Canal的使用
一、Canal简介
Canal是用Java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。Canal(Canal Deployer)主要支持了MySQL的Binlog解析,解析完成后利用Canal Client、Canal Adapter来处理获得的相关数据。
Canal就是一个同步增量数据的一个工具。
利用Canal可以同步MySQL数据到Redis、ES、MQ等中间件。可自己使用Canal Client编写代码同步数据,也可以使用Canal Adapter配置数据同步到第三方中间件。
二、Canal的工作原理
Canal把自己伪装成 Slave,假装从Master复制数据。然后解析binlog日志读取变化数据
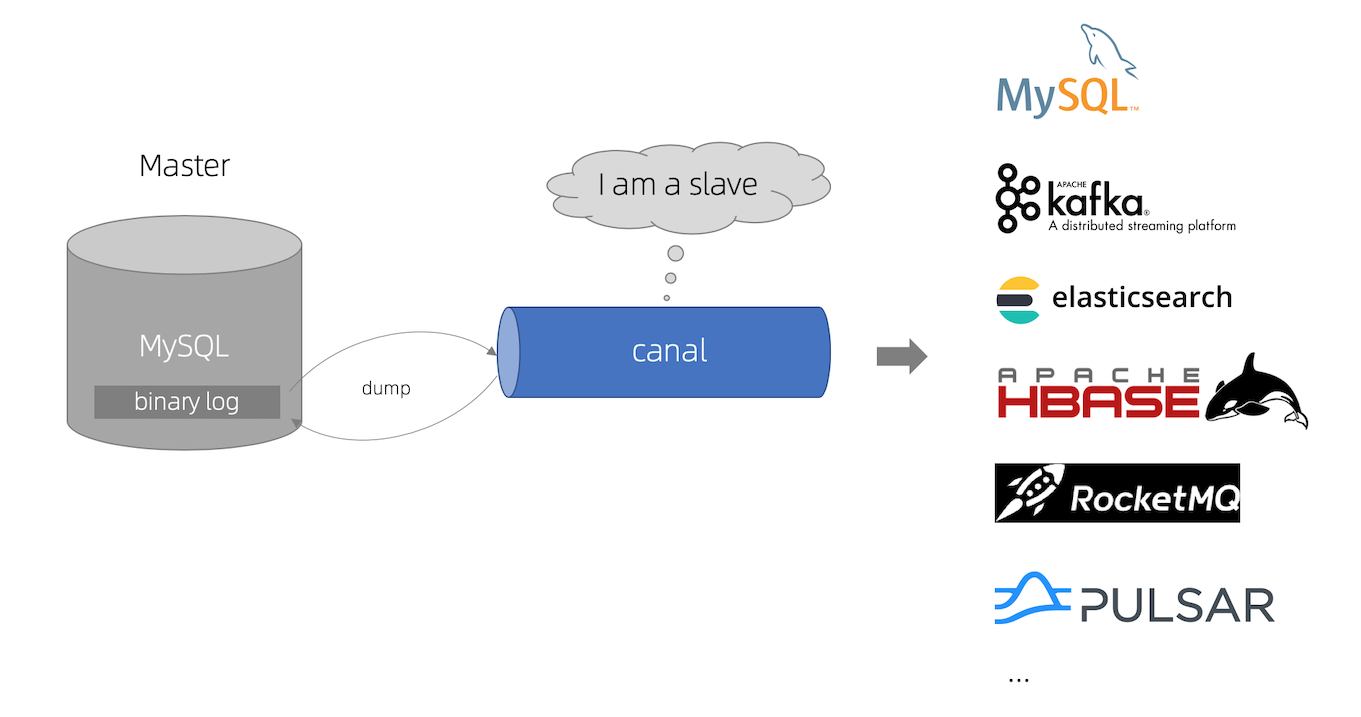
Canal工作的前提是MySQL要开启binlog日志,且为row模式
binlog可以说是MySQL最重要的日志了,它记录了所有的 DDL和DML(除了数据查询语句)语句。以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的
Binlog 的分类
- statement:语句级,binlog 会记录每次一执行写操作的语句。相对row模式节省空间,但是可能产生不一致性,比如”update tt set create_date=now()”,如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同
- row:行级,会记录每次操作后每行记录的变化,保持数据的绝对一致性。缺点:占用较大空间
- mixed:statement的升级版,一定程度上解决了因为一些情况而造成的 statement模式数据不一致问题,当执行结果可能发生变化的函数时会按照ROW的方式进行处理
三、Canal的搭建
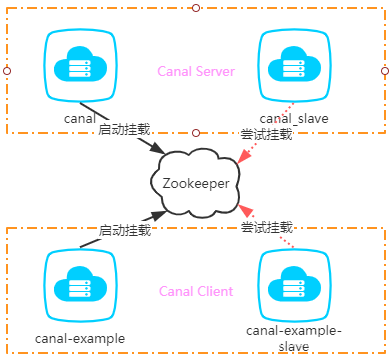
Canal集群的HA其实包含了服务端HA和客户端的HA。两者的实现原理差不多,都是通过Zookeeper实例标识某个特定路径下抢占EPHEMERAL(临时)节点的方式进行控制。抢占成功的一者会作为运行节点(状态为running),而抢占失败的一方会作为备用节点(状态是standby)
下载canal.adapter、canal.admin、canal.deployer
| ip | 角色 |
|---|---|
| 192.168.22.161 | canal-admin |
| 192.168.22.162 | canal.deployer |
| 192.168.22.163 | canal.deployer |
部署Canal Admin
第一步:解压
mkdir /opt/module/canal-admin
tar -zxvf canal.admin-$version.tar.gz -C /opt/module/canal-admin
第二步:修改conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306 # 修改为自己的mysql地址,用于存储canal admin的配置
database: canal_manager # 可不修改(需要建立并初始化数据库,官方脚本默认为canal_manager)
username: canal # 修改为自己的数据库用户名
