logstash的使用
一、Logstash架构简介
简介
logstash是一个数据收集处理引擎,可是视之为一个ETL工具。
架构
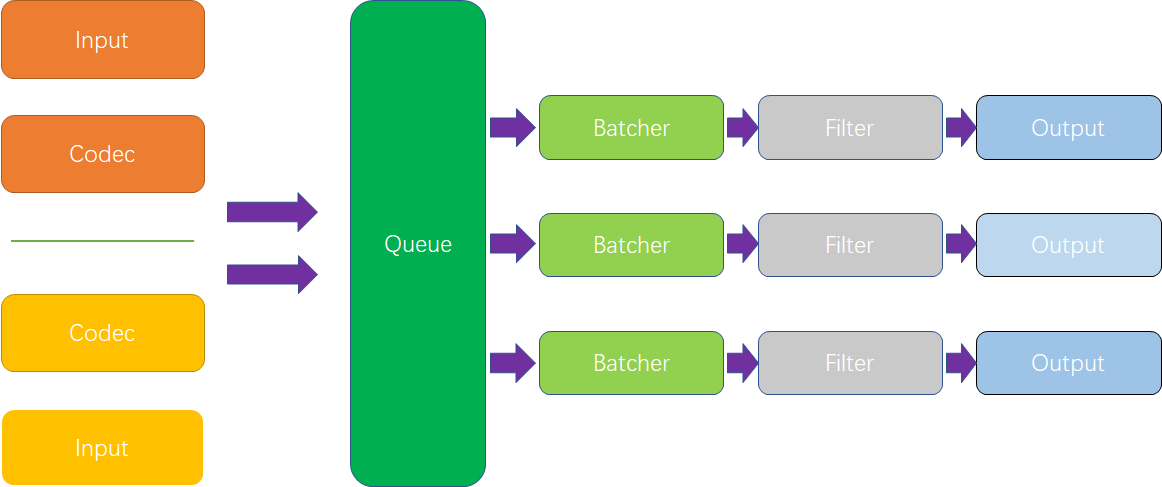
- Input 用于从数据源获取数据,常见的插件如
file,syslog,redis,beats等 - Codec 在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如
json,multiline - Queue 数据回经过Queue进行分发,有
In Memory和Persistent Queue In Disk两种 - Batcher 批量的从Queue中取数据,向后传递数据。默认50ms或者待处理文档数大于125时向后传递
- Filter 用于处理数据如格式转换,数据派生等,常见的插件如
grok,mutate,drop,clone,geoip等 - Output 用于数据输出,常见的如
elastcisearch,file,graphite,statsd等
Pipeline和Logstash Event
Pipline由【Input】-【Filter】-【Output】3个阶段处理流程组成,包含了队列管理和插件生命周期管理
Logstash Event是内部流转的数据的表现形式。原数据在Input转换为Event,在Output event时被转换为目标数据格式,在配置文件中可以对Event中的属性进行判断和增删改查
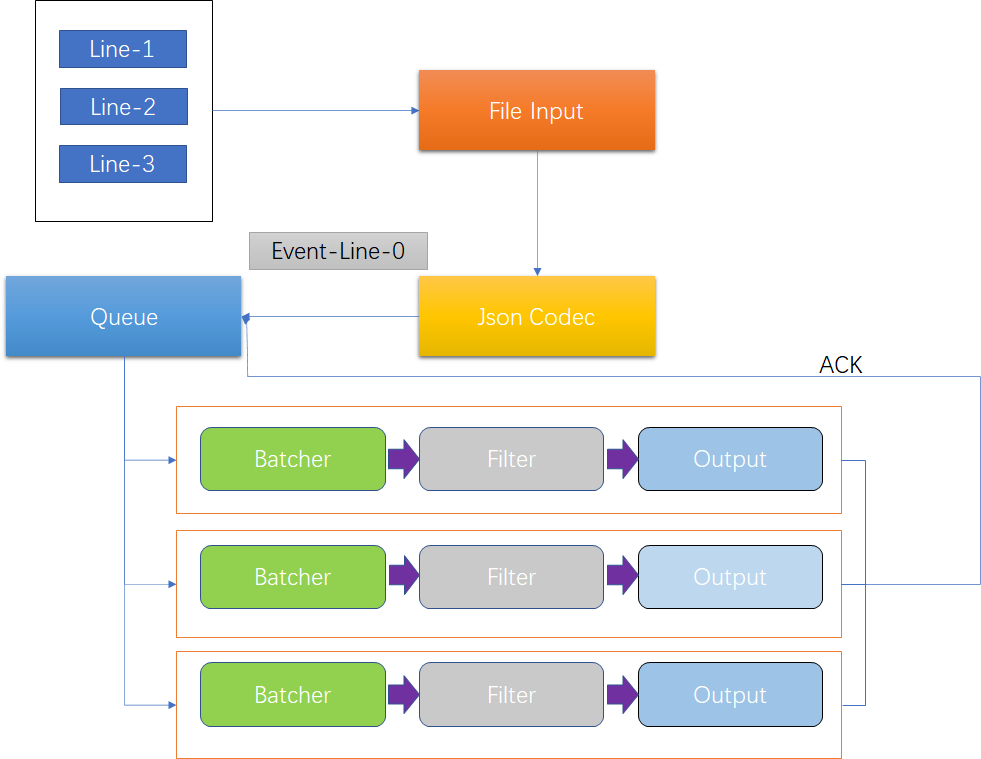
Queue的分类
In Memory
是一个内存的Queue,无法通过参数设置。无法处理进程崩溃、机器宕机等情况,会导致数据丢失
Persistent Queue In Disk
可保证在出现意外的情况下保证数据不丢失,而且能保证数据至少被消费一次
Persistent Queue In Disk对性能影响估计是在5%以内,如果没有特殊需求一般建议打开
| 参数 | 解释 |
|---|---|
| queue.type | 队列类型可选值:persisted、memory【默认】 |
| queue.max_bytes | 队列存储的最大容量,默认1gb |
| path.queue | Persistent Queue In Disk存到磁盘的哪个位置 |
| queue.page_capacity | 控制消息队列每一个文件的大小,默认64mb |
| queue.checkpoint.writes | 提升容灾能力,如果是1 表示每写一个数据都去做盘,默认1024 |
| pipeline.workers | filter_output的线程数,默认CPU核心数 |
| pipeline.batch.size | 批处理延迟文档数,默认125 |
| pipeline.batch.delay | 批处理延迟,默认50ms |
Logstash配置文件
