elasticsearch技术
一、ElasticSearch概念
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
ElasticSearch的特点
(1)可以作为一个大型分布式集群技术,处理PB级数据,服务大公司。也可以运行在单机上,服务小公司
(2)对用户而言,是开箱即用的,非常简单
(3)弥补数据库在全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理的不足
ElasticSearch的相关概念
-
cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是通过选举产生的,主从节点是对于集群内部来说的。ElasticSearch的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看ElasticSearch集群,在逻辑上是个整体,与任何一个节点的通信和与整个ElasticSearch集群通信是等价的。
-
shards
代表索引分片,ElasticSearch可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改(primary shard)。
水平扩容时,需要重新设置分片数量,重新导入数据
-
replicas
代表索引副本(replica shard),ElasticSearch可以设置多个索引副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高ElasticSearch的查询效率,ElasticSearch会自动对搜索请求进行负载均衡。
-
recovery
代表数据恢复或叫数据重新分布,ElasticSearch在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
-
river
代表ElasticSearch的一个数据源,也是其它存储方式(如:数据库)同步数据ElasticSearch的一个方法。它是以插件方式存在的一个ElasticSearch服务,通过读取river中的数据并把它索引到ElasticSearch中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的
-
gateway
代表ElasticSearch索引快照的存储方式,ElasticSearch默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个ElasticSearch集群关闭再重新启动时就会从gateway中读取索引备份数据。ElasticSearch支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
-
discovery.zen
代表ElasticSearch的自动发现节点机制,ElasticSearch是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
-
Transport
代表ElasticSearch内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
ElasticSearch的核心概念
-
Near Realtime (NRT)
从写入数据到可搜索数据有一个延迟(1秒左右,分析写入数据的过程)
-
Cluster&Node
Cluster-集群,包含多个节点,每个节点通过配置来决定属于哪一个集群(默认集群命为“elasticsearch”)
Node-节点,集群中的一个节点,节点的名字默认是随机分配的。节点名字在运维管理时很重要,节点默认会自动加入一个命名为“elasticsearch”的集群,如果直接启动多个节点,则自动组成一个名为“elasticsearch”的集群。单节点启动也是一个集群。
-
Document
ElasticSearch中的最小数据单元。一个Document就是一条数据,一般使用JSON数据结构表示。每个Index下的Type中都可以存储多个Document。一个Document中有多个field,field就是数据字段。
不要在Document中描述java对象的双向关联关系。在转换为JSON字符串的时候会出现无限递归问题。
-
Index
索引,物理分类。包含若干相似结构的Document数据。如:客户索引,订单索引,商品索引等。一个Index包含多个Document,也代表一类相似的或相同的Document。
-
Type
类型。每个索引中都可以有若干Type,Type是Index中的一个逻辑分类,同一个Type中的Document都有相同的field。
6.x版本之后,type概念被弱化,一个index中只能有唯一的一个type。在7.x版本之后,会删除type。
一个index默认10个shard,5个primary shard,5个replica shard
一个index分配到多个shard上,primary shard和他对应的replica shard不能在同一个节点中存储
二、Linux环境下安装
ElasticSearch
|
|--bin【可执行文件包】
|
|--config【配置相关目录】
|
|--lib【ES需要依赖的jar包,ES自开发的jar包】
|
|--modules【组件包】
|
|--plugins【插件目录包,三方插件或自主开发插件】
|
|--logs【日志文件相关目录】
|
|--data【在ES启动后,会自动创建的目录,内部保存ES运行过程中需要保存的数据】
安装ElasticSearch
第一步、ElasticSearch不允许root用户启动,所以需要先创建用户
useradd -U es #添加用户和用户组为es
chown -R es:es elasticsearch #修改elasticsearch所属主所属组
第二步、修改文件打开限制。至少需要65536的文件创建权限,修改限制信息/etc/security/limits.conf
