lucene基本应用
一、术语&基础知识术语
结构化数据
- 结构化数据:指具有固定格式或有限长度的数据,如数据库等
- 非结构化数据:指不定长或无固定格式的数据,如HTML等
数据查询方法
- 顺序扫描法:从文件开始从扫描一直到文件结尾
- 全文检索:先建立索引,对索引进行匹配在进行取值(相当于从目录查找)
索引分类
-
正向索引:
“文档1”的ID > 【 {单词1:次数,位置列表},{单词2:次数,位置列表}…】
“文档2”的ID > 【 {单词1:次数,位置列表},{单词2:次数,位置列表}…】
-
倒排索引:
“关键词1”:【{“文档1”的ID,次数,位置列表},{“文档2”的ID,次数,位置列表} …】
“关键词2”:【{“文档1”的ID,次数,位置列表},{“文档2”的ID,次数,位置列表} …】
二、Lucene 实现全文检索的流程
概述
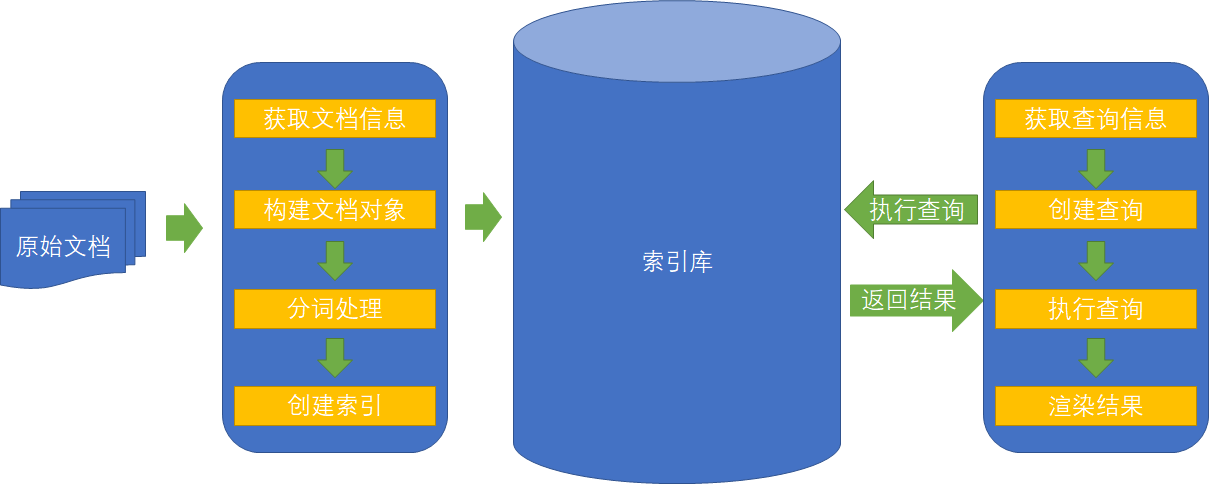
创建索引的步骤:原始文档 > 获取文档信息 > 构建文档对象 > Lucene对文档对象进行分词 > 创建索引
搜素文档的步骤:获得查询信息 > 创建查询 > 执行查询 > 渲染结果
重要流程
文档对象的创建
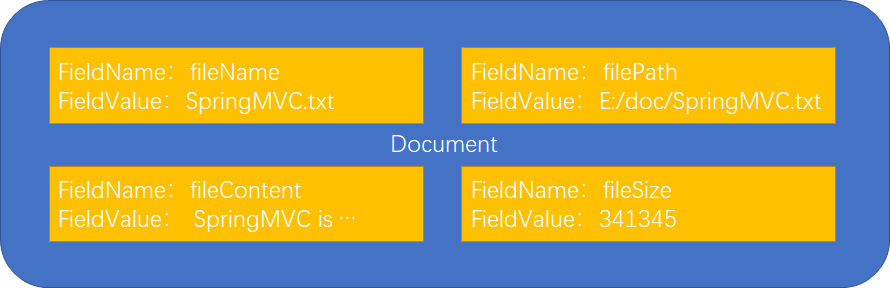
文档对象由多个域(Field)组成,每个Document 可以有多个Field,不同的Document 可以有不同的Field。同一个Document 可以有相同的Field(域名和域值都相同)每个文档都有一个唯一的编号(ID)。
分词的过程
对文档中的域进行分析:提取单词,将字母转为小写,去除标点,去除停用词生成最终的语汇单元。
原始:Lucene is a Java full-text search engine
分词:lucene java full search engine
每个单词叫做一个Term ,不同的域中拆分出来的相同的单词是不同的Term。Term 中包含两部分一部分是文档的域名, 另一部分是单词的内容。
三、Lucene 创建索引库
public void testCreateIndex() throws Exception {
// 创建分词器,采用标准分词器对英文支持好,中文支持差
Analyzer analyzer = new StandardAnalyzer();
// 索引库位置,FSDirectory会根据当前环境使用合适的方式打开例如NIOFSDirectory、MMapDirectory等
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 配置IndexWriter
IndexWriterConfig writerConfig = new IndexWriterConfig(analyzer);
// 创建IndexWriter
IndexWriter indexWriter = new IndexWriter(directory, writerConfig);
// 创建文档对象
List<Document> documents = new ArrayList<>();
File files = new File("E:/searchsource");
for (File file : files.listFiles()) {
Document document = new Document();
document.add(new TextField("fileName", file.getName(), Store.YES));
document.add(new TextField("filePath", file.getPath(), Store.YES));
document.add(new LongPoint("fileSize", file.length()));
document.add(new StoredField("fileSize",file.length()));
document.add(new TextField("fileContent", FileUtils.readFileToString(file), Store.NO));
documents.add(document);
}
// 写入文档对象
indexWriter.addDocuments(documents);
// 关闭indexWriter
indexWriter.close();
}
注意:
- IK分词器如今在GitHub维护,下载地址IK-Analyzer
- Luke索引查看工具也在GitHub维护,下载地址Luke
- Norm会更具文档长度自行计算(标准化因子,文档长度过长对重复次数评判有不公平性,使用Norm使之较为公平。例如100w字重复11次比1w字重复10次多会被错误的排在前方)
- Field类型
- TextField:分词、索引、可选存储
- StringField:不分词、索引、可选存储
- IntPoint/LongPoint/FloatPoint/DoublePoint:数字类型、索引、不存储(存储配合StoredField)
- SortedDocValuesField:按
byte[]建立正排索引 - SortedSetDocValuesField:按
SortedSet<byte[]>建立正排索引 - NumericDocValuesField:按
long建立正排索引 - SortedNumericDocValuesField:按
SortedSet<long>建立正排索引 - StoredField:不分词、不索引、存储
DocValues其实是Lucene在构建倒排索引时,会额外建立一个有序的正排索引(基于document => field value的映射列表)