在conf文件夹中被称之为setting files
logstash.yml中是logstash相关配置比如node.name,path.data,pipline.workers、queue.type等,这些配置可以被命令行参数替代
| 参数 | 描述 |
|---|---|
| node.name | 节点名,便于识别 |
| path.data | 持久化存储数据文件夹,默认logstash下的data目录,多实例不能相同 |
| path.config | 设定pipeline的路径,如果是目录则扫描目录下的所有.conf文件 |
| path.log | pipeline日志文件的目录 |
| pipeline.workers | 设定pipeline的线程数 |
| pipeline.batch.size/delay | 批处理延迟 |
| queue.type | 队列类型可选值:persisted、memory |
| queue.max_bytes | 队列存储的最大容量,默认1gb |
| 命令行参数 | 描述 |
|---|---|
| –node.name | 同node.name |
| -f | 同path.config |
| –path.settings | logstash文件夹目录主要包含logstash.yml,启动多实例时会用 |
| -e | 指明pipeline文件内容,多用于测试 |
| -w | 同pipeline.workers |
| -b | 同pipeline.batch.size |
| –path.data | 同path.data |
| –debug | 打开调试日志 |
| -t | 检测pipeline文件语法是否正确 |
jvm.options是修改jvm的相关参数
pipeline文件
-
定义数据处理流程的文件,默认以
.conf结尾,结构如下input {} filter {} output {}
Pipeline配置语法
数据类型
-
布尔类型 isFailed => true
-
数值类型 num => 23
-
字符串类型 name => “Hello”
-
数组类型 user => [ { “id” =>1, “name” => “bob” }, { “id” => 2, “name” => “tom” } ] name => [ “bob” , “tom” ] -
哈希类型
match => { "k1" => "v1" "k2" => "v2" }
注释
井号开头# This is a comment
取属性
- 直接引用字段 使用[]取出,嵌套使用多层[]即可
- 字符串使用引用值 使用引用sprintf语法%{}
判断值
- 可以if、else if、else语法
- 判断的表达式
- 比较 ==,!=,<,>,<=,>=
- 正则是否匹配 =~,!~
- 包含 in,not in
- 布尔操作符 and,or,nand,xor,!