password: canal # 修改为自己的数据库密码
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
# canal的adminPasswd并不是登陆admin的密码,登陆admin的密码是设置在对应的数据库中的,默认为123456
canal:
adminUser: admin # canal-admin用户名,可以修改server注册使用
adminPasswd: admin # canal-admin密码,可以修改server注册使用
第三步:执行初始化数据库脚本conf/canal_manager.sql
第四步:启动canal admin
sh /opt/module/canal-admin/bin/startup.sh
# 查看启动日志
cat /opt/module/canal-admin/logs/admin.log
第五步:访问canal admin,浏览器输入http://adminip:8089
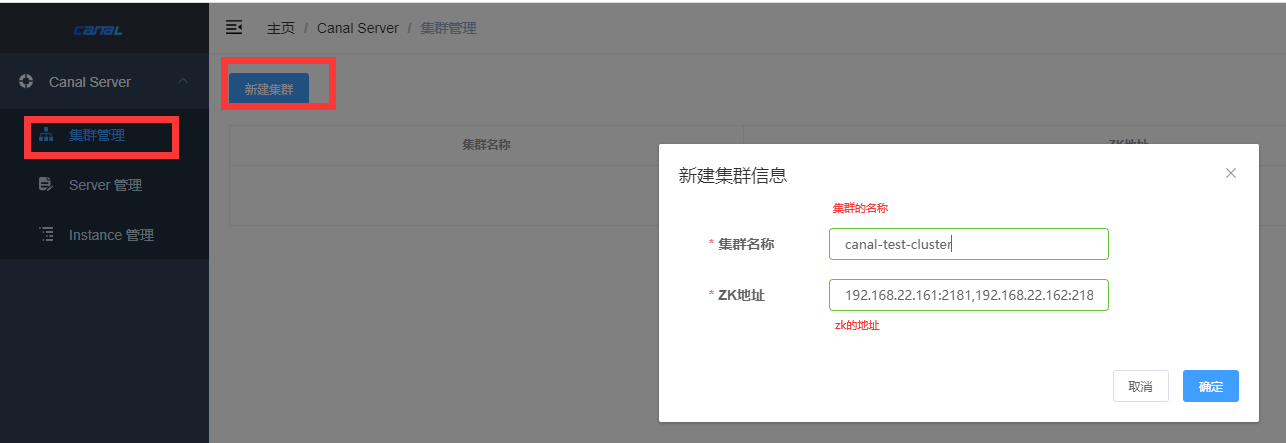
第六步:创建集群
第七步:修改主配置

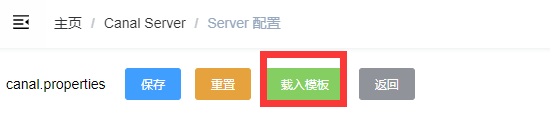
主要修改
# canal admin config
# 这里的密码就是前面在application.yml最后的参数提到的admin/admin
# 不过这里需要使用mysql加密后的密码,可以在mysql内通过命令 select password('yourpassword') 获取加密串(去掉星号)
canal.admin.manager = 192.168.22.161:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
canal.zkServers = 192.168.22.161:2181,192.168.22.162:2181,192.168.22.163:2181
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
#监控到的binlog输出到tcp
canal.serverMode = tcp
部署Canal-Deployer
第一步:需要先开启MySQL的Binlog写入功能,配置binlog-format为ROW模式
[mysqld]
# 开启 binlog
log-bin=mysql-bin
# 选择 ROW 模式
binlog-format=ROW
# 配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
# 根据自己的情况进行修改,指定具体要同步的数据库,如果不配置则表示所有数据库均开启 Binlog
# binlog-do-db=canal-test
第二步:创建MySQL账号,用于作为MySQL slave的角色
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
第三步:解压
mkdir /opt/module/canal-deployer
tar -zxvf canal.deployer-$version.tar.gz -C /opt/module/canal-deployer
第四步:配置每台Canal Server的conf/canal_local.properties
# register ip
canal.register.ip = 192.168.22.162