正排索引用于排序、聚合、分组、高亮等
DocValues只允许有一个相同域名的域【字段是非数组eg: price:80】,DocValuesSet可以设置多个相同域名不同域值【字段是数组eg: price:[100, 80]】
四、Lucene 查询索引
Term精确查询
@Test
public void testTermSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 创建indexReader
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSerch = new IndexSearcher(indexReader);
// 精确查询条件
Query query = new TermQuery(new Term("fileContent", "apache"));
// 查询五条
TopDocs topDocs = indexSerch.search(query,5);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
TermQuery范围查询
@Test
public void testTermRangeSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 创建indexReader
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSerch = new IndexSearcher(indexReader);
// 范围查询条件(单词开头大于'b'结束小于'e'),不可以用于数字类型
Query query = new TermRangeQuery("fileName",new BytesRef("b"),new BytesRef("e"),true,true);
// 查询二十条
TopDocs topDocs = indexSerch.search(query,20);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
NumericalRange数字范围查询
@Test
public void testNumericalRangeSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 创建indexReader
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSerch = new IndexSearcher(indexReader);
// 数字范围查询。newRangeQuery包含开头结尾
// 如果想不包含请使用 Math.addExact(lowerValue[i], 1)或Math.addExact(upperValue[i], -1)处理
Query query = LongPoint.newRangeQuery("fileSize", 100L, 800L);
// 查询二十条
TopDocs topDocs = indexSerch.search(query,20);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
PrefixQuery前缀查询
@Test
public void testPrefixSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 创建indexReader
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSerch = new IndexSearcher(indexReader);
// 前缀查询。含有前缀apa的关键词
Query query = new PrefixQuery(new Term("fileName","apa"));
// 查询二十条
TopDocs topDocs = indexSerch.search(query,20);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
WildcardQuery通配符查询
@Test
public void testWildcardSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 创建indexReader
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSerch = new IndexSearcher(indexReader);
// 通配符查询,*代码任意个字符,?代表一位占位符
Query query = new WildcardQuery(new Term("fileName","?a*"));
//查询二十条
TopDocs topDocs = indexSerch.search(query,20);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
BooleanQuery多条件查询
@Test
public void testBooleanSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 创建indexReader
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSerch = new IndexSearcher(indexReader);
// Occur.MUST 必须 相当于 AND
// Occur.MUST_NOT 必须不 相当于 !