es hard nofile 65536 #number open file
es soft nofile 65536
第三步、修改线程开启限制。Linux默认用户进程有开启1024个线程权限,至少需要4096的线程池预备,修改/etc/security/limits.d/20-nproc.conf
es soft nproc 4096
root soft nproc unlimited
第四步、修改系统虚拟内存权限。Linux默认不允许任何用户和应用直接开辟虚拟内存,修改/etc/sysctl.conf
vm.max_map_count=655360
第五步、修改客户端访问控制【可选】。修改config/elasticsearch.yml
network.host: 0.0.0.0
第六步、切换用户并启动ElasticSearch
su es
./bin/elasticsearch
集群启动
默认情况下一个网段的ElasticSearch会自动组成集群。只需启动时指定集群名称和自身节点名称即可
# 在不同的机器上执行即可自动组成集群
./bin/elasticsearch -E cluster.name=my_cluster -E node.name=node_1
# 在同一台机器上启动集群测试
./bin/elasticsearch -E cluster.name=my_cluster -E node.name=node_1 -Epath.data=my_cluster_data_1 -E http.port=5200
配置集群参数discovery.zen.minimum_master_nodes:【投票通过数一般为 可投票机器数/2 + 1】避免集群脑裂
安装Kibana
第一步、修改客户端访问控制。修改config/kibana.yml
#默认localhost,非本机不可访问
server.host: "0.0.0.0"
#elasticsearch.hosts: ["http://localhost:9200"] 有必要时修改
第二步、切换用户并启动elasticsearch
su es
./bin/kibana
查看集群状态可安装cerebro软件
三、Kibana简单命令
查看健康状态
命令:GET _cat/health?v
返回:
| 参数 | 含义 |
|---|---|
| shards | 分片总个数 |
| pri | primary shard个数 |
| relo | replica shard个数 |
| unssign | 未分配个数 |
| status | green【每个索引的primary shard和replica shard都是active的】 yellow【每个索引的primary shard都是active的,但部分的replica shard不是active的】 red【不是所有的索引都是primary shard都是active状态的】 |
检查分片信息
命令:GET _cat/shards?v
返回:
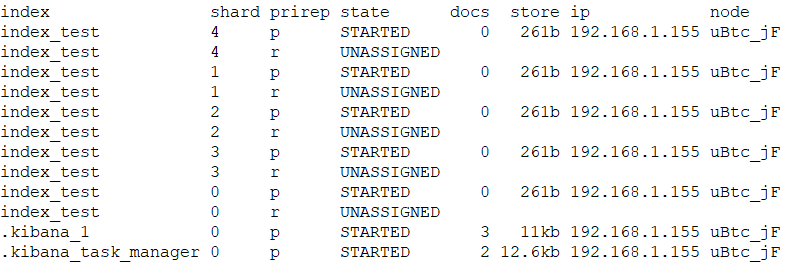
显示了每个索引的分片信息
查看索引信息
命令:GET _cat/indices?v
返回:

索引相关
-
新增索引
默认创建索引的时候,会分配5个primary shard,并为每个primary shard分配一个replica shard。
默认限制:如果磁盘空间不足15%的时候,不分配replica shard。如果磁盘空间不足5%的时候,不再分配任何的primary shard。
PUT /test_index { "settings":{ "number_of_shards" : 2, //指定primary shard个数 "number_of_replicas" : 1 //指定每个primary shard的replica shard个数 } } -
修改索引
索引一旦创建,primary shard数量不可变化,可以改变replica shard数量
PUT /test_index/_settings { "number_of_replicas" : 1 //设置replica shard个数 } -
删除索引
命令
DELETE /test_index [, other_index]
ElasticSearch尽可能保证primary shard平均分布在多个节点上。Replica shard会保证不和它自身备份的那个primary shard分配在同一个节点上
Primary Shared不可变的优缺点
优点:不需要锁,提升并发能力,避免锁问题。数据不变,可以缓存在OS cache中(前提是cache足够大)。filter cache始终在内存中,因为数据是不可变的。可以通过压缩技术来节省CPU和IO的开销。
缺点:只要index的结构发生任何变化,都必须重建索引。
文档CRUD
-
创建文档
-
PUT语法
此操作为手工指定id的Document新增方式【7以后必须使用POST新增】
PUT /test_index/my_type/1 { "name":"test_doc_01", "remark":"first test elastic search", "order_no":1 }返回内容:
{ "_index" : "test_index", #新增的document在什么index中 "_type" : "my_type", #新增的document在什么type中 "_id" : "1", #指定的id是多少 "_version" : 1, #document的版本是多少,版本从1开始递增,每次写操作都会+1 "result" : "created", #created创建,updated修改,deleted删除 "_shards" : { "total" : 2, #分片数量只提示primary shard "successful" : 1, #成功几个 "failed" : 0 #失败几个 }, "_seq_no" : 0, #执行的序列号 "_primary_term" : 1 #词条比对 } -
