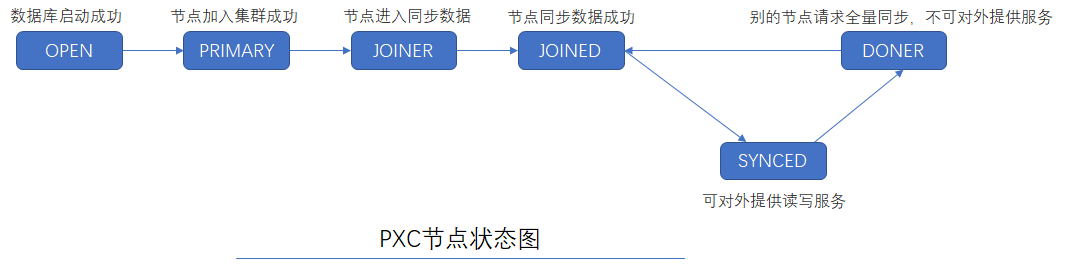
| 参数名称 | 含义 |
|---|---|
| wsrep_local_state_comment | 节点状态 |
| wsrep_connected | 节点是否连接到集群 |
- 集群状态
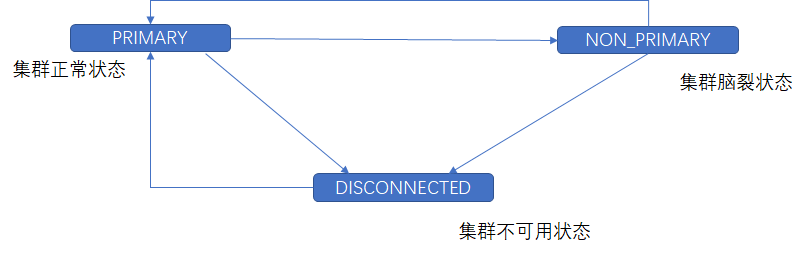
| 参数名称 | 含义 |
|---|---|
| wsrep_cluster_status | 集群状态 |
| wsrep_ready | 集群是否正常工作 |
| wsrep_cluster_size | 节点数量 |
| wsrep_desync_count | 延迟节点数量 |
| wsrep_incoming_addresses | 集群节点的IP地址 |
- 事务相关信息
| 参数名称 | 含义 |
|---|---|
| wsrep_cert_deps_distance | 事务执行并发数 |
| wsrep_apply_oooe | 接收队列中的事务占比 |
| wsrep_apply_oool | 接收队列中事务乱序执行的频率 |
| wsrep_apply_window | 接收队列中事务的平均数量 |
| wsrep_commit_oooe | 发送队列中的事务占比 |
| wsrep_commit_oool | 无任何意义,不存在本地乱序提交 |
| wsrep_commit_window | 发送队列中事务的平均数量 |
四、PXC集群原理
PXC集群执行事务是基于GTID的复制进行的,GTID是由SERVER_UUID和TRANSACTION_ID组成的,PXC集群执行事务SERVER_UUID取得是集群的UUID并非节点的UUID,即每个节点接收的GTID中的SERVER_UUID均相同。
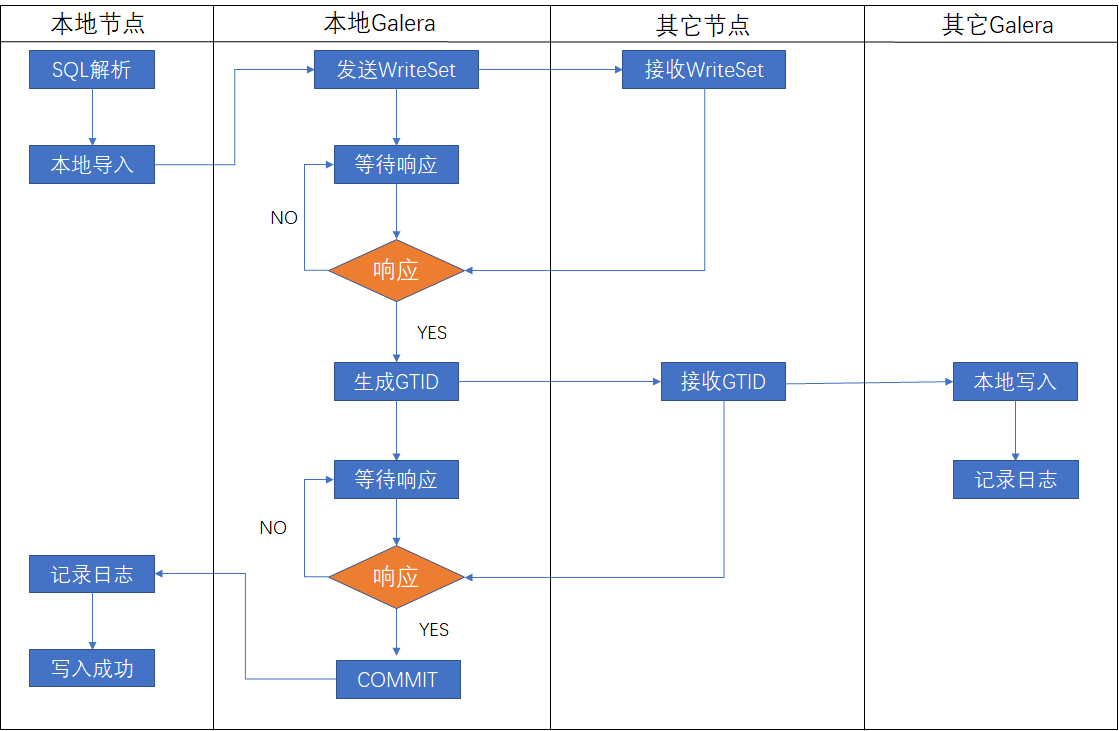
当本地节点接收有GTID任务时变为JOINED状态【不提供服务】,之后变为SYNCED【提供服务】
五、导入大量数据
在命令行使用source path/fileName.sql导入大量数据速度较慢,需要逐句执行语法分析、优化。
大量数据导入应该用load data命令导入数据(文本文档数据库),速度快不需要语法分析、优化。load data执行的是单线程导入,可以讲数据文件切分做并发导入。
前置条件:如果数据再另一台MySql服务器上可使用
SELECT * FROM [table]INTO OUTFILE '[fileName]' FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' ;
第一步:切分数据文件,并将数据上传到MyCat节点服务器
# -l 按照行拆分
# -d 文件名称
split -l 1000000 -d fileName.txt
第二步:每个PXC分片只开启一个节点并修改PXC节点文件,然后重启PXC服务
# 每秒将日志数据写入硬盘,不论事务是否提交,提升写入速度
innodb_flush_log_at_trx_commit=0
# 不使用操作系统缓冲区,直接将数据写入硬盘
innodb_flush_method=O_DIRECT
# 设置Mysql日志缓存大小,越大越好
innodb_buffer_pool_size=200M
第三步:在MyCat服务器上执行Java程序,多线程导入数据
@SpringBootApplication
public class DataImport implements ApplicationListener<ApplicationReadyEvent>, CommandLineRunner {
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private ConfigurableApplicationContext applicationContext;