// Occur.SHOULD 应该 相当于OR
// Occur.FILTER 和MUST功能相同除了不参与计分,用于过滤替代了6.0之前的Filter
Builder queryBuilder = new BooleanQuery.Builder();
Query fileNameQuery = new TermQuery(new Term("fileName", "apache"));
Query fileContentQuery = new TermQuery(new Term("fileContent", "java"));
queryBuilder.add(fileNameQuery, Occur.MUST);
queryBuilder.add(fileContentQuery, Occur.SHOULD);
// 查询二十条
TopDocs topDocs = indexSerch.search(queryBuilder.build(),20);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
PhraseQuery短语查询
@Test
public void testPhraseSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 创建indexReader
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSerch = new IndexSearcher(indexReader);
// apache和solr相差十个单词以内
Query query = new PhraseQuery(10,"fileName","apache","solr");
// 查询二十条
TopDocs topDocs = indexSerch.search(query,20);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
Fuzzy模糊查询,允许匹配存在误差
@Test
public void testFuzzySearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 创建indexReader
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSerch = new IndexSearcher(indexReader);
// 允许aahe有两个字母不同(包括增加减少)例如可以匹配apache
Query query = new FuzzyQuery(new Term("fileName","aahe"),2);
// 查询二十条
TopDocs topDocs = indexSerch.search(query,20);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
QueryParser分析语句查询
@Test
public void testQueryParserSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 创建indexReader
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSerch = new IndexSearcher(indexReader);
// QueryParser需要传入分词器
QueryParser queryParser = new QueryParser("fileName",new StandardAnalyzer());
Query query = queryParser.parse("fileName:apache AND fileContent:java");
// 查询二十条
TopDocs topDocs = indexSerch.search(query,20);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
注意:queryParser.setAllowLeadingWildcard(false); 当为true时才可使用通配符和前缀查询
QueryParser查询语法:
| 符号 | 作用 | 例子 | 描述 |
|---|---|---|---|
| + | 相当于MUST 必须满足 | +fileName:apache AND fileName:solr | 必须满足第一个条件,第二个可以不满足(第二个条件此种情况下无效,不论AND\OR) |
| # | 相当于FILTER必须满足不计分 | #fileName:apache AND fileName:solr | 必须满足第一个条件,第二个可以不满足(第二个条件此种情况下无效,不论AND\OR) |
| - | 相当于MUST NOT 必须不满足 | -fileName:apache AND fileName:solr | 必须不满足第一个条件,第二个必须不满足(第二个条件此种情况下必须满足不论AND\OR) |
| AND | 并且,左右两边条件必须满足 | fileName:apache AND fileName:solr | 左右两个条件必须满足 |
| OR | 或者,左右两边条件满足一个 | fileName:apache OR fileName:solr | 可以使用空格达到同样的效果 |
| “语句” | 必须完全匹配语句 | fileName:”apache lucene.txt” | 必须安全匹配apache lucene |
| */? | 通配符匹配 | fileName:apa* | 文件名单词含有apa开头的 |
| ~ | 短语匹配 | fileName:”apache solr” ~10 | apache和solr相差十个单词以内 |
| ~ | 模糊匹配 | fileName:apecha~0.4 | 模糊匹配,默认相似的0.5 |
| [x TO y] | 字符串范围匹配 | fileName:[a TO b] | 使用的比较规则是字符串比较规则,先比较首字母然后依次类推,不包含使用{} |
| ^ | 改变提升因子 | fileName:apache^4 | fileName为apache的分数上升 |
| 字段:(+索引 +索引) | 字段分组 | fileName:(+apache +solr) | fileName既包含apache又包含solr |
注:DirectoryReader.open(Directory directory)打开之后并不会跟随IndexWriter的删除而感知到。DirectoryReader.openIfChanged(DirectoryReader oldReader)如果索引文件发生变化返回一个新的IndexReader,如果索引文件没有变化返回null可以进行感知;
五、Lucene 排序
@Test
public void testSortSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
QueryParser queryParser = new QueryParser("fileName",new StandardAnalyzer());