二、Input插件
input插件指定了数据输入源,一个pipeline可以有多个input插件。
stdin插件
最简单的输入类型,从标准输入流读入数据,通用配置为
- codec,类型为codec
- type,类型为string,自定义该事件的类型,可用于后续判断
- tags,类型为array,自定义该事件的tag,可用于后续判断
- add_field,类型为hash,为该事件添加字段
input {
stdin {
codec => "plain"
type => "std"
tags => ["info log"]
add_field => {
"info" => "this is info message"
}
}
}
output {
stdout {
codec => "rubydebug"
}
}
file插件
file插件会定时检查文件是否更新和文件夹下是否有新文件生成,为了不重复读取内容,使用了sincedb记录了文件读取的行号。文件记录的的底层的nodeId所以当文件发生归档时也不会发生错误。其配置为
- path,类型为数组,指明读取文件的路径,基于
glob语法 - exclude,类型为数组,排除不想监听的文件规则,基于
glob语法 - sincedb_path,类型为字符串,记录
sincedb文件路径 - start_position,类型为字符串,
beginningorend,是否从头读取文件 - stat_interval,类型为数值,单位秒,定时检查文件是否有更新,默认为1s
- discover_interval,类型为数值,单位秒,定时检查是否有新文件待读取,默认15s
- ignore_older,类型为数值,单位秒,扫描文件列表时,如果该文件上次更改时间超过设定时长,则不做处理,但依然会监控是否有新的内容,默认关闭
- close_older,类型为数值,单位秒,如果监听的文件在超过的时间范围内没有更新则关闭文件句柄,释放资源。但是依然会继续监控,默认时间3600秒
start_postion有两个参数可选,默认是end,表示运行logstash运行之后只会读取从logstash运行之后新进来的数据。如果想让logstash从头读取要设置为beginning。注意只有在第一次读取的时候这个beginning才生效,一旦读取过这个文件在sincedb中有记录了,logstash之后再去跑发现在sincedb中有记录了,就不会生效了也就是不会再从头读取了。这个的坏处就是我们做一些调试的时候比较麻烦只能把sincedb文件给删掉。我们可以把sincedb_path设置为/dev/null 这是个特殊的文件,所有写入到这个文件的内容都不会存储,那么这样再把start_postion设置为beginning这样每一次运行logstash的时候都是从头读取的。
input {
file {
path => "/var/log/*.log"
sincedb_path => "/dev/null"
start_position => "beginning"
discover_interval => 15
}
}
output {
stdout {codec => rubydebug {}}
}
kafka插件
kafka是最流行的消息队列,在Elastic Stack架构中常用,使用相对简单
input {
kafka {
zk_connect => "kafka:2181"
group_id => "logstash"
topic_id => "apache_logs"
consumer_threads => 16
}
}
output {
stdout {codec => rubydebug {}}
}
http插件
常和启动参数-r连用,用于热调试
input {
http {
port => "5555"
}
}
output {
stdout {codec => rubydebug {}}
}
三、Codec插件
codec插件作用于input插件和output插件,负责将数据在原始于logstash event之间转换,常见的codec有
- plain 读取原始内容
- dots 将内容简化为点进行输出
- rubydebug 将
Logstash Event按照ruby格式输出,便于调试 - line 处理带有换行符的内容
- json 处理json内容
- multiline 处理多行数据的内容
plain&dots&rubydebug
bin/logstash -e "input{stdin{codec=>\"plain\"}} output{stdout{codec=>\"rubydebug\"}}"
bin/logstash -e "input{stdin{codec=>\"plain\"}} output{stdout{codec=>\"dots\"}}"
line&json
bin/logstash -e "input{stdin{codec=>\"line\"}} output{stdout{codec=>\"rubydebug\"}}"
bin/logstash -e "input{stdin{codec=>\"json\"}} output{stdout{codec=>\"rubydebug\"}}"
multiline
当一个Event的message由多行组成时需要使用mutiline codec,常见的情况时处理Java堆栈异常。主要参数如下
- pattern 设置行匹配的正则表达式,可以使用
grok语法 -
what previous next 如果匹配成功,那么匹配行是属于上一个时间还剩下一个事件 -
negate true false 是否对 pattern匹配结果取反,默认false
##################################以下可以用于简单读取java堆栈跟踪日志##################################
input {
stdin {
codec => multiline {
what => "next"
negate => false
}
}
}
output {
stdout {
codec => "rubydebug"
}
}
四、Filter插件
Filter是logstash功能强大的主要原因,它可以对Logstash Event进行丰富的处理,比如数据解析、删除字段、类型转换等等。常见如下:
- date 日期解析
- grok 正则匹配解析
- dissect 分割符解析
- mutate 对字段处理,比如重命名、删除、替换等
- json 按照json解析字段内容到指定字段中
- geoip 增加地理位置数据
- ruby 利用ruby代码来修改
Logstash Event
Date Filter
将日期字符串解析为日期类型
- match 类型为数组,用于指定日期匹配格式,可以一次指定多种日期格式
- target 类型为字符串,用于指定赋值的字段名,默认为@timestamp
- timezone 类型为字符串,用于指定时区
input {
stdin {
codec => json
}
}
filter {
date {
# 匹配的字段
match => ["log_date", "yyyy-MM-dd HH:mm:ss"]
# 赋值目标字段,如果不设置则会覆盖@timestamp,如果设置时区而且覆盖本字段,时区无效
target => "log_data"
# 时区设置
timezone => "Asia/Shanghai"
}
}
output{
stdout {
codec => rubydebug
}
}
Grok Filter
使用定义好的或者自定义的正则表达式进行匹配,已定义的常用正则查看参考
