MySQL数据库性能及其架构优化
一、安装MySQL
Yum源下载方式
预备工作
yum -y install yum-utils #安装yum-utils
第一步:下载yum源
在官网选择Downloads–»Community (GPL) Downloads –»MySQL Yum Repository最新yum源
第二步:安装yum源
yum localinstall mysqlxx-community-release-版本号.rpm #安装yum信息
yum repolist all | grep mysql #查看默认安装信息
yum-config-manager --disable mysql80-community #禁用mysql80
yum-config-manager --enable mysql57-community #启用mysql57
yum repolist enabled | grep mysql #查看是否正确
第三步:安装mysql
yum install -y mysql-community-server
第四步:启动mysql服务
systemctl start mysqld
第五步:登陆mysql
mysql初始化root密码在log文件中,使用more /etc/my.cnf查看日志文件位置(默认/var/log/mysqld.log)
第六步:修改root密码
alter user 'root'@'localhost' identified by 'root'; -- 没有修改密码策略会提示密码复杂度不够
第七步:开放root远程登陆权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '[newpwd]' WITH GRANT OPTION;
flush privileges;
注:测试环境下可以修改密码策略
set global validate_password_policy=0; -- 设置检查策略为最低0和LOW一样
set global validate_password_length=1; -- 设置密码长度最少为1(实际上mysql会设置为4)
show variables like '%password%'; -- 查看密码相关信息
二、操作系统性能优化
内核相关参数设置(/etc/sysctl.conf)
#############################################################
# 以下参数使用 sudo cat /proc/sys/x/y/z格式可以查看系统当前值 #
# 如:sudo cat /proc/sys/net/core/somaxconn #
#############################################################
# 默认值是128(系统中每个端口最大监听队列长度),对于负载大的服务远不够。一般会将它修改为2048或者更大
net.core.somaxconn = 2048
# 每个网络接口接收数据包的速率比内核处理这些包的速率快时,缓冲队列的数据包的最大数目,默认值为1000
net.core.netdev_max_backlog = 2000
# 尚未收到客户端确认信息的连接请求的最大值(排队握手值,默认128)
net.ipv4.tcp_max_syn_backlog = 2048
# tcp连接默认的timeout时长,默认60
net.ipv4.tcp_fin_timeout = 10
# 更快的回收套接字,默认0
net.ipv4.tcp_tw_recycle = 1
# 允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0
net.ipv4.tcp_tw_reuse = 1
# 默认TCP数据发送窗口大小,默认229376(字节)
net.core.wmem_default = 256960
# 最大TCP数据发送窗口大小,默认229376(字节)
net.core.wmem_max = 16777216
# 默认TCP数据接收窗口大小,默认229376
net.core.rmem_default = 256960
# 最大TCP数据接收窗口大小,默认229376(字节)
net.core.rmem_max = 16777216
# TCP发送keepalive消息的时间间隔,默认7200
net.ipv4.tcp_keepalive_time = 120
# 探测消息未获得响应时,重发该消息的时间间隔,默认75
net.ipv4.tcp_keepalive_intvl = 30
# 认定TCP连接失败失效之前,最多发送多少keepalive消息,默认9
net.ipv4.tcp_keepalive_probes = 3
# 单个共享内存段的最大值。这个值应该设置足够大,便于一个共享内存段可以容纳整个innodb缓冲池大小
# 建议设置为物理内存一半
kernel.shmmax = 17179869184
# swappiness的值越大,表示越积极使用swap分区,为0表示除非内存满了才使用。默认值swappiness=60
vm.swappiness = 0
使用 sysctl -p使之生效
资源文件设置(/etc/security/limits.conf)
#<domain> <type> <item> <value>
mysql hard nofile 65535 #设置mysql可打开文件数
mysql soft nofile 65535
需重启生效
磁盘调度策略
- cfq:完全公平调度策略,桌面级系统较为合适
- noop: 电梯式调度程序 ,FIFO队列,它像电梯的工作主法一样对I/O请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一介质
- deadline:截至时间调度策略,这个截止时间是可调整的,而默认读期限短于写期限.这样就防止了写操作因为不能被读取而饿死的现象[适合mysql]
echo deadline > /sys/block/[devName]/queue/scheduler修改调度策略
文件系统选择
Linux提供的EXT3、EXT4、XFS文件系统均具有日志功能,可保证数据安全。其中属XFS性能最高。 df -T查看文件系统格式
如果是EXT3/EXT4可进行以下优化(/etc/fastab)
# noatime 禁止记录访问时间
# nodirname 禁止记录目录时间
# data
# wirteback 仅写入元数据–innodb最好
# ordered 写元数据和数据
# journal 先计入日志
/dev/[devName]/ext4 noatime,nodirname,data=wirteback 1 1
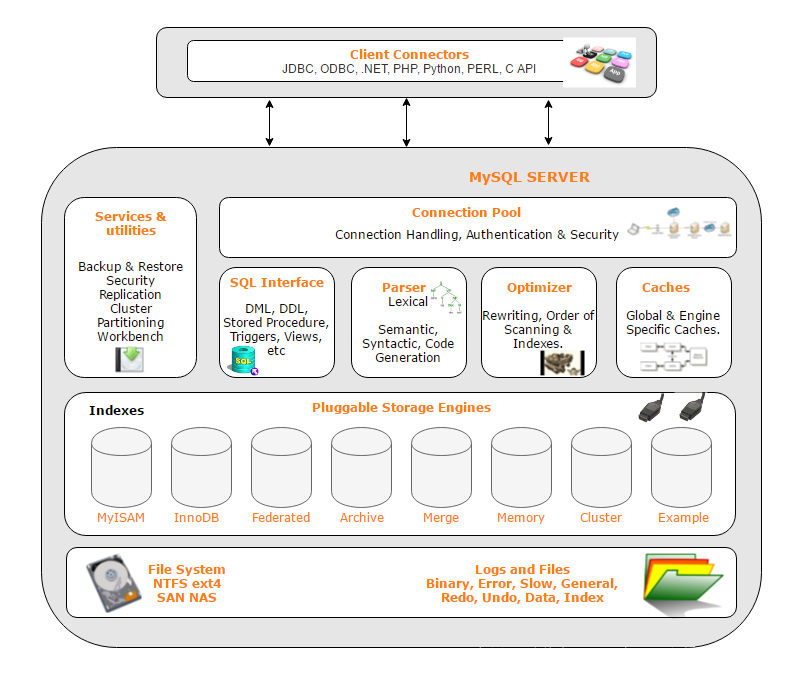
三、MySQL存储引擎的选择
MyISAM存储引擎
MyISAM是MySQL5.5之前版本所使用的默认存储引擎,也是现在系统表、临时表(排序、分组操作中当数量超过一定大小,由查询优化器建立的临时表)所使用的存储引擎。
数据文件:MyISAM表的存储文件有特有的两种,分别是.myd[存储数据]、.myi[存储索引]
MyISAM特性
-
表级锁(共享读锁,互斥写锁)
- 不支持事务
- 支持全文索引,以及text、blob前500字节建立索引。在5.7之前innodb不支持
- 支持数据压缩【单行压缩,不用整表解压】, 表变为只读,不能进行写操作
myisampack -f [tableName].myi
- 表支持数据恢复操作
- MySQL终端使用
check table [tableName]检查表是否损坏 - MySQL终端使用
repair table [tableName]修复表 - 系统终端使用
myisamchk -im /path/[tableName].myi检查表是否损坏 - 系统终端使用
myisamchk -iBfqr /path/[tableName].myi快速修复表(必须停止MySQL服务 ) - 系统终端使用
myisamchk -iBfqo /path/[tableName].myi能修复r不能修复的情况(必须停止MySQL服务 )
- MySQL终端使用
MyISAM应用场景
- 非事务型应用(报表类切不涉及财务要求读取性能高)
- 只读
- 空间类应用(在5.7之前只有MyISAM支持空间函数等)
InnoDB存储引擎
InnoDB是MySQL5.5之后版本所使用的默认存储引擎,支持事务、适用于小而多的事务场景。
数据文件:Innodb表只有一种特有格式ibd[索引、数据]
Innodb表空间进行数据存储的选择
[mysqld]
innodb_file_per_table=1 #开启独立表空间,存储文件为[tableName].idb
innodb_file_per_table=0 #关闭独立表空间,使用系统表空间,存储文件为ibdate[num]
独立表空间&系统表空间
-
MySQL5.6之前默认使用系统表空间,5.6及其之后默认使用独立表空间
-
系统表空间无法简单的收缩文件大小,大量并发还会产生IO瓶颈
- 独立表空间可以通过
optimize table [tableName]命令(会锁表)重新利用未使用的空间,并整理数据文件的碎片 - 独立表空间可以同时向多个文件刷新数据,支撑大量IO并发
InnoDB引擎特性
- 完全支持事务的ACID特性
- 具有Redo Log日志[记录已提交的事务],Undo Log日志[记录未提交的事务,需要随机读写]
- 支持行级锁【间隙锁】,可以支持并发操作
- 可使用
show engine innodb status【间隔采样,最少使用2次】采集相关引擎运行状态信息
适用场景
- 需要事务
- 需要大量并发写入、读取
CSV存储引擎
CSV存储引擎将数据以文本的方式存储在文件中,可以直接打开文件进行查看。
数据文件:CSV表的存储文件有特有的两种,分别是.csv[存储数据]、.csm[存储元数据如表的状态和数据量]
CSV引擎特点
-
以CSV格式进行数据存储
-
所有列的都不能为NULL
-
不支持索引【不适合大表,不适合在线处理】
-
支持对数据文件直接编辑【编辑之后用flush tables刷新表才可见编辑变化】
-
定义数据表是必须显示指出列不为空否则会报出以下异常
The storage engine for the table doesn't support nullable columns
适用场景
- 适合作为数据交换的中间表【可随时拷入、拷贝文件】
Archive存储引擎
数据文件:CSV表的存储文件有特有的一种.arz[存储数据]
Archive存储引擎特点
- 以zlib对表数据进行压缩,磁盘IO更少
- 只支持insert和select操作【支持行级锁和特定缓冲区但不支持事务,可大并发插入】
- 只允许在自增ID上建立索引
适用场景
- 日志和数据采集类应用
Memory存储引擎
Memory存储引擎是MySQL在创建临时表(排序、分组操作中时由查询优化器建立的临时表,Memory不满足条件时使用MyISAM作为临时表引擎)所使用的存储引擎。
Memory存储引擎特点
- 所有数据都存在于内存中,重启MySQL数据丢失,表定义不丢失(
.frm文件是在系统文件中) - 支持HASH和BTREE索引
- 所有字段都是固定长度(varchar(10) = char(10))
- 不支持BLOG和TEXT大字段
- 使用表级锁【影响并发】
适用场景
- 用于查找或者映射表(支持HASH索引)
- 用于保存数据分析中产生的中间表
- 用于缓存周期性聚合数据的结果表
Federated存储引擎
Federated存储引擎提供了访问远程MySQL 服务器上表的方法,且在本地并不存储数据,数据全部在远程服务器上,但是本地需要保存表结构信息和远程服务器信息(.frm文件依旧存在)。Federated引擎效率并不高,默认禁止。
开启Federated存储引擎
在MySQL配置文件[mysqld]中加入federated = 1
使用方法
1)远程服务器创建用户并授权
CREATE USER '[username]'@'[host]' IDENTIFIED BY '[password]';
GRANT PRIVILEGES ON delete,update,insert,select [database].[tablename] TO '[username]'@'[host]'
2 )本地服务器创建表结构要与远程服务器表结构一致,且加入
create table [tablename] (
...