Query query = queryParser.parse("*:* fileName:apache");
// 按照分数排序,倒数第二个参数是是否计算分数,false不计算结果为NAN
// 最后一个参数为是否计算最高分
TopDocs topDocs = indexSearcher.search(query,20,Sort.RELEVANCE,true,false);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSearcher.doc(scoreDoc.doc);
System.out.println("id:"+doc.get("id"));
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
indexReader.close();
}
Sort的默认有两种
- Sort.RELEVANCE 按照分数排序
- Sort.INDEXORDER 按照序号排序,创建lucene的Document顺序
Sort的自定义实现
- 使用自然比较
//使用Long类型比较,第三个参数是否翻转排序结果
//自定义排序需要在Field上存储对应的DocValuesField才能排序,目的是提高效率
SortField sortField = new SortField("fileSize", Type.LONG, false);
Sort sort = new Sort(sortField);
TopDocs topDocs = indexSearcher.search(query,20,sort,true,false);
-
使用自定义比较规则
- 第一步创建自定义比较器
public class MyCoustomFieldComparatorSource extends FieldComparatorSource { /** * 创建自定义比较器: * fieldname 字段名 * numHits 查出总记录数 * reversed 是否翻转 */ @Override public FieldComparator<?> newComparator(String fieldname, int numHits, int sortPos, boolean reversed) { return new MyCoustomFieldComparator(fieldname,numHits); } private class MyCoustomFieldComparator extends SimpleFieldComparator<String> { private String values[]; private String fieldName; private String top; private String bottom; private LeafReaderContext leafReaderContext; public MyCoustomFieldComparator(String fieldname,int numHits) { this.fieldName = fieldname; this.values = new String[numHits]; } // 设置LeafReaderContext @Override protected void doSetNextReader(LeafReaderContext context) throws IOException { this.leafReaderContext = context; } // 存储所有值slot当前下标,doc文档ID @Override public void copy(int slot, int doc) throws IOException { values[slot] = leafReaderContext.reader().document(doc).getField(fieldName).stringValue(); } // 比较两个值,slot1,slot2下标 @Override public int compare(int slot1, int slot2) { return Integer.compare(values[slot1].length(), values[slot2].length()); } // 得到值,slot下标 @Override public String value(int slot) { return values[slot]; } // 设置最小值,slot最小值下标 @Override public void setBottom(int slot) throws IOException { bottom = values[slot]; } // 设置最大值,value最大值 @Override public void setTopValue(String value) { this.top = value; } // 和最小值比较,doc当前要比较的文档ID @Override public int compareBottom(int doc) throws IOException { String currentFileName = leafReaderContext.reader().document(doc).getField(fieldName).stringValue(); return Integer.compare(bottom.length(), currentFileName.length()); } // 和最大值比较,doc当前要比较的文档ID @Override public int compareTop(int doc) throws IOException { String currentFileName = leafReaderContext.reader().document(doc).getField(fieldName).stringValue(); return Integer.compare(top.length(), currentFileName.length()); } } }- 第二步使用自定义比较器进行排序