POST语法
此操作为ElasticSearch自动生成id的新增Document方式
POST /test_index/my_type { "name":"test_doc_04", "remark":"forth test elastic search", "order_no":4 }
-
-
查询Document
-
GET查询
语法:
GET /index_name/type_name/id例如:GET /test_index/my_type/1
-
GET /_mget查询
GET /test_index/my_type/_mget { "ids":[1,2,3,4] }
-
-
修改Document
-
替换Document(全量替换)
语法:和新增PUT语法一致【
PUT /index_name/type_name/id{field_name:new_field_value}】说明:如果有原文档此操作相当于删除原文档,并新增文档,和以前原文档没有任何关系
PUT /test_index/my_type/1 { "name":"new_test_doc_01", "remark":"first test elastic search", "order_no":1 } -
PUT语法强制新增
语法:
PUT /index_name/type_name/id/_create或PUT /index_name/type_name/id?op_type=create说明:使用强制新增语法时,如果Document的id已存在,则会报错。(version conflict, document already exists)
PUT /test_index/my_type/1/_create { "name":"new_test_doc_01", "remark":"first test elastic search", "order_no":1 } -
更新Document(部分更新)
语法:
POST /index_name/type_name/id/_update{field_name:field_value_for_update}说明:只更新某Document中的部分字段,文档必须存在。对比全量替换而言,只是操作上的方便,在底层执行上几乎没有区别
POST /test_index/my_type/1/_update { "doc":{ "name":" test_doc_01_for_update" } } -
删除Document
语法:
DELETE /index_name/type_name/idDELETE /test_index/my_type/1
-
-
bulk批量增删改
语法:
POST /_bulk { "action_type" : { "metadata_name" : "metadata_value" } } { document datas | action datas }action_type可选值为:
1)create : 强制创建,相当于PUT /index_name/type_name/id/_create
2)index: 普通的PUT操作,相当于创建Document或全量替换
3)update: 更新操作(partial update),相当于 POST /index_name/type_name/id/_update
4)delete: 删除操作
POST /_bulk { "create" : { "_index" : "test_index" , "_type" : "my_type", "_id" : "10" } } { "field_name" : "field value" } { "index" : { "_index" : "test_index", "_type" : "my_type" , "_id" : "20" } } { "field_name" : "field value 2" } { "update" : { "_index" : "test_index", "_type" : "my_type" , "_id" : 20 } } { "doc" : { "field_name" : "partial update field value" } } { "delete" : { "_index" : "test_index", "_type" : "my_type", "_id" : "2" } }注意:bulk语法中要求一个完整的json串不能有换行
-
Document routing 机制
Document的路由算法决定了Document存放在哪一个primary shard中。算法为:primary shard = hash(routing) % number_of_primary_shards,其中的routing默认为Document中的元数据_id,也可以手工指定routing的值,指定方式为:
PUT /index_name/type_name/id?routing=xxxPUT /test_index/my_type/5?routing=1001 { "detpno":1001, "name":"Tom" } 手工指定routing在海量数据中非常有用,通过手工指定的routing值,会将相关的Document存储在同shard中,方便后期进行应用级别的负载均衡并可以提高数据检索的效率。如:存电商中的商品,使用商品类型的编号作为routing,ElasticSearch会把同一个类型的商品document数据,存在同一个shard中。查询的时候,同一个类型的商品,在一个shard上查询,效率最高。
-
Document增删改原理简图
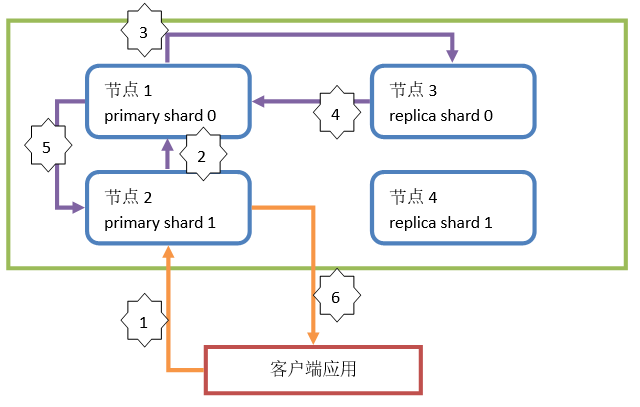
执行步骤:
1)客户端发起请求,执行增删改操作。所有的增删改操作都由primary shard直接处理,replica shard只被动的备份数据。此操作请求到节点2(请求发送到的节点随机),这个节点称为协调节点(coordinate node)