) ENGINE =FEDERATED CONNECTION='mysql://username:password@host:port/database/table';
适用场景
- 偶尔的统计分析及手工查询
四、MySQL服务参数配置
可以使用mysqld --help --verbose | grep -A 1 'Default options'查看MySQL读取配置文件的顺序,后读取的配置信息会覆盖前配置的信息。
配置参数的作用域设置
- 全局参数
- set global 参数名 = 参数值;
- set @@global.参数名 := 参数值;
- 会话参数
- set [session] 参数名 = 参数值;
- set @@session.参数名 := 参数值;
内存相关参数
线程级别
-
sort_buffer_size:每个线程进行排序操作时创建,每次创建这个数值的全部内存,默认1M,不建议改动
-
join_buffer_size:每个查询语句进行一次join分配一个,多次分配多个。大量join操作可以适当调大
-
read_bufer_size:MyISAM进行全表扫描时创建这个数值的全部内存,如果修改应该为4k倍数
-
read_rnd_buffer_size:MyISAM索引使用,按需分配不是一次使用全部数值内存
进程级别
- Innodb_buffer_pool_size:InnoDB所用缓冲池大小包含InnoDB数据页、索引数据、缓冲数据、 内存中修改尚未刷新(写入)到磁盘的数据 以及 如自适应哈希索引,行锁等。 默认大小为128M,如果只使用InnoDB引擎建议设置为系统物理内存70%
- key_buffer_size:MyISAM所用缓冲池大小只包含索引数据, 如果很少使用MyISAM表,也要保留16-32MB 的 key_buffer_size 以适应给予磁盘的临时表索引所需
I/O相关参数
Redo log相关
-
Innodb_log_file_size
-
Innodb_log_files_in_group
redo日志先写到缓冲区再写到日志文件每秒刷盘,所以日志文件不需要太大。Innodb_log_files_in_group决定了日志文件个数,日志时先满一个才使用下一个并非并行使用,所以此值不重要。
-
innodb_flush_log_at_trx_commit:刷新事务日志的频繁程度
-
0:每秒进行一次log写入操作系统cache,并立即flush log到磁盘,宕机或MySQL崩溃可能丢失1s事务数据。
-
1【默认】:每次事务提交时执行log写入cache,并立即flush log 到磁盘,不会丢失任何事务数据。
-
2:每次事务提交时执行log写入cache,并每秒执行flush log 到磁盘 ,mysql进程奔溃不会丢失,服务器宕可能会事务数据。如果有需要可以开启此选项。
-
-
innodb_flush_method:建议设置为
O_DIRECT,不缓存,不预读,避免操作系统和mysql双缓存 -
innodb_file_per_table:建议设置为1,独立表空间,使用系统表空间【5.6及其以后默认为1】
-
innodb_doublewrite:建议设置为1,避免页没写完整导致数据损坏,增加数据安全。默认为1
-
delay_key_write:类似innodb_flush_log_at_trx_commit
- OFF:关闭延迟写入,直接刷盘到磁盘
- ON:只对建表时使用的了delay_key_write选项的表进行延迟写入
- 对所有MyISAM表都使用延迟写入
安全相关参数
-
expire_log_days:指定自动清理binlog的天数,至少两次全备时间,如果每天全备也应该保存7天以上
-
max_allowed_packet:控制可以接收最大的包的大小和用户定义变量的最大容量(主从模式下应该一样),建议32M
-
skip_name_resolve:禁用DNS查找,如果需要通过主机名连接,建议配置在host文件中
-
当有一个新的客户端连接进来时,MySQL Server会为这个IP在host cache中建立一个新的记录,包括IP,主机名和client lookup validation flag,分别对应host_cache表中的IP,HOST和HOST_VALIDATED这三列。第一次建立连接因为只有IP,没有主机名,所以HOST将设置为NULL,HOST_VALIDATED将设置为FALSE。
-
MySQL Server检测HOST_VALIDATED的值,如果为FALSE,它会试图进行DNS解析,如果解析成功,它将更新HOST的值为主机名,并将HOST_VALIDATED值设为TRUE。如果没有解析成功,判断失败的原因是永久的还是临时的,如果是永久的,则HOST的值依旧为NULL,且将HOST_VALIDATED的值设置为TRUE,后续连接不再进行解析,如果该原因是临时的,则HOST_VALIDATED依旧为FALSE,后续连接会再次进行DNS解析。
-
解析成功的标志并不只是通过IP,获取到主机名即可,这只是其中一步,还有一步是通过解析后的主机名来反向解析为IP,判断该IP是否与原IP相同,如果相同,才判断为解析成功,才能更新host cache中的信息。
-
-
sysdata_is_now:设置为1,确保sysdate()返回确定性日期。 如果主从使用了binlog的
statement模式,sysdata的结果会不一样,最后导致数据不一致 -
read_only:禁止非super权限用户的写权限,主从模式下建议从机开启
-
skip_slave_start:禁用slave自动恢复,当从机恢复工作时,先不启动从属模式,检查完成后,手动启动较好
-
sql_model:MYSQL所使用的SQL模式,默认为宽松模式
- strict_trans_tables: 严格模式,非法数据值被拒绝
- no_engine_subtitution: 严格模式下建表的时候指定不可用存储引擎会报错
- no_zero_data: 严格模式不接受’0000-00-00’作为合法日期
- no_zero_in_data: 严格模式不接受月或日部分为0的日期
- only_full_group_by: 严格模式下检验
group by语句的合法性
其它相关参数
- sync_binlog:控制MySQL如何向磁盘刷新binlog
- 0默认, 事务提交由操作系统决定刷盘时间,这时候的性能是最好的,但是风险也是最大的
- 大于0, 事务提交两次刷盘的间隔多少次写操作,主服务最好应该是1(最多可能丢失1个事务的数据)
-
tmp_table_size和max_heap_table_size:控制内存临时表大小(Memeory引擎创建),超过变为文件临时表(MyISAM引擎创建)
- max_connections:控制允许的最大连接数,默认100,建议2000+
五、MySQL基准测试
基准测试的定义
基准测试是一种测量和评估软件性能指标的活动用于建立某个时刻的性能基准,以便当系统发生软硬件变化时重新进行基准测试以便评估变化对系统性能的影响
常见测试指标
- 单位时间内所处理的事务数(TPS)
- 单位时间内所处理的查询数(QPS)
-
响应时间( RT )
- 系统同时能处理的请求数量(并发数)
- 单位时间内系统能处理的请求数量 (吞吐量 )
sysbench做基准测试
sysbench是一个模块化的、跨平台、多线程基准测试工具,主要用于评估测试各种不同系统参数下的数据库负载情况 。具有以下功能:
1、cpu性能测试
2、磁盘io性能测试
3、调度程序性能测试
4、内存分配及传输速度测试
5、POSIX线程性能测试
6、数据库性能(OLTP基准测试)
安装sysbench
- 标准目录安装
./configure && make && make install
strip /usr/local/bin/sysbench
- 非标准目录安装
# 需要先yum install mysql-devel
./configure --with-mysql-includes=/usr/include/mysql --with-mysql-libs=/usr/lib64/mysql && make && make install
开始测试
0)查看各项测试帮助
# 使用 sysbench --test=<name> help
# testname:fileio、cpu、memory、threads、mutex、oltp
# 如:sysbench --test=fileio help
1)cpu性能测试
# 主要是进行素数的加法运算
sysbench --test=cpu --cpu-max-prime=20000 run
2)线程测试
sysbench --test=threads --num-threads=64 --thread-yields=100 --thread-locks=2 run
3)磁盘IO性能测试
# 会生成测试文件,准备测试
sysbench --test=fileio --file-total-size=3G --file-test-mode=rndrw prepare
# 开始测试
sysbench --test=fileio --num-threads=16 --file-test-mode=rndrw run
# 删除测试文件
sysbench --test=fileio cleanup
4)内存测试
# 内存中传输200M的数据量,每个block大小为8K,单位注意大写
sysbench --test=memory --memory-block-size=8K --memory-total-size=200M run
5)OLTP测试
# 准备测试,更多参数运行帮助命令
sysbench --test=oltp --mysql-table-engine=innodb --thread=8 --oltp-table-size=10 --oltp-table-size=1000000 --mysql-user=root --mysql-password=123456 --mysql-db=ttt --mysql-host=localhost prepare
# 运行测试,更多参数运行帮助命令
sysbench --test=oltp --mysql-table-engine=innodb --thread=8 --oltp-table-size=10 --oltp-table-size=1000000 --mysql-user=root --mysql-password=123456 --mysql-db=ttt --mysql-host=localhost run
# 清理测试数据
sysbench --test=oltp --mysql-table-engine=innodb --thread=8 --oltp-table-size=10 --oltp-table-size=1000000 --mysql-user=root --mysql-password=123456 --mysql-db=ttt --mysql-host=localhost cleanup
六、MySQL压力测试
tpcc-mysql是Percona基于tpcc规范衍生的产品,专用于MySQL的压力测试,对SQL的执行时间有严格要求。
安装tpcc-mysql
前置条件:安装mysql-devel
第一步:下载
第二步:编译
cd src; make
第三步:取出$tpcc-mysql目录下的sql[create_table.sql、add_fkey_idx.sql]文件
第四步:创建一个空数据库,并执行create_table.sql、add_fkey_idx.sql
第五步:执行创建数据操作
$tpcc-mysql/tpcc_load -h [ip] -d [databaseName] -u [user] -p [password] -w [num]
-w 指的是数据模型中仓库的数量
第六步:执行压力测试
$tpcc-mysql/tpcc_start -h [ip] -d [databaseName] -u [user] -p [password] -w [num] -c [num] -r [num] -l [num] > result.log
-c 指的是并发线程数
-r 数据库预热时间
-l 测试时间
例如:/tpcc_start -h 192.168.1.152 -d tpcc -u root -p 123456 -w 1 -c 5 -r 300 -l 600 > result.log
pxc集群使用tpcc-mysql进行压力测试需要更改配置文件
pxc_strict_mode=DISABLED
七、数据库结构设计
数据库设计范式
数据库设计第一范式
- 数据库表中的所有字段都只具有单一属性
-
单一属性的列是由基本的数据类型所构成的
- 设计出来的表都是简单的二维表
数据库第二范式
- 要求表中只具有一个业务主键,也就是说符合第二范式的表不能存在非主键列只对部分主键的依赖关系
数据库第三范式
- 每一个非主属性既不部分依赖也不传递依赖于业务主键
数据库物理设计
表中的列选择数据类型
当一个列可以选择多种数据类型时,应该首先考虑数字类型,其次是日期或二进制类型,最后是字符串类型。对于相同级别的数据类型,应该优先选择占用空间小的数据类型。
- 整数类型
| 列类型 | 存储空间 | 范围 |
|---|---|---|
| tinyint | 1字节 | -127 ~ 128 |
| smallint | 2字节 | -32768 ~ 32767 |
| mediunmit | 3字节 | -8388608 ~ 8388607 |
| int | 4字节 | -2147483648 ~ 2147483647 |