@Test public void testSortSearch2() throws Exception { Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex")); DirectoryReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); QueryParser queryParser = new QueryParser("",new StandardAnalyzer()); Query query = queryParser.parse("*:*"); // 创建自定义比较器 MyCoustomFieldComparatorSource myCoustomFieldComparatorSource = new MyCoustomFieldComparatorSource(); // 创建SortField使用自定义比较器 SortField sortField = new SortField("fileName", myCoustomFieldComparatorSource); Sort sort = new Sort(sortField); TopDocs topDocs = indexSearcher.search(query,20,sort,true,false); // 查询的总数 System.out.println("totalHits:"+topDocs.totalHits); for (ScoreDoc scoreDoc : topDocs.scoreDocs) { // 获得分数 System.out.println("score:"+scoreDoc.score); // 获得文档 Document doc = indexSearcher.doc(scoreDoc.doc); System.out.println("id:"+doc.get("id")); System.out.println("fileName:"+doc.get("fileName")); System.out.println("filePath:"+doc.get("filePath")); System.out.println("fileSize:"+doc.get("fileSize")); System.out.println("fileContent:"+doc.get("fileContent")); } indexReader.close(); }
六、Lucene 查询高亮
- 使用Highlighter实现高亮
@Test
public void testhighlighterSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
Analyzer analyzer = new StandardAnalyzer();
QueryParser queryParser = new QueryParser("fileName",analyzer);
Query query = queryParser.parse("fileName:apache");
// 高亮相关部分创建
QueryScorer queryScorer = new QueryScorer(query);
// 简单的分段器
Fragmenter fragmenter = new SimpleFragmenter();
// 格式
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
// 高亮查询器
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, queryScorer);
// 设置分段,会将长内容拿出含有关键字的部分
highlighter.setTextFragmenter(fragmenter);
TopDocs topDocs = indexSearcher.search(query, 20);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSearcher.doc(scoreDoc.doc);
System.out.println("id:"+doc.get("id"));
String fileName = doc.get("fileName");
System.out.println("fileName:"+ fileName);
if(fileName != null) {
// 得到对应的TokenStream
TokenStream tokenStream = analyzer.tokenStream("fileName", fileName);
// 拿出得分最高的段
String highLightText = highlighter.getBestFragment(tokenStream,fileName);
System.out.println(highLightText);
}
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
String fileContent = doc.get("fileContent");
if(fileContent != null) {
// 得到对应的TokenStream
TokenStream tokenStream = analyzer.tokenStream("fileContent", fileContent);
// 拿出得分最高的段
String highLightText = highlighter.getBestFragment(tokenStream, fileContent);
System.out.println(highLightText);
}
}
indexReader.close();
}
- 使用FastVectorHighlighter实现高亮,适合大文档
/**
* 使用FastVectorHighlighter前置条件是字段创建时存储相关信息,牺牲存储换取时间
* FieldType fileNameFieldType = new FieldType();
* fileNameFieldType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS);
* fileNameFieldType.setTokenized(true);
* fileNameFieldType.setStored(true);
* fileNameFieldType.setStoreTermVectorOffsets(true); //记录相对增量
* fileNameFieldType.setStoreTermVectorPositions(true); //记录位置信息
* fileNameFieldType.setStoreTermVectors(true); //存储向量信息
* fileNameFieldType.freeze(); //阻止改动信息
* Field fileNameField = new Field("fileName", file.getName(), fileNameFieldType);
* document.add(fileNameField);
*/
@Test
public void testfastVectorHighlighterSearch() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
Analyzer analyzer = new StandardAnalyzer();
QueryParser queryParser = new QueryParser("fileName",analyzer);
Query query = queryParser.parse("fileName:apache");
TopDocs topDocs = indexSearcher.search(query, 20);
// 高亮相关部分创建
FragListBuilder fragListBuilder = new SimpleFragListBuilder();