2)协调节点通过路由算法,计算出本次操作的Document所在的shard。假设本次操作的Document所在shard为 primary shard 0。协调节点计算后,会将操作请求转发到节点1
3)节点1中的primary shard 0在处理请求后,会将数据的变化同步到对应的replica shard 0中,也就是发送一个同步数据的请求到节点3中
4)replica shard 0在同步数据后,会响应通知请求这同步成功,也就是响应给primary shard 0(节点1)
5)primary shard 0(节点1)接收到replica shard 0的同步成功响应后,会响应请求者,本次操作完成。也就是响应给协调节点(节点2)
6)协调节点返回响应给客户端,通知操作结果
- Document查询简图
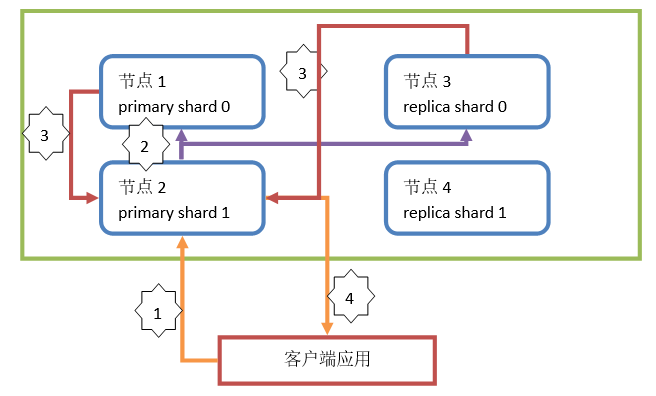
执行步骤:
1)客户端发起请求,执行查询操作。查询操作都由所有shard共同处理。假设此操作请求到节点2(随机),这个节点称为协调节点(coordinate node)
2)协调节点通过路由算法,计算出本次查询的Document所在的shard。假设本次查询的Document所在shard为 shard 0。协调节点计算后,会将操作请求转发到节点1或节点3。分配请求到节点1还是节点3通过随机算法计算
3)节点1或节点3中在处理请求后,会将查询结果返回给协调节点(节点2)
4)协调节点得到查询结果后,再将查询结果返回给客户端
四、主要元数据
-
_index
代表document存放在哪个index中,_index就是索引的名字。生成环境中,类似的Document应该存放在一个index中。index名称必须是小写,且不能以【+,-,_】开头。
-
_type
代表document属于index中的哪个type(类别)。6.x版本中,一个index只能定义一个type。
-
_id
代表document的唯一标识。使用index、type和id可以定位唯一的一个document。id可以在新增document时手工指定,也可以由ElasticSearch自动创建。
-
_source元数据
一个doc的原生的json数据,不会被索引,用于获取提取字段值 ,启动此字段,索引体积会变大。_source可以被关闭。
-
_version
代表的是document的版本。在ElasticSearch中,为document定义了版本信息,document数据每次变化,代表一次版本的变更。版本变更可以避免数据错误问题(并发问题,乐观锁),同时提供ES的搜索效率。第一次创建Document时,_version版本号为1,默认情况下,后续每次对Document执行修改或删除操作都会对_version数据自增1。
删除Document也会使_version自增。当使用PUT命令再次增加同id的Document,_version会继续之前的版本继续自增。
-
_seq_no
一个整数,严格递增的,可用于乐观锁
-
_primary_term
_primary_term也是一个整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,会自增1。
元数据_all是指将一个doc中的所有field全部用空格分割合并成一个field,只能搜索,很少用。默认开启,建议禁用。
五、Mapping
Mapping决定了一个index中的field使用什么数据格式存储,使用什么分词器解析,是否有子字段,是否需要copy to其他字段等。Mapping决定了index中的field的特征。
查询当前索引mapping信息
GET /book_index/_mapping
mapping核心数据类型
| 类型名称 | 关键字 |
|---|---|
| 字符串 | text(string) |
| 整数 | byte、short、integer、long |
| 浮点型 | float、double |
| 布尔型 | boolean |
| 日期型 | date |
| 二进制类型 | binary |
| 半精度16位浮点数 | half_float |
| 支持固定的缩放因子的浮点数 | scaled_float |
5.x之后新增范围类型:integer_range、float_range、double_range、long_range、date_range
scale_float:比如12.34,缩放因子(scaling_factor)为100,那么存储为1234。此时是一个整数,这大大有助于节省磁盘空间,因为整数比浮点更容易压缩。创建索引是要使用缩放因子scaling_factor。
_all和_source
开启和关闭
PUT /book_index
{
"mappings": { //定义mapping
"book_type": { //类型名称
"properties": { //mapping信息
}
"_all" : { "enabled" : false },
"_source" : { "enabled" : false }
}
}
}
字段的index&index_options&store&enable
enable:仅存储不做查询和聚合分析
store:是否存储此字段,默认false,store设置和_source无关
index:代表字段是否建立倒排索引
index_options:用于控制倒排索引记录的内容
- docs 只记录id
- freqs 记录id和词频(用于打分)
- positions 记录id、词频和词位置(第几个词,用于短语匹配)
- offsets 记录id、词频和词位置、词在文档中的偏移量(用于高亮显示)
text默认为positions,其它默认为docs
null值处理
“null_value”可以把null值设置一个默认值,默认处理方式是忽略
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"status_code": {