| bigint | 8字节 | -9223372036854775808 ~ 9223372036854775807 |
- 实数类型
| 列类型 | 存储空间 | 是否精确 |
|---|---|---|
| float | 4字节 | 否 |
| double | 8字节 | 否 |
| decimal | 每4个字节存9个数字,小数点占一个字节 | 是 |
注:
column_name DECIMAL (P,D);1)
P是表示有效数字数的精度。P范围为1〜652)
D是表示小数点后的位数。D的范围是0~30。MySQL要求D小于或等于(<=)P如
amount DECIMAL(6,2);amount列最多可以存储6位数字,小数位数为2位; 因此,amount列的范围是从-9999.99到9999.99
-
varchar和char类型【单位是字符】
- varchar的存储
- varchar用于存储变长字符串,只占用必要的存储空间
- 列的最大长度小于255则只占用一个额外字节用于记录字符串的长度
- 列的最大长度大于255则只占用两个额外字节用于记录字符串的长度
- varchar的适用场景
- 最大长度比平均长度大的多的字符串列
- 很少被更新的字符串列
- 使用了多字节字符集存储的字符串
- char的存储
- 定长存储
- 字符串存储再char类型的列中会自动删除末尾的空格
- 最大宽度255
- char的适用场景
- 存储长度近似的字符串
- 长度较短的字符串
- 经常被更新的字符串列
- varchar的存储
-
日期类型
datetime类型
以
YYYY-MM-DD HH:MM:SS[.fraction]格式存储日期时间-
datetime=
YYYY-MM-DD HH:MM:SS - datetime(6) =
YYYY-MM-DD HH:MM:SS[.fraction] - datetime类型与时区无关,占用8个字节的存储空间
timestamp类型
存储了由格林尼治时间1970年1月1日到当前时间的秒数,以
YYYY-MM-DD HH:MM:SS[.fraction]显示- 类型显示依赖所指定的时区,占用4个字节
- 行数据修改时可自动修改timestamp列的值
date类型和time类型
- date类型只占用3个字节、并且可以使用日期函数进行计算
- time类型用于存储时间类型,格式为
HH:MM:SS
-
不要使用字符串类型来存储日期时间数据
分区表的使用
分区是将一个表的数据按照某种方式,比如按照时间上的月份,分成多个较小的,更容易管理的部分,但是逻辑上仍是一个表(物理已经被拆分)。
分区表的限制因素
- 一个表最多只能有1024个分区
-
如果分区字段中有主键或者唯一索引的列,那么主键列和唯一索引列都必须包含它。即:分区字段要么不包含主键或者唯一索引列,要么包含全部主键和唯一索引列
- 分区表中无法使用外键约束
分区表物理是分区的,但逻辑上是一个表。如果分区表没有主键和唯一索引,则不需要判断键重复。如果分区表存在主键或者唯一索引而分区字段不是它,则需要判断别的分区是否存在键冲突,MySQL不支持。
分区类型
(1)RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
(2)LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
(3)HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
(4)KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
-- 数字范围分区
create table employees(
id int primary key,
fname varchar(30),
lname varchar(30),
hired date not null,
entryDate date not null
) engine=innodb charset=utf8
partition by range(id)( -- 分区字段为主键没问题
partition p0 values less than (1000),
partition p1 values less than (2000),
partition p2 values less than (3000),
partition p3 values less than (4000),
partition p4 values less than MAXVALUE
);
-- list分区
create table employees(
id int not null, -- 如果id为主键则存在问题
fname varchar(30),
lname varchar(30),
hired date not null,
entry_date date not null,
status SMALLINT not null
) engine=innodb charset=utf8
partition by list (status)(
partition pNotJob values in (1), -- 1:离职
partition pWillJob values in (2,3), -- 2:面试中,3:面试通过待入职
partition pOnJob values in (4,5), -- 4:合同工,5:临时工
partition pHelpJob values in (6) -- 6:兼职
);
-- hash分区
create table employees(
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null,
entry_date date not null,
status SMALLINT not null
) engine=innodb charset=utf8
partition by hash(year(entry_date))
partitions 4;
-- key分区不能在使用year等函数,会报错
create table employees(
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null,
entry_date date not null,
status SMALLINT not null
) engine=innodb charset=utf8
partition by key(entry_date)
partitions 4;
八、主从模式
MySQL二进制日志
记录了所有MySQL数据库的修改成功的事件(包括增删改事件和对表结构的修改时间)
开启二进制日志
[mysqld]
server-id=1 #每台机器server-id均要不同
log-bin=mysql-bin #二进制日志的名称前缀
查看二进制日志
# 查看段格式复制
mysqlbinlog -vv mysql-bin.000001
# 查看行格式复制
mysqlbinlog mysql-bin.000001
二级制日志格式
-
基于段的格式binlog_format=STATEMENT【5.7之前默认使用】就是记录增删改的SQL语句
优点:日志记录量相对较小,节约磁盘/网络IO【如果是只对一条记录修改或插入row格式的日志量更小】
缺点:对
UUID()类似不确定结果的函数从服务器在执行时会造成主从数据不一致 -
基于行的格式binlog_format=ROW【5.7之后默认使用】记录了每一行的数据修改
优点:
①更加安全的主从复制,不用再次执行SQL减少不确定性。
②每行复制更快。
③误操作而
修改数据时可通过二级制日志分析逆向还原缺点:大规模修改产生的日志量大,磁盘和网络负载大
可调节参数
- binlog_row_image
- FULL 全量记录每条数据修改【默认】
- MINIMAL 只记录修改的列【建议】
- NOBLOB 类似全量记录,但是如果TEXT或者BLOB字段列未修改则不记录这些字段
- binlog_row_image
-
混合的格式binlog_format=MIXED
特点:根据情况使用STATEMENT和ROW格式,ROW在STATEMENT不能记录的情况下记录
二进制日志对复制的影响
- 基于SQL语句的复制(SBR)【二进制日志使用的是STATEMENT格式,5.1.4之前只有中】
优点
- 生成日志量少,节约磁盘/网络IO
- 并不强制要求主从数据库的表定义完全相同【列顺序不同,或者字段类型兼容】
- 比基于行的复制方式更为灵活
缺点
-
非确定性事件无法保证主从数据复制的一致【例如UUID()】数据不一致导致主从复制中断
-
对于存储过程,触发器,自定义函数进行修改也可能造成主从数据不一致
-
基于行的复制(RBR)【二进制日志使用的是ROW格式】
优点
- 可以应用任何SQL的复制包括非确定函数,存储过程等
- 可以减少从服务器上锁的使用
缺点
- 要求主从数据库的表结构完全相同,否则可能会中断主从复制【从末尾加列没问题】
- 无法在从服务器上单独执行触发器
-
混合模式【根据实际内容在以上两者之间转换】
MySQL的复制工作方式
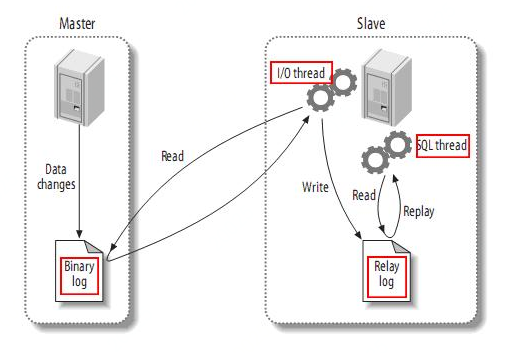
复制工作原理 (1) master将改变记录到二进制日志(binary log)
(2) slave将master的binary log拷贝到它的中继日志(relay log)
从读取中继日志的位置不同又分为:基于日志的复制、基于GTID的复制
(3) slave重做中继日志中的事件,将改变反映它自己的数据
基于段的日志是在从库上重新执行记录的SQL
基于行的日志是在从库上直接应用对数据库的修改
当主从复制配置完成后,各复制线程启动顺序
① 从库上启动复制,在从库上创建I/O线程,I/O线程连接到主库
② 主库创建binlog dump线程读取数据库事件并发送给IO线程
③ 从库上的I/O线程接收到事件数据,将事件数据更新到中继日志(relay log)中
④ 从库上SQL线程读取中继日志中更新的事件数据并应用到从库上。
MySQL主从搭建
基于日志点复制
- 主机创建授权账号
# 在主服务器上执行,创建复制账号,并授予权限
CREATE USER '[username]'@'[ip]' identified by '[password]'
GRANT REPLICATION SLAVE ON *.* TO '[username]'@'[ip]'
- 主机服务器配置
# 每台MySQL要求不同
server-id=1
# 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起
log-bin=mysql-bin
- 从机配置
# 每台MySQL要求不同
server-id=101
# 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起
log-bin=mysql-bin
# 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误
relay-log=mysql-relay-bin
# 可选配置,是否将中继日志的内容重新记录到从机二进制日志中
# 当这台从机做另一个从机的主机形成链路复制时,此选项必须打开
log-slave-updates=on
# 可选配置,除了supper用户以外没有用户有写权限,建议从服务启用
read-only=on
- 初始化从数据库数据
#################################mysqldump备份########################################
# 备份MyISAM的存储引擎需要加入【--lock-all-tables】
# mysqldump备份会进行锁表操作
# --triggers备份触发器、--routines备份存储过程
# --master-data:
# 1[默认]:将dump起始(change master to)binlog点和pos值写到结果中
# 2:是将change master to写到结果中并注释
mysqldump --single-transaction --master-data=2 --triggers --routines --all-databases -u[user] -p >all.sql;
# 将备份SQL导入未初始化的从服务器
mysql -uroot -p<all.sql
#################################xtrabackup备份#######################################
# 参见PXC集群部分
- 启动复制链路
# 修改master信息
# 在备份文件中有[mysql-bin-file]和[log_offset]
change master to master_host='[ip]', master_user='[user]', master_password='[password]', master_log_file='[mysql-bin-file]', master_log_pos=[log_offset];
# 查看从机slave状态是否有误
show slave status
# 启动从机复制
start slave
基于日志点复制的优点
- MySQL最早支持的复制技术,BUG较少
- 对SQL查询没有任何限制【row格式下所有SQL无限制】
- 故障处理容易
基于日志点复制的缺点
- 故障转移时重新获取新主的日志点信息比较难
基于GTID的复制