FragmentsBuilder fragmentsBuilder = new SimpleFragmentsBuilder(
BaseFragmentsBuilder.COLORED_PRE_TAGS,
BaseFragmentsBuilder.COLORED_POST_TAGS);
FastVectorHighlighter fastVectorHighlighter = new FastVectorHighlighter(
true, true,fragListBuilder,fragmentsBuilder);
FieldQuery fieldquery = fastVectorHighlighter.getFieldQuery(query);
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSearcher.doc(scoreDoc.doc);
System.out.println("id:"+doc.get("id"));
String fileName = doc.get("fileName");
System.out.println("fileName:"+ fileName);
if(fileName != null) {
String highLightText = fastVectorHighlighter.getBestFragment(
fieldquery, indexSearcher.getIndexReader(),
scoreDoc.doc, "fileName",100);
System.out.println(highLightText);
}
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
String fileContent = doc.get("fileContent");
if(fileContent != null) {
String highLightText = fastVectorHighlighter.getBestFragment(
fieldquery, indexSearcher.getIndexReader(),
scoreDoc.doc, "fileContent", 100);
System.out.println(highLightText);
}
}
indexReader.close();
}
七、Lucene 分页
- 方式一,使用下标获取对象
TopDocs topDocs = indexSerch.search(query,200);
// 获取第十条到第十五条记录
int startPos =10;
int endPos =15;
// 查询的总数
System.out.println("totalHits:"+topDocs.totalHits);
for (int i = startPos; i < endPos; i++) {
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
- 方式二,使用searchAfter传入最后一个查询到的对象
ScoreDoc currentScoreDoc = null;
// 每页数量
int pageSize = 5;
// 要查询第几页
int nextPage = 3;
if(nextPage != 1) {
// 获取上一页的最后是第多少条
int num = pageSize*(nextPage-1);
TopDocs td = indexSerch.search(query, num);
currentScoreDoc = td.scoreDocs[num-1];
}
// 在最后一页的基础上在查几条
TopDocs topDocs = indexSerch.searchAfter(currentScoreDoc, query, pageSize);
System.out.println("totalHits:"+topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 获得分数
System.out.println("score:"+scoreDoc.score);
// 获得文档
Document doc = indexSerch.doc(scoreDoc.doc);
System.out.println("fileName:"+doc.get("fileName"));
System.out.println("filePath:"+doc.get("filePath"));
System.out.println("fileSize:"+doc.get("fileSize"));
System.out.println("fileContent:"+doc.get("fileContent"));
}
八、Lucene 删除索引
删除所有索引
@Test
public void testDeleteIndex() throws Exception {
Analyzer analyzer = new StandardAnalyzer();
// 索引库位置
Directory directory = NIOFSDirectory.open(Paths.get("E:/luceneIndex"));
// 配置IndexWriter
IndexWriterConfig writerConfig = new IndexWriterConfig(analyzer);
// 创建IndexWriter
IndexWriter indexWriter = new IndexWriter(directory, writerConfig);
// 删除所有索引
indexWriter.deleteAll();
// 提交删除,会清空所有
indexWriter.commit();
indexWriter.close();
}
删除查询出的索引
@Test
public void testRangeDeleteIndex() throws Exception {
Analyzer analyzer = new StandardAnalyzer();
// 索引库位置
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 配置IndexWriter
IndexWriterConfig writerConfig = new IndexWriterConfig(analyzer);
// 创建IndexWriter
IndexWriter indexWriter = new IndexWriter(directory, writerConfig);
Query query = LongPoint.newRangeQuery("fileSize", 1000, 100000);
// 删除
indexWriter.deleteDocuments(query);
// 提交删除,会将删除的内容存放与“回收站中”
indexWriter.commit();
// 在未关闭indexWriter的时间段,可以查询到总条数,总可查询条数,总删除条数
Thread.sleep(100000L);
indexWriter.close();
}
查询总记录数、可查询条数、回收站删除条数