static private Logger logger = LoggerFactory.getLogger(DataImport.class);
// 数据文件目录
private static File dataDir;
// 表名
private static String tableName;
public static void main(String[] args) {
SpringApplication.run(DataImport.class, args);
}
@Override
public void run(String... args) throws Exception {
if( args == null || args.length != 2 ) {
logger.error("请输入数据文件目录路径和表名");
applicationContext.close();
return;
}
File file = new File(args[0]);
if( !file.isDirectory() ) {
logger.error("第一个参数为目录路径");
applicationContext.close();
}
DataImport.dataDir = file;
DataImport.tableName=args[1];
}
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < dataDir.listFiles().length; i++) {
File[] files = dataDir.listFiles();
executorService.execute(new DataImportTask(files[i].getAbsolutePath() , tableName, jdbcTemplate));
}
}
}
class DataImportTask implements Runnable{
private JdbcTemplate jdbcTemplate;
private String fileFullPath;
private String tableName;
public DataImportTask(String fileFullPath, String tableName, JdbcTemplate jdbcTemplate) {
this.fileFullPath = fileFullPath;
this.tableName = tableName;
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void run() {
String sql = "load data infile '"+ fileFullPath + "' ignore into table " + tableName +" character set 'utf8' " +
"fields terminated by ',' " + // 分割符
"optionally enclosed by '\"' " +
"lines terminated by '\\n'" + // 行结束符
"(ID,DATA_SOURCE,DATA_SOURCE_ID,ISBN,TITLE,IMG,BRIEF,PUBLISH_NAME,AUTHOR,PUBLISH_TIME,PRICE,BOOK_CLC_CODE,CURRENCY,CREATE_TIME,UPDATE_TIME,HAS_MARC,MIS_NO)"; //字段定义
jdbcTemplate.execute(sql);
}
}
第四步:调回第三步设置参数
第五步:拷贝数据到其它节点
六、大数据归档
归档数据使用的存储引擎
TokuDB现属于Percona公司旗下的MySQL存储引擎,它拥有高压缩比,默认使用zlib进行压缩,尤其是对字符串(varchar,text等)类型有非常高的压缩比,比较适合存储日志、原始数据等。 且在线添加索引,不影响读写操作 ,支持完整的ACID特性和事务机制。安装