GTID是从MySQL5.6版本才引入,使用基于日志点的复制要指定从二进制日志哪个位置进行增量同步,如果指定错误将会造成数据遗漏或者数据重复。基于GTID的复制会记录从库执行的事务GTID值,自动执行从库未执行的GTID值的事务,保证了同一个事务只会在从库中执行一次。【GTID:全局事务ID,保证每一个提交的事务在复制集群中可以产生一个唯一的ID】
GTID=source_id:transaction_id【source_id:auto.cnf中,transaction_id从一自增】
- 主机创建授权账号
# 在主服务器上执行,创建复制账号,并授予权限
CREATE USER '[username]'@'[ip]' identified by '[password]'
GRANT REPLICATION SLAVE ON *.* TO '[username]'@'[ip]'
- 主机服务器配置
# 每台MySQL要求不同
server-id=1
# 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起
log-bin=mysql-bin
# 开启gtid模式,会记录gtid的标识符
gtid-mode=on
# 强制GTID一致性,保证事务的安全
# 不能使用:
# 1.create table 。。select
# 2.在事务中使用create temporary table 建立临时表,使用关联更新事务表和非事务表。
enforce-gtid-consistency=on
# MySQL5.7之前必须配置
log-slave-updates=on
- 从机配置
# 每台MySQL要求不同
server-id=101
# 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起
log-bin=mysql-bin
# 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误
relay-log=mysql-relay-bin
# 开启gtid模式,会记录gtid的标识符
gtid-mode=on
# 强制GTID一致性,保证事务的安全
# 不能使用:
# 1.create table 。。select
# 2.在事务中使用create temporary table 建立临时表,使用关联更新事务表和非事务表。
enforce-gtid-consistency=on
# 可选配置,是否将中继日志的内容重新记录到从机二进制日志中
# 当这台从机做另一个从机的主机形成链路复制时,此选项必须打开
# MySQL5.7之前必须配置
log-slave-updates=on
# 可选配置,除了supper用户以外没有用户有写权限,建议从服务启用
read-only=on
# 主服务的相关信息,默认存储在文件中,建议开启,开启存储在salve_master_info表[innodb]中
master-info-repository=TABLE
# 中继日志的相关信息,默认存储在文件中,建议开启,开启存储在salve_relay_info表[innodb]中
relay-log-info-repository=TABLE
- 初始化从数据库数据
#################################mysqldump备份########################################
# 备份MyISAM的存储引擎需要加入【--lock-all-tables】
# mysqldump备份会进行锁表操作
# --triggers备份触发器、--routines备份存储过程
# --master-data:
# 1[默认]:将dump起始(change master to)binlog点和pos值写到结果中
# 2:是将change master to写到结果中并注释
mysqldump --single-transaction --master-data=2 --triggers --routines --all-databases -u[user] -p >all.sql;
# 将备份SQL导入未初始化的从服务器
mysql -uroot -p<all.sql
#################################xtrabackup备份#######################################
# 参见PXC集群部分
- 启动复制链路
# 修改master信息
# master_auto_position=1表示开启基于GTID的复制协议
change master to master_host='[ip]', master_user='[user]', master_password='[password]', master_auto_position=1;
# 查看从机slave状态是否有误
show slave status\G;
# 启动从机复制
start slave;
基于GTID复制的优点
- 故障转移方便,根据GTID值即可判断
- 从库不会丢失主库上的任何更改
基于日志点复制的缺点
-
故障处理复杂
-
对SQL查询有限制
选择复制模式是需要考虑所使用的MySQL的版本以及复制架构及主从切换方式和高可用管理组件是否支持
MySQL的复制拓扑
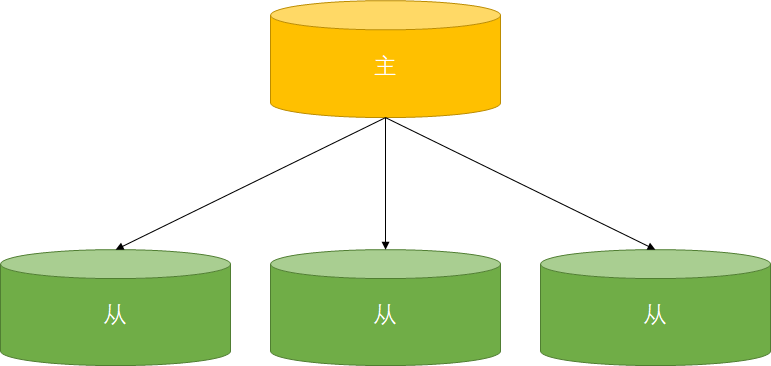
MySQL5.7之前一个从库只能有一个主库
一主多从&一主一从
这种架构下配置简单,可以用多个从库分担主库读负载
双主复制
如果只有一个主对外提供服务成为主备复制模式:在同一时间只有一台服务器提供服务,另一台为read_only。当提供服务的MySQL需要下线,可将从机切换为提供服务的机器。
| 如果两个主都对外提供服务成为主主复制模式:不是很好的结构,容易产生冲突。用于两个地区需要保存同样数据。建议两个主不要操作相同的数据库,而且需要设置auto_increment = 2和auto_increment_offset = 1 | 2 |
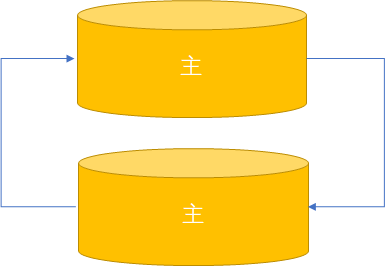
拥有备库的主主复制
增加从库分担主库的读负载,当一台主库下线时需要将其以它为master的从库下线
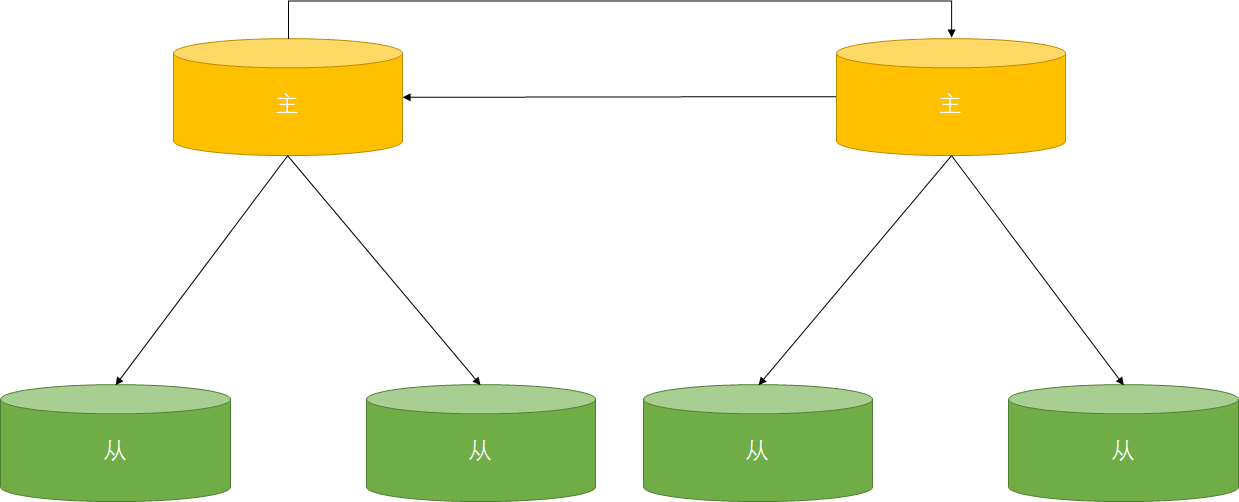
级联复制
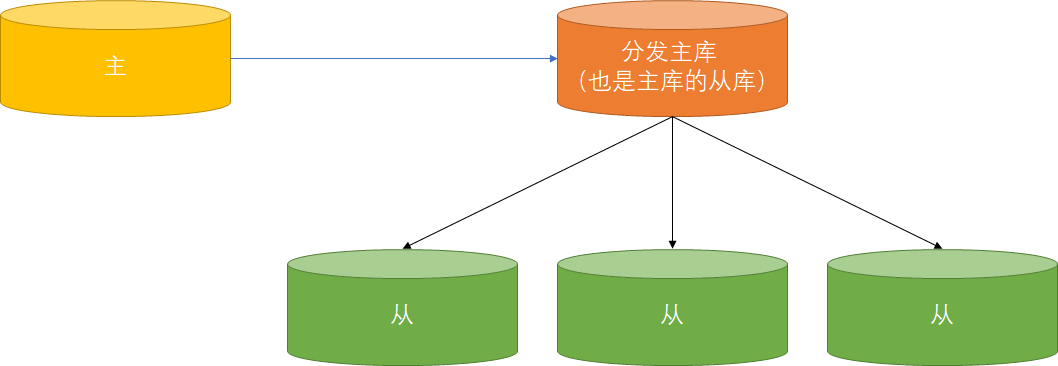
复制性能优化
-
主库执行事务的时间【从库也需要较长时间执行,导致延迟】
建议拆分大事务
-
二进制日志传输时间【异地机房网络延迟】
建议使用混合日志格式(MIXED)或设置binlog_row_image=minimal
-
默认情况下从库只有一个SQL线程,变成了串行执行
建议开启多线程复制(MySQL5.6中性能并不会,5.7中引入了逻辑时钟来控制线程效果较好)
# 以下配置最好写入my.conf stop slave; set global slave_parallel_type='logical_clock'; set global slave_parallel_workers=4; start slave; ####################################写入配置文件##################################### slave-parallel-type=LOGICAL_CLOCK slave-parallel-workers=4
半同步复制
MySQL 5.5版本之前,一直采用的是这种异步复制的方式。主库的事务执行不会管备库的同步进度,如果备库落后,主库不幸宕机,那么就会导致数据丢失。于是在MySQL在5.5中就引入了半同步复制( AFTER_COMMIT ),主库在应答客户端提交的事务前需要保证至少一个从库接收并写到relay log中。 MySQL5.7对半同步复制进行改进支持无损复制( AFTER_SYNC )。
半同步复制
半同步复制介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。 由于master是在三段提交的最后commit阶段完成后才等待,所以master的其他session是可以看到这个提交事务的,所以这时候master上的数据和slave不一致,master宕机后,slave数据丢失。

无损复制(增强版的半同步复制)
在半同步复制中,master写数据到binlog且sync,然后一直等待ACK。当至少一个slave request bilog后写入到relay‐log并flush disk,从机返回ack,主库提交事务。会阻塞master session, 由于是在三段提交的第二阶段sync binlog 完成后才等待, 所以master的其他session是看不见这个提交事务的,所以这时候master上的数据和slave 一致,master宕机后,slave没有丢失数据。

开启半同步复制
主库从库都需要进行一下配置
①MySQL会话中执行install plugin rpl_semi_sync_master soname 'semisync_master.so'; 安装半同步复制组件
② 看一下半同步相关状态信息show global variables like '%semi%'
# 开启半同步
rpl_semi_sync_master_enabled = 1
# 控制等待来自从服务器的确认提交并恢复到异步复制的时间(毫秒),超时之后,就从半同步复制,返回到异步复制
rpl_semi_sync_master_timeout = 1000
③ MySQL5.5~5.6只支持AFTER_COMMIT,MySQL5.7默认开启的半同步策略是AFTER_SYNC
延迟复制
建立主从之后或者关闭salve之后,再设置chang master to master_delay = [秒]语句,之后启动slave节点即可,延迟同步主要用于数据库数据恢复。
恢复步骤
第一步:从节点数据准备
# 主节点执行
show master logs;
# 查找执行误删除的SQL,logFileName为上条SQL查询到的日志,在结果中查找事务GTID
show binlog events in "logFileName";
# 从节点执行
stop slave;
set gtid_next='查找到的事务GTID';
# 这个GTID事务什么都不执行
begin;commit;
# 其余自动执行
set gtid_next='automatic';
# 不在延迟。立即同步主节点所有数据
change master to master_delay=0;
# 启动slave
start slave;
第二步:停掉数据库业务操作,不允许再读写数据
第三步:导出从数据库节点数据,在主节点上创建临时数据库,导入数据到临时库
第四步:将主节点上的业务数据表重命名,然后把临时业务库的数据表迁移到业务库
九、高可用架构
MMM(Multi-Master Replication Manager)
监控和管理MySQL的基于日志点的主主复制拓扑,并在当前的主服务器失效时,进行主备服务器之间的主从切换和故障转移,当主库出现宕机时进行故障转义并自动配置其它从库对新主的复制。可参考官网
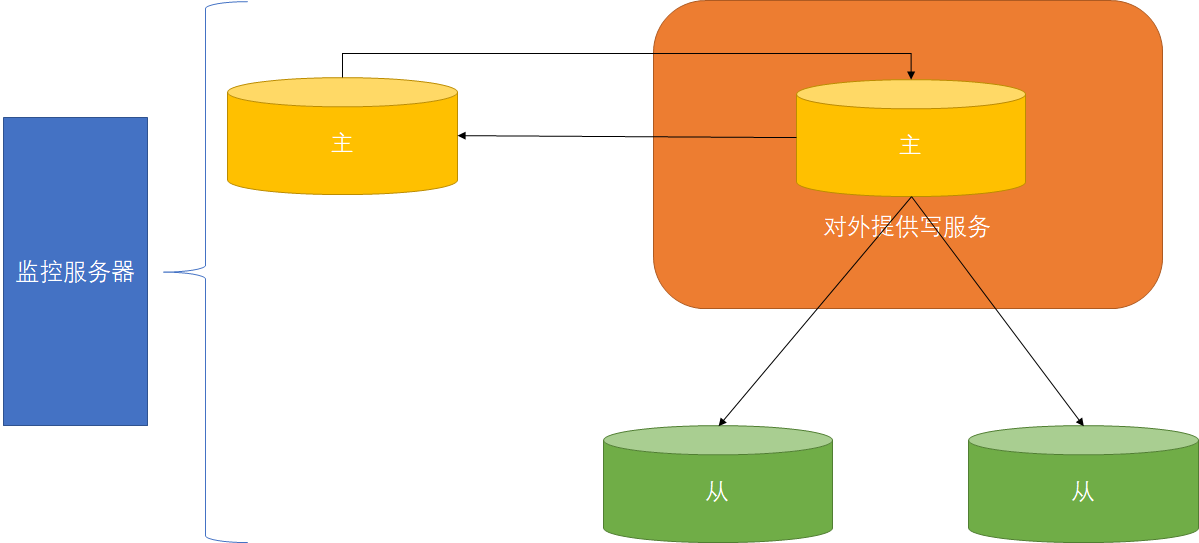
部署MMM所需资源
| 资源名称 | 数量 | 说明 |
|---|---|---|
| 主DB服务器 | 2 | 用于主主复制配置 |
| 从DB服务器 | 0-n | 配置从服务器用于分担读操作 |
| 监控服务器 | 1 | 用于监控MySQL的复制 |
| 监控用户 | 1 | 用于监控MySQL的状态的MySQL用户(replication client) |
| 代理用户 | 1 | 用于MMM代理的MySQL用户(super,replication client,process) |
| 复制用户 | 1 | 用于配置MySQL复制的MySQL用户(replication slave) |
第一步:MMM工具安装
- 安装epel
# centos 7 安装perl
yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
- 监控节点安装监控
yum install -y mysql-mmm-monitor.noarch
- 主服务器和从服务器均安装代理
yum install -y mysql-mmm-agent.noarch
第二步:MySQL主主搭建
- 配置
###############################两台主服务器配置###############################
# 每台MySQL要求不同
server-id=1
# 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起
log-bin=mysql-bin
# 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误
relay-log=mysql-relay-bin
# 当这台从机做另一个从机的主机形成链路复制时,此选项必须打开
log-slave-updates=on
###############################从机服务器配置###############################
# 每台MySQL要求不同
server-id=101
# 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起
log-bin=mysql-bin
# 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误
relay-log=mysql-relay-bin