System.out.println("maxDoc:"+indexReader.maxDoc());
System.out.println("numDocs:"+indexReader.numDocs());
System.out.println("numDeletedDocs:"+indexReader.numDeletedDocs());
九、Lucene 修改索引
修改索引的本质是删除匹配的索引添加新的索引
@Test
public void testModifyIndex() throws Exception {
Analyzer analyzer = new StandardAnalyzer();
// 索引库位置
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
// 配置IndexWriter
IndexWriterConfig writerConfig = new IndexWriterConfig(analyzer);
// 创建IndexWriter
IndexWriter indexWriter = new IndexWriter(directory, writerConfig);
// 要修改的Term
Term termOld = new Term("fileName","apache");
// 要添加的Document
Document newDoc = new Document();
newDoc.add(new TextField("fileName", "GOGOGO", Store.YES));
newDoc.add(new TextField("fileContent", "GOGOGO WOWOWO", Store.YES));
// 更新
indexWriter.updateDocument(termOld, newDoc);
// 提交
indexWriter.commit();
indexWriter.close();
}
十、Lucene Analyzer
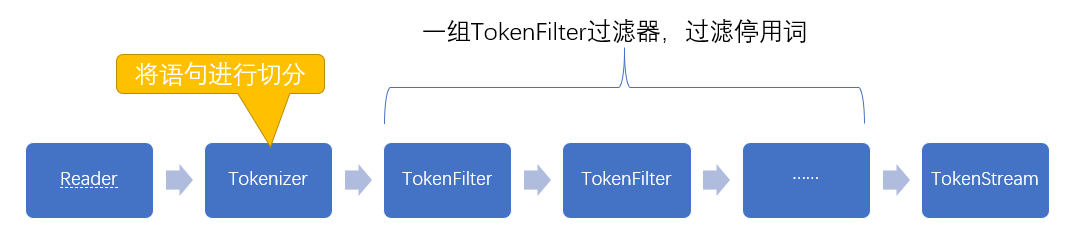
- Tokenizer:主要负责接收字符流Reader,将Reader进行分词操作
- TokenFilter:将分好词的语汇单元进行各种过滤
- TokenStream:分词器处理完成得到的一个流,这个流中存储了分词的各种信息,可以通过TokenStream有效的获取到分词单元
TokenStream主要存储的元素信息:
- CharTermAttribute 存储每个语汇单元的信息,用于做filter
- OffsetAttribute 每个语汇单元的偏移量
- PositionIncrementAttribute 存储语汇单元之间的距离,可以做同义词
- TypeAttribute 使用的分词器的类型信息
十一、lucene 近实时搜索
@Test
public void testNearRealTimeSearching() throws Exception {
Directory directory = FSDirectory.open(Paths.get("E:/luceneIndex"));
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(standardAnalyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 创建SearchManager实现近实时搜索
SearcherManager searcherManager = new SearcherManager(indexWriter,true,true,new SearcherFactory());
// 将SearcherManager给ControlledRealTimeReopenThread管理用于自动更新索引
ControlledRealTimeReopenThread<IndexSearcher> CRTReopenThread =
new ControlledRealTimeReopenThread<IndexSearcher>(indexWriter, searcherManager,5.0, 0.025) ;
// 设置为后台进程
CRTReopenThread.setDaemon(true);
CRTReopenThread.setName("lucene后台刷新服务");
CRTReopenThread.start();
//从SearchMananger得到IndexSearch
IndexSearcher indexSearcher = searcherManager.acquire();
}
其他
IndexWriter下的,不要手动调用,lucene会在合适的时候自己调用优化结构
- public void forceMerge(int maxNumSegments, boolean doWait) 将段文件合并
- public void forceMergeDeletes(boolean doWait) 删除”回收站“文件
读取各种各样的文档会使用对应的工具类例如,先可以使用Tika来读取各种文档信息,Tika实现了可视化界面用于查看信息官网提供了tika-app-版本号.jar的jar包下载
- PDF使用PDFBox
- Excel、WORD、PPT使用Apache POI
- 读取TXT使用Apache Common IO
Tika使用方式一
static private Tika tika = new Tika();
static public String fileToTxt(File file,Metadata metadata) throws IOException, TikaException {
// Metadata 元数据信息
return tika.parseToString(new FileInputStream(file),metadata);
}
Tika使用方式二
static private Parser parser;
static private ContentHandler contentHandler;
static private ParseContext parseContext;
static {
// 自动解析器
parser = new AutoDetectParser();
// 创建ContentHandler,解析结果为XML格式,只解析内容
contentHandler = new BodyContentHandler();
// 创建Context
parseContext = new ParseContext();
parseContext.set(Parser.class,parser);
}
public static String fileToTxt(File file,Metadata metadata) throws IOException, SAXException, TikaException {
parser.parse(new FileInputStream(file),contentHandler, metadata,parseContext);
return contentHandler.toString();
}