- 第一步:确认安装
jemalloc
yum install -y jemalloc
- 第二步:修改my.cnf,并重启服务
[mysqld_safe]
malloc-lib=/usr/lib64/libjemalloc.so.1
- 第三步:开启Linux大页内存
# 大页内存管理可以动态分配内存
echo never > /sys/kernel/mm/transparent_hugepage/enabled
# 开启内存的碎片整理
echo never > /sys/kernel/mm/transparent_hugepage/defrag
- 安装TokuDB
yum install -y Percona-Server-tokudb-57.x86_64
ps-admin --enable -uroot -p
service mysql restart
ps-admin --enable -uroot -p
- 查看安装结果
show engines;
归档数据搭建Replication集群和高可用
创建和PXC集群表结构一样的归档表,只需将存储引擎改为TokuDB
使用pt-archiver归档数据
安装
wget https://www.percona.com/downloads/percona-toolkit/....rpm
yum localinstall -y percona-toolkit....rpm
执行归档
pt-archiver --source h=[sourceIP],P=[sourcePort],u=[user],p=[password],D=[database],t=[table] \
--dest h=[destIP],P=[destPort],u=[user],p=[password],,D=[database],t=[table] --no-check-charset --where '[where后的条件]' --progress 5000 --bulk-delete --bulk-insert --limit=10000 --statistics
如果字符集乱码需要配置
[client]
default-character-set=utf8
七、数据库的冷热备份
dump是将数据导出成为SQL文件,导出的SQL文件不能作为MySQL的数据文件,需要先导入MySQL。
MySQL文件
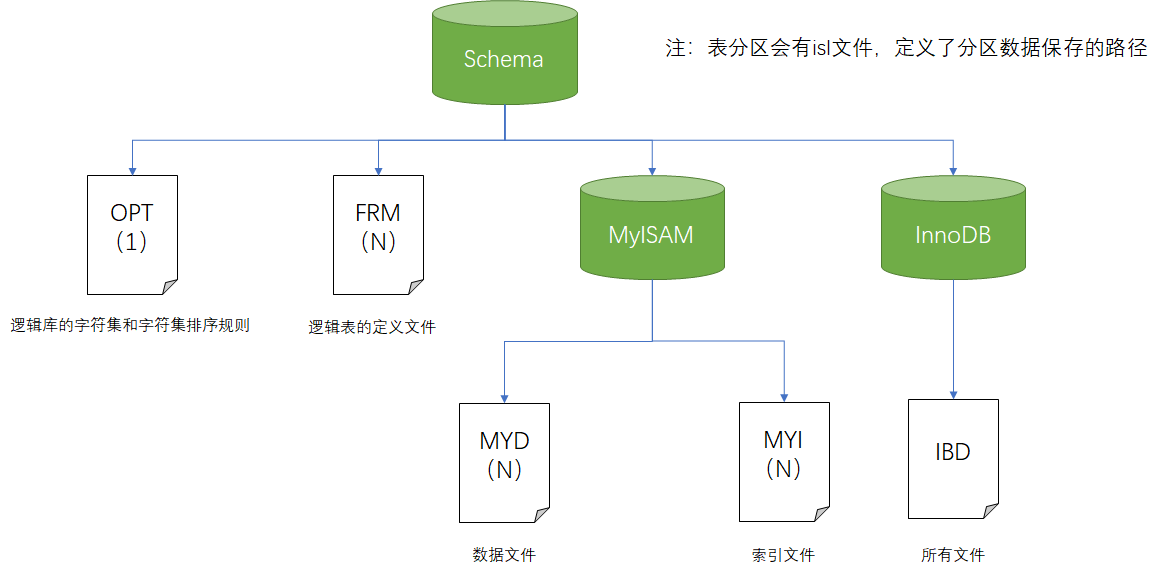
| 文件名 | 描述 |
|---|---|
| auto.cnf | 文件,记录了服务器的UUID值,数据还原的时候需要注意,如果没有auto.cnf文件MySQL启动会自动创建 |
| grastate.dat | 文件里保存的是PXC的同步信息 |
| gvwstate.dat | 文件里保存的是PXC集群节点信息 |
| err | 错误日志文件 |
| pid | 进程id文件 |
| ib_buffer_pool | InnoDB缓存文件 |
| ib_logfile | InnoDB事务日志 |
| ibdata | InnoDB共享表空间文件 |
| logbin | 日志文件 |
| index | 日志索引文件 |
| ibtmp | 临时表空间文件 |
文件碎片
向数据表写入数据,数据文件的体积会增大,但是删除数据的时候数据文件的体积并不会减小,数据被删除后留下的空白被称作碎片。向再次数据表插入数据会优先使用碎片空间。
碎片整理
ALTER TABLE tableName ENGINE=InnoDB;
冷备份介绍
- 被备份的数据库必须停机
- 备份非常占用空间(全量备份),不支持增量备份
- 冷备份的是所有数据文件和日志文件,所以无法按照逻辑库和数据表备份数据
联机冷备份
第一步:PXC节点退出集群
- 关闭服务
- 注释掉PXC节点配置
第二步:使用java作数据库的表碎片整理
注意:在做此操作前必须禁止二进制日志记录,否则重新上线节点会引发PXC集群做碎片整理,导致锁表。