# 可选配置,是否将中继日志的内容重新记录到从机二进制日志中
# 当这台从机做另一个从机的主机形成链路复制时,此选项必须打开
log-slave-updates=on
# 可选配置,除了supper用户以外没有用户有写权限,建议从服务启用
read-only=on
-
备份具有数据的主机服务器,并导入到其它机器
-
建立主从关系
第三步:配置MMM
- 建立账号
##########################只需在一个主节点执行,因为集群已经搭建完成##########################
# 监控用户用于用于监控节点
grant replication client on *.* to 'mmm_monitor'@'192.168.1.%' identified by '123456';
# 代理用户用于故障转义和主从切换
grant super, replication client, process on *.* to 'mmm_agent'@'192.168.1.%' identified by '123456';
# 复制用户,在搭建集群时以及建立不需再执行
# CREATE USER '[username]'@'[ip]' identified by '[password]' GRANT REPLICATION SLAVE ON *.* TO '[username]'@'[ip]'
- 配置mmm_common【每台机器都一样】
active_master_role writer
<host default>
cluster_interface eth0 #使用ifconfig或者ip addr查看网卡替换掉
pid_path /run/mysql-mmm-agent.pid
bin_path /usr/libexec/mysql-mmm/
replication_user replicant #复制用户的账号
replication_password slave #复制用户的密码
agent_user mmm_agent #代理用户的账号
agent_password RepAgent #代理用户的密码
</host>
<host db1> #第一个主节点的信息
ip 192.168.100.49
mode master
peer db2 #标识和它为主主架构的另一台主机
</host>
<host db2>
ip 192.168.100.50 #第二个主节点的信息
mode master
peer db1 #标识和它为主主架构的另一台主机
</host>
#<host db3> #从节点的信息,有从节点需要配置
# ip 192.168.100.51
# mode slave
#</host>
<role writer> #能进行写操作的节点(主节点),虚ip一个就够
hosts db1, db2
ips 192.168.100.250
mode exclusive
</role>
<role reader> #能进行读操作的节点,虚ip等于或者少于读节点个数
hosts db1, db2
ips 192.168.100.251, 192.168.100.252
mode balanced
</role>
- 配置mmm_agent【每台机器不一样】
include mmm_common.conf
# The 'this' variable refers to this server. Proper operation requires
# that 'this' server (db1 by default), as well as all other servers, have the
# proper IP addresses set in mmm_common.conf.
this db1 #改成mmm_common所对应的db
- 配置监控节点的mmm_common.conf
include mmm_common.conf
<monitor>
ip 127.0.0.1 #监控服务器的ip地址
pid_path /run/mysql-mmm-monitor.pid
bin_path /usr/libexec/mysql-mmm
status_path /var/lib/mysql-mmm/mmm_mond.status
ping_ips 192.168.100.50 #所有服务器的ip都配上,最好网关也配上,预防脑裂的发生
auto_set_online 60
# The kill_host_bin does not exist by default, though the monitor will
# throw a warning about it missing. See the section 5.10 "Kill Host
# Functionality" in the PDF documentation.
# 如果MySQL服务器出现问题需要关机可以执行脚本
# kill_host_bin /usr/libexec/mysql-mmm/monitor/kill_host
#
</monitor>
<host default> #监控账户的账号密码
monitor_user mmm_monitor
monitor_password RepMonitor
</host>
debug 0
第四步:启动MMM
每个MySQL节点执行 mmm_agentd start
监控节点执行mmm_mond start
第五步:查看状态
监控节点执行mmm_control show
MMM架构的优点
- 使用Perl脚本语言开发并且完全开源
- 提供了读写虚拟IP,使服务器角色的变更对前端应用更加透明
- 提供了延迟监控,在从服务器出现延迟或终端情况下可以把虚拟IP漂移到其它正常的服务器上
- 主数据库故障转移后服务器对新主的重新同步功能
- 发生故障的主服务器很容易重新上线
MMM架构的缺点
- 发布时间早不支持MySQL的GTID复制
- MySQL5.6之后的多线程复制不支持
- 提供了延迟监控,但多线程复制不支持,在写并发大的情况下可能发生所有读VIP都偏移到主服务器上
- 在进行主从切换,容易造成数据丢失(直接将主主服务器中的备机提升,但备机存在延迟不一定时最新的数据,从数据库也切换此机器为主机,容易事务多次执行)
- MMM监控服务存在单点故障
- 没有提供多个从服务器的读负载均衡功能
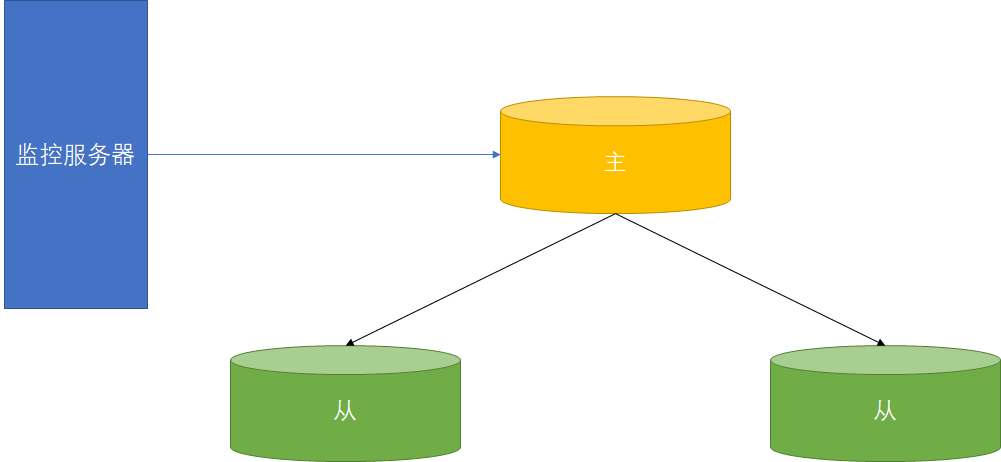
MHA(Master High Availability)
现项目地址在GitHub上是由Perl脚本开发,更关注MySQL主从架构下的主DB【只监控主DB】,当主DB不可用时,从多个从服务器中选举出数据最新的从数据库作为主服务器,并提供了主从切换的故障转移。并且MHA支持GTID复制模式
第一步:MySQL主主搭建
#####################################主服务器配置#####################################
# 每台MySQL要求不同
server-id=1
# 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起
log-bin=mysql-bin
# 开启gtid模式,会记录gtid的标识符
gtid-mode=on
# 强制GTID一致性,保证事务的安全
# 不能使用:
# 1.create table 。。select
# 2.在事务中使用create temporary table 建立临时表,使用关联更新事务表和非事务表。
enforce-gtid-consistency=on
log-slave-updates=on
relay-log=mysql-relay-bin
#####################################从服务器配置#####################################
# 每台从MySQL要求不同
server-id=101
# 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起
log-bin=mysql-bin
# 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误
relay-log=mysql-relay-bin
# 开启gtid模式,会记录gtid的标识符
gtid-mode=on
# 强制GTID一致性,保证事务的安全
# 不能使用:
# 1.create table 。。select
# 2.在事务中使用create temporary table 建立临时表,使用关联更新事务表和非事务表。
enforce-gtid-consistency=on
# 从服务器多线程执行SQL
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=4
log-slave-updates=on
read-only=on
# 主服务的相关信息,默认存储在文件中,建议开启,开启存储在salve_master_info表[innodb]中
master-info-repository=TABLE
# 中继日志的相关信息,默认存储在文件中,建议开启,开启存储在salve_relay_info表[innodb]中
relay-log-info-repository=TABLE
- 备份具有数据的主机服务器,并导入到其它机器
- 建立主从关系
第二步:安装epel
# centos 7 安装perl
yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
第三步:配置集群内所有主机相互SSH免认证登陆【用于保存原主服务器的二进制日志,虚拟IP】
# 一直回车就行
ssh-keygen
# 拷贝ssh证书
ssh-copy-id -i /root/.ssh/id_rsa 用户名@IP地址
# 测试是否成功
ssh 用户名@IP地址
第四步:安装MHA【centos安装el6包】
#################################所有MySQL服务节点#################################
# 安装依赖
yum install perl-DBD-MySQL
# 安装node节点
rpm -ivh mha4mysql-node-X.Y-N.noarch.rpm
#####################################监控节点#####################################
yum install perl-DBD-MySQL
yum install perl-Config-Tiny
yum install perl-Log-Dispatch
yum install perl-Parallel-ForkManager
# 监控节点也需要安装node
rpm -ivh mha4mysql-node-X.Y-N.noarch.rpm
# 安装监控
rpm -ivh mha4mysql-manager-X.Y-N.noarch.rpm
第五步:配置MHA
- 创建MHA的监控节点配置文件【/etc/masterha_default.cnf】,配置官网有示例。监控节点不能和MySQL节点放一起
[server default]
# 具有所有权限的用户,最好是建立一个MHA专用用户对专属网段开放
user=用户名
password=密码
# manager【监控】节点的工作目录
manager_workdir=/home/mysql_mha
# manager【监控】节点的日志路径
manager_log=/home/mysql_mha/manager.log
# 远程node节点的工作目录,需要在所有node节点手动创建
remote_workdir=/home/mysql_mha
# 配置的SSH用户,manager需要用此用户启动
ssh_user=用户名
# 主服务器具有复制权限用户
repl_user=用户名
repl_password=密码
# master主机ping的检查时间
ping_interval=1
# master主机的二进制目录【所有从节点的也应该一样】
master_binlog_dir=/var/lib/mysql
# master节点宕机进行虚拟IP漂移的脚本【MHA本身不具有虚拟ip漂移功能,脚本可以GithHub找到示例】
master_ip_failover_script=/script/masterha/master_ip_failover
# master宕机的处理脚本,脚本可以GithHub找到示例
# shutdown_script= /script/masterha/power_manager
# 主从切换的通知管理员脚本,脚本可以GithHub找到示例
# report_script= /script/masterha/send_master_failover_mail
# 用于检查master是否可以ping通,避免manager节点自己ping不同,但从节点可以而造成master不可用假象
secondary_check_script=masterha_secondary_check -s remote_host1 -s remote_host2
# 服务器配置,主从关系MHA会自动识别,不需要指明
# candidate_master=1 代表可以作为master的候选机器
# no_master=1 代表不作为master的候选机器
[server1]
hostname=host1
candidate_master=1
[server2]
hostname=host2
candidate_master=1
[server3]