"type":"keyword",
"null_value": "NULL"
}
}
}
}
}
dynamic mapping
mapping默认创建的数据类型
| 数据 | 类型 |
|---|---|
| true or false | boolean |
| 123 | long |
| 123.12 | float |
| 2018-01-01 | date |
| hello world | text(string)【默认standard分词器,且会建立keyword字段】 |
日期的自动识别
使用date_detection开启/关闭日期的自动识别,默认开启。
使用dynamic_date_format设置日期格式,默认为yyyy/MM/dd HH:mm:ss Z|yyyy/MM/dd Z
PUT /test_index
{
"mappings": {
"doc": {
"date_detection": true,
"dynamic_date_formats": ["yyyy-MM-dd"]
}
}
}
字符中数字的自动识别
使用numeric_detection开启/关闭字符中数字的自动识别,默认关闭。
PUT /test_index
{
"mappings": {
"doc": {
"numeric_detection": true
}
}
}
设置dynamic策略
设置dynamic mapping策略时,可选值有:
- true(默认值)遇到陌生字段自动进行dynamic mapping
- false 遇到陌生字段,不进行dynamic mapping(会保存数据,但是不做倒排索引,无法实现任何的搜索)
- strict 遇到陌生字段,直接报错。
PUT /dynamic_strategy
{
"mappings": {
"dynamic_type": {
"dynamic": "strict",
"properties": {
"f1": {
"type": "text",
"analyzer": "standard"
},
"f2": {
"type": "object",
"dynamic" :false
}
}
}
}
}
=======================================插入测试=======================================
PUT /dynamic_strategy/dynamic_type/1
{
"f1": "f1 field",
"f2": {
"f21": "f21 field" //只会存储不会分词,不能索引
},
"f3": "f3 field" //f3字段无法插入,会直接报错
}
dynamic templates
设置默认的字段类型匹配规则,大大减少了索引创建需要的约束
PUT /test_index
{
"mappings": {
"doc": {
"dynamic_templates": [
{
"string_as_keyword": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
],
"properties":{
"price": {
"type":"double"
}
}
}
}
index template
设置index template可以根据各模板的优先级匹配字段
//==========================================创建模板===================================
PUT _template/template_1
{
"order": 0,
"index_patterns": [
"test*"
],
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text"
}
}
}
}
}
PUT _template/template_2
{
"order": 1,
"index_patterns": [
"test*"
],
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "keyword"
}
}
}
}
}
//========================================创建索引========================================
# 如果未明确指定字段类型将根据索引模板的匹配的order优先级决定类型
POST /test_index/_doc
{
"name": "tom"
}
//======================================查看/删除索引模板===================================
DELETE /test_index
GET _template
mapping的复杂定义
-
multi field
数组类型和普通数据类型没有区别。只是要求字段中的多个数据的类型必须相同。
PUT /multi_index/multi_type/1 { "tags": ["tagA", "tagB", "tagC"] } =================================手工对应mapping================================= PUT /multi_index { "mappings": { "multi_type": { "properties": { "tags": { "analyzer": "standard", "type": "text" } } } } } -
empty field
空数据 :
null,[],[null]空数据如果直接保存到index中,由ES为index自动创建mapping,那么此空数据对应的field将不会创建mapping映射信息。而任意的mapping定义都可以保存空数据