# /etc/my.cnf注释掉一下行,不进行日志记录
# log-bin
# log-slave-update
@SpringBootApplication
public class OptimizeTables implements ApplicationListener<ApplicationReadyEvent>{
static private Logger logger = LoggerFactory.getLogger(OptimizeTables.class);
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private ConfigurableApplicationContext applicationContext;
public static void main(String[] args) {
SpringApplication.run(OptimizeTables.class, args);
}
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
List<String> tableNames = jdbcTemplate.queryForList("show tables", String.class);
for (String tableName : tableNames) {
jdbcTemplate.execute("ALTER TABLE " + tableName + " ENGINE = Innodb");
logger.info("表【{}】碎片整理完成", tableName);
}
logger.info("碎片整理全部完成。。。准备关闭容器");
}
}
第三步:备份文件
# 如果有表分区,也要备份表分区数据
tar -cvf mysql.tar /var/lib/mysql
第四步:节点重新上线
- 恢复配置文件
- 根据节点情况启动
还原节点,只需要覆盖mysql的数据目录
热备份介绍
- 数据库在不停机的状况下备份
-
备份数据时会加读锁,数据在此期间只能读不能写
- 支持(首次)全量备份和增量备份
XtraBackup联机热备份
XtraBackup是一种物理备份工具,通过协议连接到MySQL服务端,然后读取并复制底层的文件,完成物理备份。
- XtraBackup备份过程中InnoDB不加锁,MyISAM加读锁,数据可读不可写
- XtraBackup备份过程不会打断正在执行的事务
- XtraBackup能够基于压缩等功能节约硬盘的空间
- XtraBackup支持对InnoDB引擎做全量和增量备份
- XtraBackup只能对MyISAM做全量备份
XtraBackup命令种类
| 命令 | 解释 |
|---|---|
| xbcrypt | 用于加密或解密备份的数据 |
| xbstream | 用于压缩或者解压xbstream文件 |
| xtrabackup | 备份InnoDB数据表 |
| innobackupex | 上述三种命令的脚本封装 |
XtraBackup命令处理流程
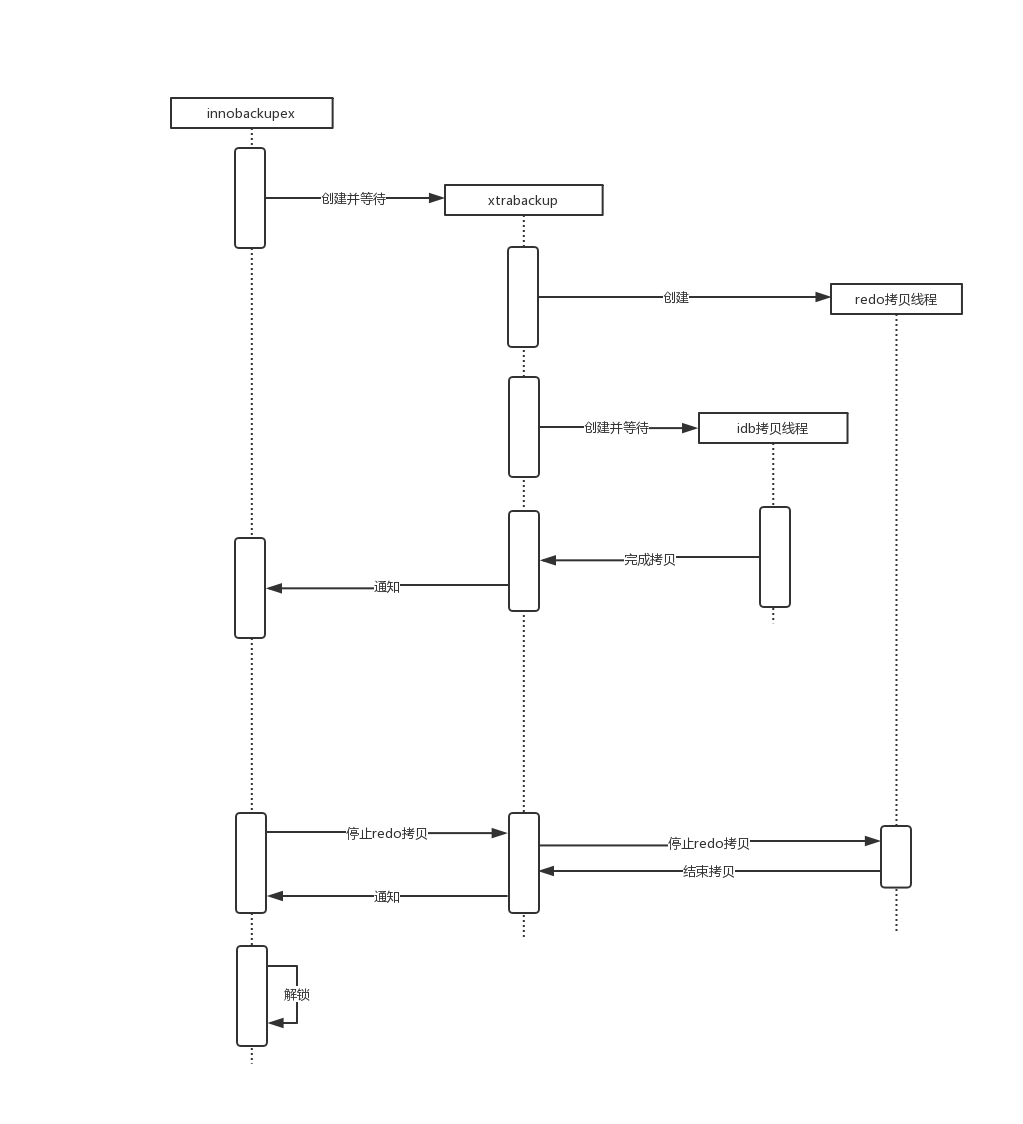
XtraBackup全量热备份
# 不压缩、不加密,备份出来是一个文件夹
innobackupex --default-file=/etc/my.cnf \
--host=[ip] \
--user=[user] \
--password=[password] \
--port=[port] \
[dir]
# 压缩、加密,备份出是个文件,需要解密才可使用
# 可使用--include正则表达式或者表名逗号分割标识要备份的库
innobackupex --default-file=/etc/my.cnf \
--host=[ip] \
--user=[user] \
--password=[password] \
--port=[port] \
--stream=xbstream \