hostname=host3
no_master=1
- master_ip_failover脚本
#!/usr/bin/env perl
# Copyright (C) 2011 DeNA Co.,Ltd.
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
my (
$command, $ssh_user, $orig_master_host,
$orig_master_ip, $orig_master_port, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password
);
# 配置虚拟VIP
my $vip = '192.168.152.159/24';
# VIP的网卡Key
my $key = '1';
# 注意修改网卡为本机使用的网卡
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
# 注意修改网卡为本机使用的网卡
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
- 检查配置是否正确
# 检查SSH配置,如果node和manager是同一台服务器则需要将自己的server注释掉否则报错
masterha_check_ssh --conf=/etc/masterha_default.cnf
# 检测主从复制结构
masterha_check_repl --conf=/etc/masterha_default.cnf
- 启动
# 启动manager
nohup masterha_manager --conf=/etc/masterha_default.cnf &
- 配置虚拟IP
# MHA并不会主动配置虚拟IP,虚拟IP漂移脚本只在master节点挂掉时启用
ifconfig 网卡名:key 虚拟IP/子网掩码数
MMM架构的优点
- 使用Perl脚本语言开发并且完全开源,提供了各种脚本可以进行嵌入
- 支持GTID的复制
- MHA在进行故障转移时更不易产生数据丢失,可配合MySQL半同步最大程度减少数据丢失
- 同一个监控节点可以监控多个集群
MMM架构的缺点
- MHA必须编写脚本或利用第三方工具实现VIP配置
- MHA只对master服务器监控
- 基于SSH免认证登陆,存在一定隐患
- 没有提供多个从服务器的读负载均衡功能
使用中间件读写分离和负载均衡
写操作只能在master上进行,而slave可以分担读负载所以要进行读写分离、负载均衡。使用中间件完成读写分离负载均衡比程序员实现简单,但是性能损耗较为严重。
-
MySQL Proxy
MySQL官方提供但是一直没有正式版,现在已经改为MySQL Router,一直存在性能、稳定性缺陷。
-
MySQL Router
官方维护,MySQL Proxy的替代方案
-
MaxScale
MariaDB开发的插件式,定制灵活,自动检测
MaxScale的介绍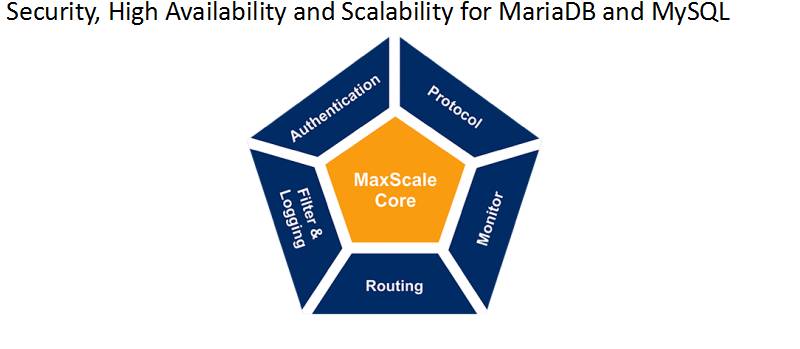
- Authentication为认证插件提供了数据库用户登陆认证功能,MaxScale会读取
mysql.user表信息并缓存 - Protocol为协议模块提供了客户端到MaxScale和MaxScale到后端的协议
- Routing为路由模块控制请求发送给后端那个数据库
- Monitor为监控模块目的是监控后端,使请求发送给后台服务正常的数据库
- Filter&Logging为日志和过滤模块提供了数据库防火墙能改写一部分简单SQL和SQL容错以及日志记录
MaxScale的安装
yum localinstall maxscale-X.Y.Z.centos.R.x86_64.rpm
MaxScale的MySQL使用账号配置
-- 创建MaxScale用于监控主从状态的账号
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'maxscale_monitor'@'%' IDENTIFIED BY '[passowrd]' WITH GRANT OPTION;
-- 创建MaxScale用于路由模块的账号,需要读取MySQL的账号信息
GRANT ALL ON *.* TO 'maxscale'@'%' IDENTIFIED BY '[passowrd]' WITH GRANT OPTION;
配置MaxScale
[maxscale]
threads=auto
[server1]
type=server
address=IP地址
port=3306
protocol=MariaDBBackend
[server2]
type=server
address=IP地址
port=3306
protocol=MariaDBBackend
[server3]
type=server
address=IP地址
port=3306
protocol=MariaDBBackend
[MariaDB-Monitor]
type=monitor
module=mariadbmon
servers=server1
user=myuser
password=mypwd
monitor_interval=2000
# 如果只是负载读均衡则配置此模块,否则注释掉此模块
[Read-Only-Service]
type=service
router=readconnroute
servers=server1
user=myuser
password=mypwd
router_options=slave
# 读写分离模块
[Read-Write-Service]
type=service
router=readwritesplit
servers=server1
user=myuser
password=mypwd
# 如果只是负载读均衡则配置此模块,否则注释掉此模块
[Read-Only-Listener]
type=listener
service=Read-Only-Service
protocol=MariaDBClient
port=4008
# 读写分离使用的登陆端口
[Read-Write-Listener]
type=listener
service=Read-Write-Service
protocol=MariaDBClient
port=4006
#监控模块默认示例文件中没有
[MaxAdmin-Service]
type=service
router=cli
# 监控模块使用的端口,默认示例文件中没有
[MaxAdmin-Listener]
type=listener
service=MaxAdmin-Service
protocol=maxscaled
port=6603
检查&启动
# 创建maxscale用户用于启动
useradd maxscale
# 查看maxscale配置文件是否语法正确,会打印各个文件位置默认(日志、PID等)
maxscale --config-check=/etc/maxscale.cnf -U maxscale
# 启动maxscale,查看日志文件是否启动成功,日志文件在
maxscale --config=/etc/maxscale.cnf -U maxscale
# 进入命令台管理
maxadmin --user=admin --password=mariadb
# 以下命令在进入管理台之后使用
# list servers -- 查看服务器状态,已经主从关系
十、索引优化
MySQL的索引是由存储引擎实现的,即不同的存储引擎实现的同一种索引的方式也是存在差异的。MySQL存储引擎一般支持BTree索引和Hash索引。
MyISAM和InnoDB存储引擎:只支持BTree索引, 也就是说默认使用BTREE,不能够主动更换(InnoDB引擎可根据情况自动转换)
MEMORY存储引擎:支持BTree索引和Hash索引
MyISAM中索引叶子节点记录的是存储在数据磁盘上的位置数据
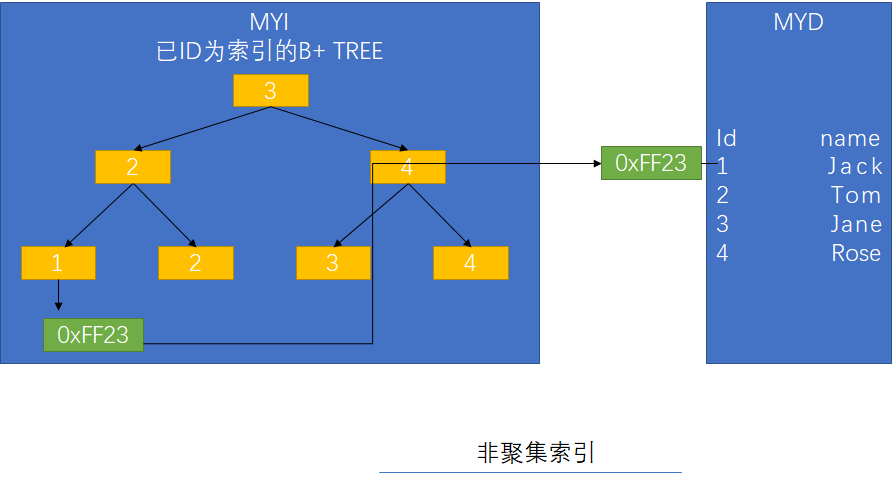
InnoDB中索引(主键)叶子节点记录的是存储在数据,其它索引记录的是直向的主键索引
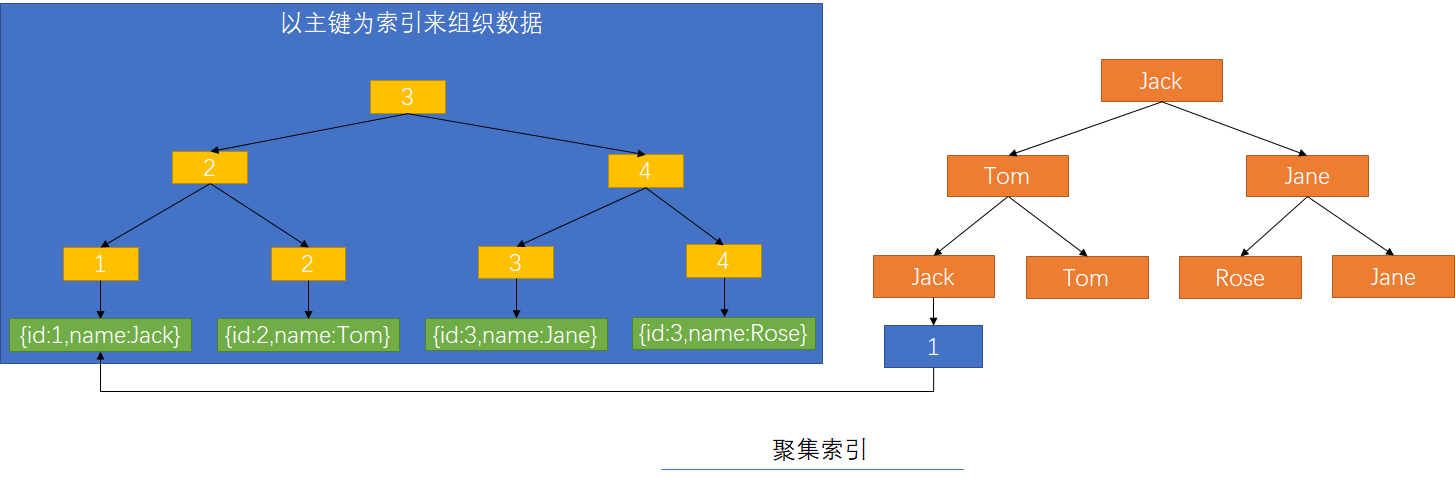
BTree索引
最左前缀原则
查询条件精确匹配索引的左边连续一个或几个列时,部分索引信息所以可以被用到,但是只能用到一部分,即条件所组成的最左前缀。造成的原因是BTree的结构导致。
匹配列前缀原则
使用like 'value%'方法使用列前缀匹配
精确匹配左前列并范围匹配令一列
使用a = 1 and b= 2 and c>10 and d = 5,建立了索引(a,b,c,d),只会用到a、b、c三列
前缀索引建立
在字符串上建立前缀索引create index index_name ON table(col_name(n));