# canal admin config
canal.admin.manager = 192.168.22.161:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
# 刚在admin创建的集群名称
canal.admin.register.cluster = canal-test-cluster
# 自己显示的服务机器名称,如果不填回显的是ip
canal.admin.register.name = centos162
第五步:启动
/opt/module/canal-deployer/bin/startup.sh local
第六步:查看deployer是否启动成功

第七步:创建任务实例,选择刚创建的集群,创建属于它的实例任务
主要修改
# 需要读取的mysql数据的服务器地址
canal.instance.master.address=192.168.22.120:3306
# username/password
# 这里的用户必须是刚才授权该库的binlog权限的用户
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal_pwd
# table regex
# 配置监控test_csdn库下的所有表,这里的正则可以定制匹配规则,具体可参考官方文档:https://github.com/alibaba/canal/wiki/AdminGuide
canal.instance.filter.regex=canal-monitor\\..*
第八步:启动实例

四、Canal Client同步数据
@Test
public void testReadUpdateData() throws Exception {
//1.获取 canal 连接对象, destination:刚创建的实例名称
CanalConnector canalConnector = CanalConnectors.newClusterConnector(
"192.168.22.161:2181,192.168.22.162:2181,192.168.22.163:2181",
"test-canal-tcp", "", "");
//2、连接
canalConnector.connect();
//3、订阅数据库
canalConnector.subscribe("canal-monitor.*");
while (true) {
// 每次获取1000条增量数据
Message message = canalConnector.getWithoutAck(1000);
// 获取Entry集合
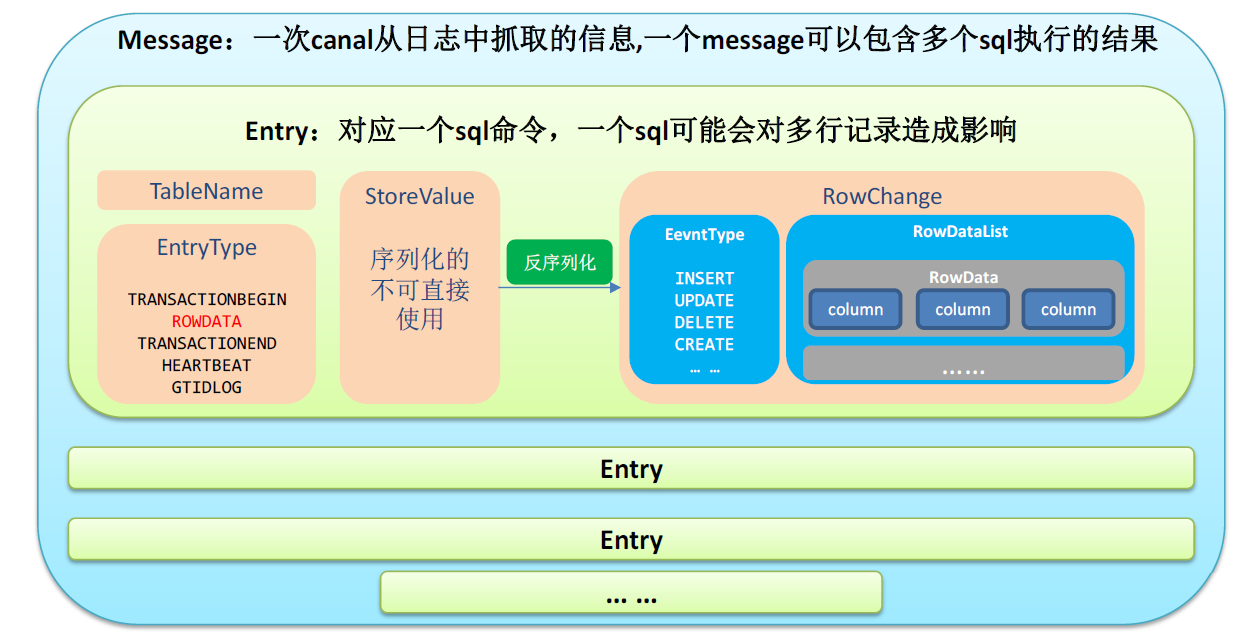
List<CanalEntry.Entry> entries = message.getEntries();
// 判断集合是否为空,如果为空,则等待一会继续拉取数据
if (entries.size() <= 0) {
System.out.println("当次抓取没有数据,休息一会。。。。。。");
Thread.sleep(1000);
} else {
// 遍历entries,单条解析
for (CanalEntry.Entry entry : entries) {
//1.获取表名
String tableName = entry.getHeader().getTableName();