--no-timestamp \
--encrypt=[AES256,AES128] \
--encrypt-threads=8 \
--encrypt-key=[24位密码] \
--compress \
--compress-thread=8 \
--galera-info -> [path/file.xbstream]
可使用crontab定时进行全量热备份
XtraBackup全量冷还原
第一步:关闭MySQL服务,清空数据目录(包括表分区目录)
第二步:创建临时解压目录
第三步:解压&解密
xbstream -x <[xbstreamFileName] -C [dir]
innobackupex --decompress --decrypt=[AES256,AES128] --encrypt-key=[key] [dir]
第四步:回滚备份文件未提交的事务,同步备份文件已提交的事务到数据文件
innobackupex --apply-log [/path/dirname]
第四步:执行还原操作
innobackupex --default-file=/etc/my.cnf --copy-back [/path/dirname]
第五步:修改还原的文件所属信息
chown -R mysql:mysql /var/lib/mysql
第六步:已主节点身份启动
第七步:重启其它节点
XtraBackup增量热备份
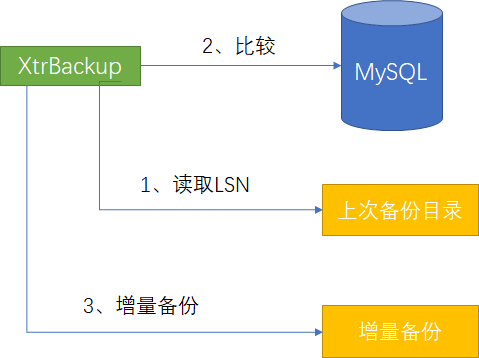
# 不压缩、不加密,备份出来是一个文件夹
innobackupex --default-file=/etc/my.cnf \
--host=[ip] \
--user=[user] \
--password=[password] \
--port=[port] \
--incremental-basedir=[上次全量备份或增量备份目录,压缩的全量备份需要解压] \
--incremental [incrementDir]
# 压缩、加密,备份出是个文件,需要解密才可使用
innobackupex --default-file=/etc/my.cnf \
--host=[ip] \
--user=[user] \
--password=[password] \
--port=[port] \
--incremental-basedir=[上次全量备份或增量备份目录,压缩的全量备份需要解压] \
--incremental [incrementDir] \
--compress \
--compress-thread=8 \
--encrypt=[AES256,AES128] \
--encrypt-key=[24位密码] \
--stream=xbstream ./ > [path/file.xbstream]
java定时增量热备份
@SpringBootApplication
@EnableScheduling
public class IncrementBackup implements CommandLineRunner {
static private Logger logger = LoggerFactory.getLogger(IncrementBackup.class);
private String configPath;
@Autowired
private ConfigurableApplicationContext applicationContext;
public static void main(String[] args) {
SpringApplication.run(IncrementBackup.class, args);
}
@Override
public void run(String... args) throws Exception {
if(args == null || args.length == 0) {
logger.error("请指定配置文件位置");