Grok语法为%{SYNTAX:SEMANTIC},SYNTAX为grok pattern的名称,SEMANTIC为赋值字段名称。%{NUMBER:duration}可以用于匹配数值类型,可以在后跟int或float来进行强制类型转换,例如%{NUMBER:duration:int}。如果匹配失败将会有一个_grokparsefailure字段产生,可用于后续判断
##################################使用系统定义的pattern##################################
filter {
grok {
match => { "message"=>"%{IP:ip} %{GREEDYDATA:data}"}
}
}
##################################使用自定义的pattern##################################
filter {
grok {
match => { "message"=>"%{IP:ip} %{SERVICE_NAME:service_name} %{GREEDYDATA:data}"}
pattern_definitions => {
"SERVICE_NAME" => "[a-zA-Z]{5}"
}
}
}
###################################overwrite的使用###################################
filter {
grok {
match => { "message"=>"%{IP:ip} %{GREEDYDATA:message}"}
overwrite => ["message"] #将上述匹配的message信息覆盖到message,如果没有overwrite将不执行覆盖操作
}
}
Dissect Filter
基于分隔符的原理进行解析数据,数据比grok快,但是使用具有局限性
+具有拼接效果/num代表拼接的顺序?代表创建一个属性名,&代表给?的属性名赋值convert_datatype可以进行类型转换
filter {
dissect {
mapping => {
"message" => "%{+ts/2} %{+ts/1}"
"urlParams" => "%{?username}=%{&username}"
}
convert_datatype => {
"age" => "int"
}
}
}
Mutate Filter
可以对各种字段进行各种操作,比如重命名、删除、替换、更新等。主要操作如下:
- convert 类型转换
- gsub 字符串替换
- split/join/merge 字符串切割、数组合并为字符串、数组合并为数组
- rename 字段重命名
- update/rename 字段重命名
- remove_field 删除字段
############################################################################
#convert 实现字段类型转换,类型为hash,支持转换为integer、float、string和boolean #
############################################################################
filter {
mutate {
convert => {
"age" => "integer"
"isLived" => "boolean"
}
}
}
############################################################################
#gsub 对字段内容进行替换,类型为数组,每三项为一个替换配置 #
############################################################################
filter {
mutate {
gsub => [
"path","[\\]","/",
"urlParams","[\\?#-]","."
]
}
}
############################################################################
#split/join/merge 字符串切割、数组合并为字符串、数组合并为数组 #
############################################################################
filter {
mutate {
split => {"jobs" => ","}
join => {"hobby" => ","}
merge => {"dest_arr" => "source_arr"}
}
}
############################################################################
#rename 将字段重命名 #
############################################################################
filter {
mutate {
rename => {
"message" => "source"
"@timestamp" => "create_time"
}
}
}
############################################################################
#update 只在字段存在时生效 #
#replace 如果字段不存在会执行新增操作 #
############################################################################
filter {
mutate {
replace => {"source" => "source: %{message}"}
update => {"age" => "This is %{age}"}
}
}
############################################################################
#remove_field 删除字段 #
############################################################################
filter {
mutate {
remove_field => ["@timestamp"]
}
}
Json Filter
将字段内容为json格式的数据进行解析
# 注意不能在http的Post的entity为Json的状态下测试
filter {
json {
source => "message"
# 如果没有target它将会被放在root级别,如果有target将会放在target下
target => "msg_json"
}
}
GeoIp Filter
提供了根据Ip地址对应的经纬度、城市名等数据的查询,方便进行地理位置的分析
filter {
geoip {
source => "ip"
}
}
ruby Filter
最灵活的插件,可以通过ruby代码来修改Logstash Event
filter {
ruby {
codec => 'size = event.get("message").size;
event.set("message_size", size)'
}
}
五、Output插件
stdout插件
输出到标准输出流,一般用于调试
output {