//2.获取类型
CanalEntry.EntryType entryType = entry.getEntryType();
//3.获取序列化后的数据
ByteString storeValue = entry.getStoreValue();
//4.判断当前entryType类型是否为ROWDATA
if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
//5.反序列化数据
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
//6.获取当前事件的操作类型
CanalEntry.EventType eventType = rowChange.getEventType();
//7.获取数据集
List<CanalEntry.RowData> rowDataList = rowChange.getRowDatasList();
//8.遍历rowDataList,并打印数据集
for (CanalEntry.RowData rowData : rowDataList) {
JSONObject beforeData = new JSONObject();
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
for (CanalEntry.Column column : beforeColumnsList) {
beforeData.put(column.getName(), column.getValue());
}
JSONObject afterData = new JSONObject();
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
afterData.put(column.getName(), column.getValue());
}
//数据打印
System.out.println("Table:" + tableName +
",EventType:" + eventType +
",Before:" + beforeData +
",After:" + afterData);
}
} else {
System.out.println("当前操作类型为:" + entryType);
}
}
}
}
}
五、Canal Adapter同步数据
同步数据到ES参考https://github.com/alibaba/canal/tree/master/client-adapter,实际当中可能TCP模式的还要简单可控一点
同步数据到MQ较为简单,不需要用Canal Adapter。配置Canal Admin的模板即可
- server主配置
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rocketMQ
- instance实例配置
# 都发送到指定名称的topic
canal.mq.topic=canal_test_topic
# 针对库名或者表名发送动态topic,规则查看https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
# canal.mq.dynamicTopic=.*\\..*
# 过滤DML语句
canal.instance.filter.query.dml=true