applicationContext.close();
} else {
configPath = args[0];
logger.info("加载配置文件[{}]", configPath);
}
}
// 这个需要调整时间
@Scheduled(cron = "0 */2 * * * ?")
public void incrementScheduling() throws IOException {
Yaml yaml = new Yaml();
InputStream configInputStream=new FileInputStream(configPath);
//读入文件
Map<String,String> content= (Map) yaml.load(configInputStream);
configInputStream.close();
String host = content.get("host");
String user = content.get("user");
String password = content.get("password");
String port = content.get("port");
String baseDir = content.get("baseDir");
String incrementDir = content.get("incrementDir");
String folderName = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"));
String shellCmd = "innobackupex --default-file=/etc/my.cnf " +
"--host={0} " +
"--user={1} " +
"--password={2} " +
"--port={3} " +
"--incremental-basedir={4} " +
"--no-timestamp " + //不再在生成一个时间文件夹包裹备份文件
"--incremental {5}";
shellCmd = MessageFormat.format(shellCmd, host, user, password, port, baseDir, incrementDir + File.separator + folderName);
logger.info("shellCmd : {}", shellCmd);
Runtime.getRuntime().exec(shellCmd);
content.put("baseDir", incrementDir + File.separator + folderName);
Writer writer = new FileWriter(configPath);
yaml.dump(content, writer);
writer.close();
}
}
host: '[ip]'
user: '[user]'
password: '[password]'
port: '[port]'
baseDir: '[beforeBackupDir]'
incrementDir: '[BackupDir]'
XtraBackup增量热备份冷还原
# 全量备份处理
innobackupex --apply-log --redo-only [全量备份目录]
# 第一次到N-1次增量备份
innobackupex --apply-log --redo-only [全量备份目录] --incremental-dir=[增量备份目录]
# 第N次增量备份
innobackupex --apply-log [全量备份目录] --incremental-dir=[最后一次增量备份目录]
# 还原
innobackupex --default-file=/etc/my.cnf --copy-back [全量备份目录]
chown -R mysql:mysql /var/lib/mysql