BTree的限制
-
如果不是按照索引最左边列开始查找,则无法使用索引
-
使用索引时不能跳过索引中的列
-
查询条件中含有函数或表达式
如
select ... from product where to_day(out_day) - to_day(current_data) <= 30用不上索引改为
select ... from product where out_day <= data_add(current_day, interval 30 day)
覆盖索引
覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖
①优化缓存、减少磁盘IO操作
②减少随机IO,变随机IO操作为顺序IO操作
③san避免Innodb索引列查找主键列的IO消耗
④避免MyISAM表进行系统调用
使用索引优化排序的限制
①索引的列顺序和Order By子句的顺序完全一致
②索引中所有列的方向(升序、降序)和Order By子句完全一致
③Order By中的字段全部在关联表中的第一张表中
Hash索引
Hash索引的限制
- Hash索引必须进行二次查找
- Hash索引无法用于排序
-
Hash索引不支持部分索引查找也不支持范围查找
- Hash索引中Hash码计算可能存在Hash冲突
使用索引的优点
- 大大减少了存储引擎需要扫描的数据量
- 帮助进行排序以避免使用临时表
- 进行事务操作时,避免全表扫描锁定全表(间隙锁)
查找冲突不必要的索引
-
安装
percona-toolkit -
使用
pt-duplicate-key-checker --host='[host ]'--user='[user]' --password='[password]' --databases='[dataBase]'查看重复定义的索引
查看从未使用的索引
SELECT
OBJECT_SCHEMA,
OBJECT_NAME,
INDEX_NAME
FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE INDEX_NAME IS NOT NULL
AND COUNT_STAR = 0
AND OBJECT_SCHEMA <> 'mysql'
ORDER BY OBJECT_SCHEMA,OBJECT_NAME;
更新索引统计信息&减少索引碎片化
#MyISAM会将统计信息记录在磁盘中,会全表扫描
#InnoDB不在磁盘存储,更具随机访问存储在内存中,统计结果并非十分准确
analyze table tableName; #更新索引统计信息
#不论什么存储引擎均会锁表
optimize table tableName; #优化索引,维护索引
十一、SQL优化
获取存在性能问题的SQL
慢查询日志
MySQL的慢查询日志是一种开销比较低的获取存在性能问题的SQL的一种方法,开销主要在磁盘IO和存储日志文件所需要的磁盘空间。建议日志文件(包括二进制日志文件等)和数据文件目录分开,最好分盘存放。慢查询日志记录了所有符合条件的语句包含查询语句、数据修改语句、已回滚的SQL
# 在运行的系统中可以使用 set global slow-query-log=on
slow-query-log=on
# 指定慢查询日志的文件名/存储路径
slow-query-log-file=mysql-slow.log
# 设置慢查询日志记录的阙值,单位秒,0.02代表20毫秒。默认10
long-query-time=0.02
# 记录未使用索引的SQL,不管这个查询是否超过阙值
log-queries-not-using-indexes=on
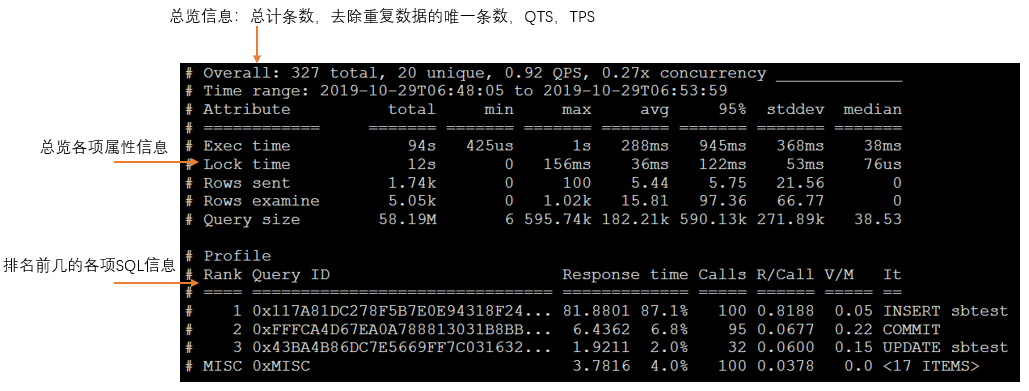
慢查询日志原始文件示例,慢查询文件内容一般较多,直接查看无法查看出具体信息,无法归类。
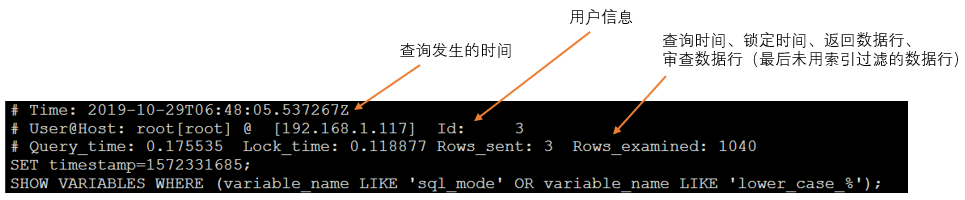
使用MySQL自带的慢查询日志查看工具mysqldumpslow查看慢查询日志
常用mysqldumpslow -s r -t 10 mysql-slow.log查看查询结果
- -s order代表排序方式
r代表时间 - -t topNum代表取出前topNum条数据

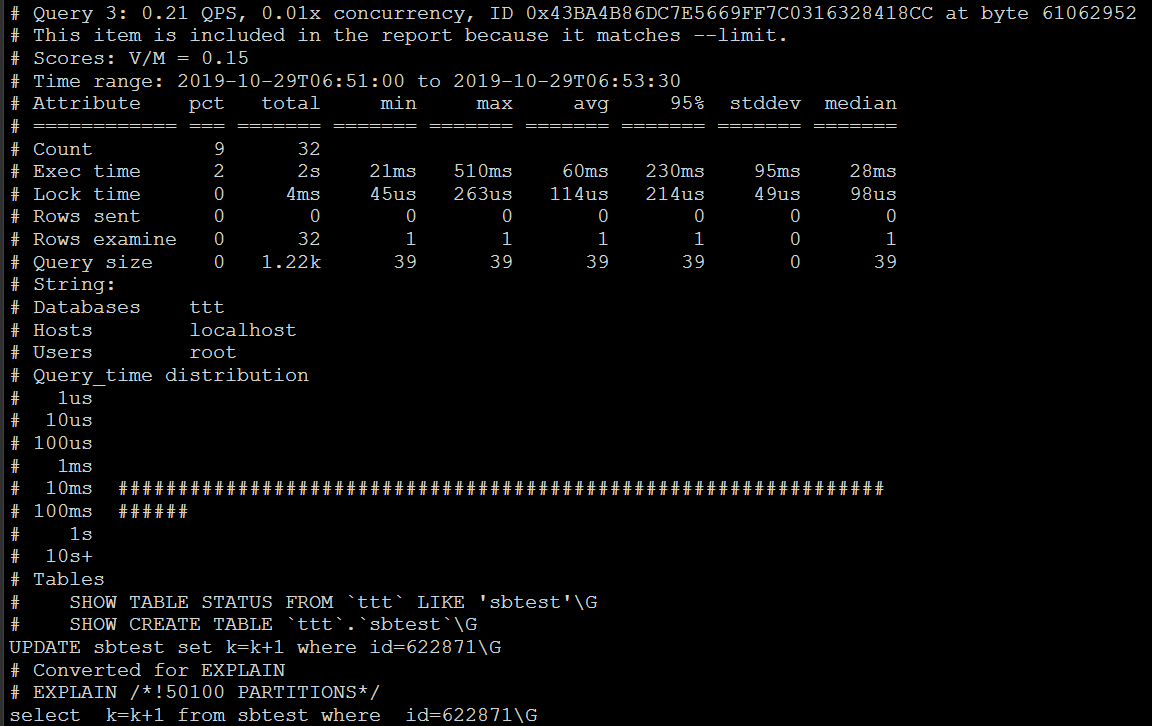
使用更加强大的pt-query-digest分析慢查询日志
常用pt-query-digest --explain h=[host], u=[user], p=[password] mysql-slow.log查看查询结果
实时获取性能问题
利有infomation_schema数据库中的processlist表查询当前执行的SQL状态信息
select id, `user`, `host`, DB, command, `time`, state, info from information_schema.processlist where time >= [time]
预处理及生成执行计划
查询缓存
根据MySQL处理SQL请求的大致流程解析可以知道查询缓存对SQL性能是有影响的,查询缓存是对查询语句做hash算法然后存储的,所以想命中缓存的第一个必要条件是语句必须一样。
- 查询命中不容易
- 如果缓存数据的设计的原始表发生改变这个缓存也需要刷新
- 检查是否命中时会对缓存加锁
对于一个读写频繁的系统很可能会降低查询处理的效率,所以建议关闭查询缓存
# 0时表示关闭,1时表示打开,2表示只要select 中明确指定SQL_CACHE才缓存
query-cache-type=0
# 用于查询缓存的内存大小,单位字节必须是1024的整数倍
query-cache-size=[size]
# 表示单个结果集所被允许缓存的最大值
query-cache-limit=[size]
# 每个被缓存的结果集要占用的最小内存
query_cache_min_res_unit=[size]
执行计划生成
执行计划生成阶段包含了解析SQL、预处理、优化执行计划
解析SQL:通过关键字对语法进行解析,并生成一颗对应的语法解析树
预处理:检查解析树是否合法,比如表和数据列是否存在,名字或者别名是否存在歧义
优化执行计划:利有查询优化器优化查询
查询优化器做的工作
- 重新定义表的关联顺序
-
将能转化为内连接的外连接转换为内连接如
select * from a left join b on a.id=b.id where b.id=2; - 优化count()【MyISAM保存的行数】、max()、min()
- 尝试将一个表达式转换为常数
- 使用等价变换原则(索引覆盖)
- 子查询优化(尝试将子查询转为关联查询)
- 提前终止查询(发现一个必定不满足的条件,比如无符号类型小于0)
- 对in()条件优化(对in中条件进行排序,再利用二分查找法查询)
查询优化器优化错误的原因
- 统计信息不准确(innodb是抽样统计)
- 执行计划中的成本估算并不等于实际执行的成本
- MySQL不会考虑其它并发查询(锁)
-
有时也会基于一定规则来进行优化(存在全文索引就首先采用全文索引)
- 不考虑不受其控制的成本(存储过程、用户自定义函数等)
确定查询处理各个阶段消耗的时间
使用profile
# 启动profile,这是一个session级的配置
set profiling= 1;
# 执行查询。。。。
# 执行查询。。。。
# 执行查询。。。。
# 查看每一个查询消耗的总时间信息
show profiles;
# 查看各个阶段所消耗的时间信息,N为上个命令返回的ID值
show profile for query N;
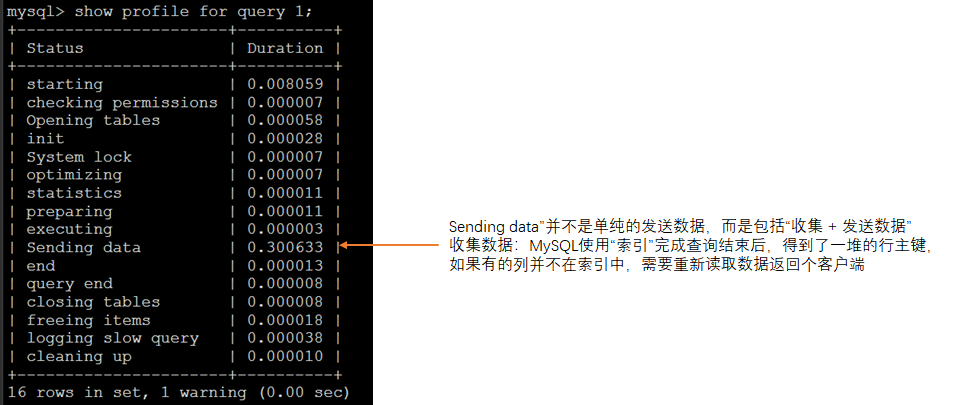
产生警告的原因是MySQL将在以后版本移除出profile,使用performance_schema
使用performance_schema
#设置开启
update performance_schema.setup_instruments set enabled = 'YES', timed='YES' where name like 'stage%';
update performance_schema.setup_consumers set enabled = 'YES' where name like 'events%';
#进行查询
SELECT
events_statements_history_long.THREAD_ID,
SQL_TEXT,
events_stages_history_long.EVENT_NAME,
( events_stages_history_long.TIMER_END - events_stages_history_long.TIMER_START ) / 1000000000 AS 'DURATION(ms)'
FROM