stdout {
codec => rubydebug
}
}
file插件
输出到文件,一般用于将多地分散日志统一的需求
# 默认以json格式进行输出,下面改为了行输出,输出Event中的format字段
output {
file {
path => "/opt/web.log"
codec => line{ format => "%{message}"}
}
}
elasticsearch插件
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nginx-%{+YYYY.MM.dd}"
document_id => "%{id}" #作为ID的字段
}
}
六、调试技巧
特殊字段
存在一个@metadata的字段,其内容不会输出在output中,此字段适合用于做条件判断,临时存储等。相比remove_field性能好。
input {
http {
port => 5555
}
}
filter {
mutate {
add_field => {
"[@metadata][debug]"=> true
}
}
}
output {
if([@metadata][debug]) {
stdout {
codec => rubydebug
}
}else {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nginx-%{+YYYY.MM.dd}"
}
}
}
监控
在logstash.yml下打开xpack监控配置,即可在elasticsearch中查看logstash状态
xpack.monitoring.elasticsearch.hosts: ["http://192.168.1.155:9200"] #注意http
七、从MySQL导入数据到ES
第一步:环境准备
-
数据库如果做增量数据导入,必须提高一个可控边界。可控边界一般使用自增主键或者时间戳
-
logstash不能创建ElasticSearch中的索引,所以需要手工创建索引或使用索引模板
-
导入mysql驱动jar包。最佳保存在$logstash_home/config目录中
第二步:定义logstash-mysql增量导入配置文件
$logstash_home/config创建文件logstash-mysql-es.conf
input {
jdbc {
# mysql相关jdbc配置
jdbc_connection_string => "jdbc:mysql://192.168.1.117:3306/logstash?useUnicode=true&characterEncoding=utf-8&useSSL=false"
jdbc_user => "root"
jdbc_password => "123456"
# jdbc连接mysql驱动的文件目录
jdbc_driver_library => "./config/mysql-connector-java-5.1.5.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => true
jdbc_page_size => "50000"
jdbc_default_timezone =>"Asia/Shanghai"
# 可以直接写SQL语句在此处,使用大于等于避免丢失数据。如下:
statement => "select * from test_logstash where update_time >= :sql_last_value"
# 也可以将SQL定义在文件中,如下:
#statement_filepath => "./config/jdbc.sql"
# 这里类似crontab,可以定制定时操作,比如每分钟执行一次同步(分 时 天 月 年)
schedule => "* * * * *"
# 在ES6.x版本中,不需要定义type。即使定义,logstash也是自动创建索引type为doc
#type => "doc"
# 是否记录上次执行结果, 如果为真,将会把上次执行到的tracking_column字段的值记录下来,保存到last_run_metadata_path指定的文件中,对磁盘的存储压力太大
#record_last_run => true
# 是否需要记录某个column的值,如果record_last_run为真,可以自定义我们需要track的column名称,此时该参数就要为true。否则默认track的是timestamp的值
use_column_value => true
# 如果use_column_value为真,需配置此参数.track的数据库column名,该column必须是递增的. 一般是mysql主键
tracking_column => "update_time"
tracking_column_type => "timestamp"
last_run_metadata_path => "./logstash_capital_bill_last_id"
# 是否清除last_run_metadata_path的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => false
#是否将字段(column)名称转小写
lowercase_column_names => false
}
}
output {
elasticsearch {
hosts => "localhost:9200" #如果是多个ES,使用逗号分隔多个ip和端口
index => "mysql_datas" #索引名称
document_id => "%{id}" #数据库中数据与ES中document数据关联的字段,此处代表数据库中的id字段和ES中的document的id关联
template_overwrite => true #是否使用模板,开启效率更高
}
# 这里输出调试,正式运行时可以注释掉
stdout {
codec => json_lines
}
}
第三步:启动
bin/logstash -f config/logstash-mysql-es.conf
八、从CSV中导出数据到ES
input {
file {
path => "/opt/elasticsearch/logstash/instance2/earthquakes.csv"
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
csv {
columns => ["dateTime","latitude","longitude","depth","magnitude","magType",
"nbStations","gap","distance","rms","source","eventID"]
convert => {
"latitude" => "float"
"longitude" => "float"
"depth" => "float"
"rms" => "float"
"gap" => "float"
}
}
date {
match => ["dateTime", "yyyy/MM/dd HH:mm:ss.SS"]
timezone => "Asia/Shanghai"
}
mutate {
add_field => {
"[@metadata][debug]"=> true
}
}
}
output {
if([@metadata][debug]) {
stdout {
codec => rubydebug
}
}else {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "csv_datas"
}
}
}