events_statements_history_long
JOIN threads ON events_statements_history_long.THREAD_ID = threads.THREAD_ID
JOIN events_stages_history_long ON events_stages_history_long.THREAD_ID = threads.THREAD_ID
AND events_stages_history_long.EVENT_ID BETWEEN events_statements_history_long.EVENT_ID
AND events_statements_history_long.END_EVENT_ID
WHERE
threads.PROCESSLIST_ID = CONNECTION_ID( )
AND events_statements_history_long.EVENT_NAME = 'statement/sql/select'
ORDER BY
events_statements_history_long.THREAD_ID,
events_stages_history_long.EVENT_ID
修改大表结构
pt-online-schema-change --alter='[MODIFY filed varchar(32) not null ...]' \
--user=[user] --password=[password] \
D='[DBName]',t='[tableName]' --charset=utf8 --execute
此工具的处理过程
- 创建触发器(避免丢失新增和修改数据)
- 创建新的临时表
- copy数据
- 旧表加排他锁
- 重命名表
- 接触锁
- 删除旧表
- 删除触发器
十二、分库分表
参见MyCat部分
MyCat用于读写分离、分库分表等功能
十三、部分概念
锁的概念
数据库锁定机制简单来说就是数据库为了保证数据的一致性而使各种共享资源在被并发访问访问变得有序所设计的一种规则。
按照锁定级别分类可分为
-
行级锁(row-level)【MySQL存储引擎实现】
行级锁是MySQL中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为
共享锁和排他锁。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
-
表级锁(table-level)【MySQL服务实现】
表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MyISAM与Memory以及InnoDB【默认行级锁】都支持表级锁。表级锁分为
表共享读锁与表独占写锁。开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
-
页级锁(page-level)【MySQL存储引擎实现】
页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。BDB支持页级锁。
开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
手动共享表读锁&独占表写锁
-- 加锁
lock table [表名称] read/write,[表名称] read/write, ... ;
-- 解锁
unlock tables;
InnoDB引擎的锁机制
共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁
排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁
意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁
说明:
1)共享锁和排他锁都是行锁,意向锁都是表锁,应用中我们只会使用到共享锁和排他锁,意向锁是mysql内部使用的,不需要用户干预
2)对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X)
3)对于普通SELECT语句,InnoDB不会加任何锁
4)SELECT可以通过以下语句显示给记录集加共享锁或排他锁
SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE -- 共享锁(S)
SELECT * FROM table_name WHERE ... FOR UPDATE -- 排他锁(X)
5)当两个事务进行,一个事务更新一条记录,另一事务可读取此记录(不变-从Undo日志中读取的值),写入操作需要等更新操作提交事务
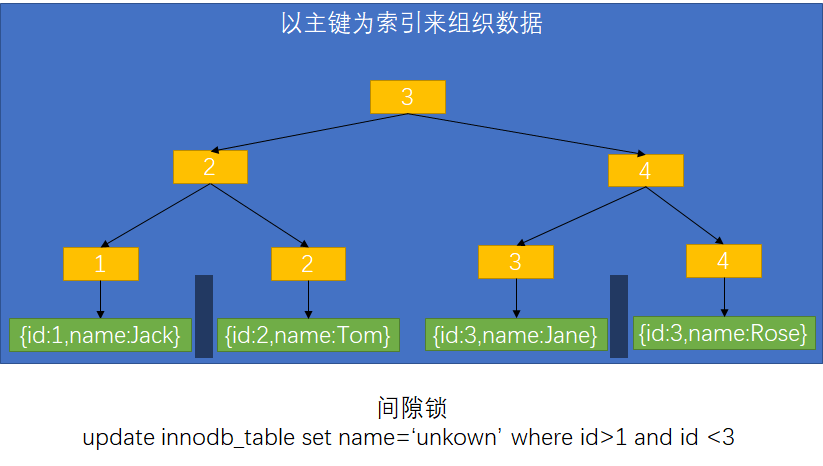
6)InnoDB中的行锁都是间隙锁是在索引区间加锁
B 树 & B+ 树
MySQL处理SQL请求的大致流程
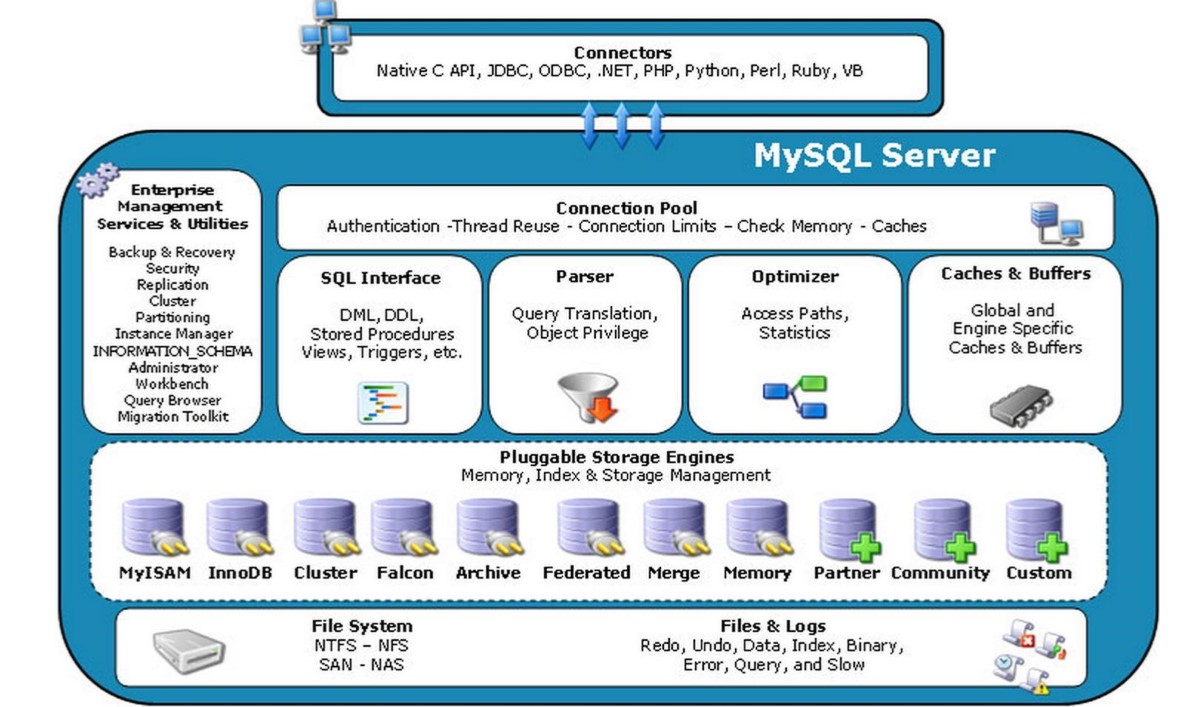
- 客户端发送SQL请求给服务器
- 服务器检查是否可以在查询缓存中命中改SQL【缓存中包含的有这条SQL的权限等信息,如果命中直接返回】
- 服务器端进行SQL解析、权限校验、预处理、再由优化器生成对应的执行计划
- 根据执行计划,调用存储引擎API来查找数据
- 返回结果数据到客户端
MySQL日志分类
- MySQL服务层:二进制日志、慢查日志、通用日志
- MySQL存储引擎层InnoDB日志:重做日志、回滚日志
SQL的执行顺序(MySQL为例)
- FROM(将最近的两张表,进行笛卡尔积) –VT1
-
ON(将VT1按照它的条件进行过滤) –VT2
-
LEFT JOIN(保留左表的记录) –VT3
-
WHERE(过滤VT3中的记录) –VT4…VTn
-
GROUP BY(对VT4的记录进行分组) –VT5
-
HAVING(对VT5中的记录进行过滤) –VT6
-
SELECT(对VT6中的记录,投影选取指定的列)–VT7
-
ORDER BY(对VT7的记录进行排序) –游标
- LIMIT(对排序之后的值进行分页)
WHERE条件执行顺序(影响性能)
-
MYSQL:从左往右去执行WHERE条件的。
-
Oracle:从右往左去执行WHERE条件的。
结论:写WHERE条件的时候,优先级高的部分要去编写过滤力度最大的条件语句
十四、数据库数据恢复
- 数据恢复可以使用数据库备份的备份文件恢复,但是备份点到当前的数据不可恢复
- 使用延迟复制的方法,从延迟数据库进行恢复,如果延迟数据库也已经执行那条SQL也不可恢复
- 使用日志闪回方式(日志必须row格式)
日志闪回
binlog2sql日志闪回工具可以解析出执行的SQL无法生成反向SQL 。然后再清空业务表,重新执行SQL即可完成数据恢复。
前置条件:
①停掉数据库读写操作
②热备份现数据库(将备份文件在其它机器上实验通过)
③清空需要恢复数据的业务表的全部记录,避免写入冲突
第一步:安装,下载地址
# 安装PIP工具
yum install -y python-pip;
cd binlog2sql-master;
pip install -r requirements.txt;
第二步:查找日志文件
show master logs;
第三步:解析出SQL
cd binlog2sql
python binlog2sql.py -u[user] -p[password] -d[database] -t [table] --start-file='[logfileName]' > [/path/tableName.sql]
第四步:删除解析出的SQL中不要的语句
第五步:直接执行SQL
十五、优化陷阱
MySQL数据库设计常犯的错以及对性能的影响
1)过分的反范式化为表建立太多的列
Mysql的服务器层和存储引擎层是分离的,Mysql的存储引擎API工作时需要把服务器层和存储引擎层之间通过缓冲格式来拷贝数据,然后在服务器层将缓冲层的数据解析成各个列,这个操作过程成本是非常高的,特别是对于MyISAM的变长结构,和Innodb这种行结构在解析时还必须进行转换,这个转换的成本呢就依赖于列的数量,所以,如果一个表的列过多,在使用这个表时就会带来额外过多的cpu消耗 。
2)过分的使用范式化设计造成了太多的表关联
在进行数据库设计时候要进行适当的反范式化设计,把经常使用的两个小表合成一个大表,这样做对提升数据库的性能和sql查询的性能都是 有帮助的。
3)在OLTP环境中使用不恰当的分区表
分区表可以帮助我们把一个大表在物理存储上按照分区键分成多个小表,但是在使用分区表时,分区键的选择非常关键,如果分区键的选择不恰当,就会造成查询时跨多个分区查询,这样不仅不会提升数据库的性能,而且还会降低数据库的查询性能。
4)使用外键约束保证事务的完整性
外键约束来保证数据的完整性,但是这样的效率是非常低的。