PUT /empty_index/empty/1 { "filed_1": null, "filed_2": [], "filed_3": [null] } ==================================mapping映射信息================================== GET /empty_index/empty/_mapping //返回结果 { "empty_index" : { "mappings" : { "empty" : { } //无field_1、field_2、field_3信息 } } } -
object field
ES在底层存储对象数据时实际上使用
对象.属性方式进行存储PUT /object_index/object_type/1 { "name" : "张三" , "age" : 20, "address" : { "province" : "北京", "city" : "北京", "street" : "永泰庄东路" } } ===============================对应的手动mapping映射=============================== PUT /object_index { "mappings": { "object_type": { "properties": { "name": { "type": "text", "analyzer": "ik_max_word" }, "age": { "type": "short" }, "address": { "properties": { "province": { "type": "text", "analyzer": "ik_max_word" }, "city": { "type": "text", "analyzer": "ik_max_word" }, "street": { "type": "text", "analyzer": "ik_max_word" } } } } } } } -
copy_to
就是将多个字段,复制到一个字段中,实现一个多字段组合
=====================================创建索引====================================== PUT /products_index { "mappings": { "doc": { "properties": { "name": { "type": "text", "analyzer": "standard", "copy_to": "search_key" }, "remark": { "type": "text", "analyzer": "standard", "copy_to": "search_key" }, "price": { "type": "integer" }, "producer": { "type": "text", "analyzer": "standard", "copy_to": "search_key" }, "tags": { "type": "text", "analyzer": "standard", "copy_to": "search_key" }, "search_key": { //此字段需要和被copy类型分词器相同 "type": "text", "analyzer": "standard" } } } } } =======================================搜索======================================= GET /products_index/doc/_search { "query": { "match": { "search_key": "IPHONE" } } }copy_to字段【上述的search_key】未必存储,但是在逻辑上是一定存在
六、Query String搜索
语法:GET [/index_name/type_name/]_search[?parameter_name=parameter_value&...]
GET /current_index/_search?q=remark:test+AND+name:doc&sort=order_no:desc
此搜索操作一般只用在快速检索数据使用,如果查询条件复杂,很难构建query string,生产环境中很少使用
全数据查询
//查询所有索引下的数据,timeout为超时时长定义,不影响响应的正常返回,只影响返回条数
GET _search?timeout=10ms
多索引搜索
所谓的multi-index就是指从多个index中搜索数据。相对使用较少,只有在复合数据搜索的时候,可能出现。
如:搜索引擎中的无条件搜索。(现在的应用中都被屏蔽了。使用的是默认搜索条件,或不执行搜索)
GET /products_es,products_index/_search //在两个索引中搜索
GET /products_*/_search //使用通配符匹配
GET /_all/_search //_all代表所有索引
-,+符号条件
GET /products_index/phone_type/_search?q=+name:plus //搜索的关键字必须包含plus
GET /products_index/phone_type/_search?q=-name:plus //搜索的关键字必须不能包含plus
+:和不定义符号含义一样,就是搜索指定的字段中包含key words的数据
- :与+符号含义相反,就是搜索指定的字段中不包含key words的数据
七、Query DSL搜索
query DSL【Domain Specified Language】,所有查询均可开启"profile": "true"查看执行的详细信息
查询所有数据
GET /current_index/_search
{
"query": {"match_all": {}}
}
全文检索
GET /es/doc/_search
{
"query": {
"match": { //单字段模式
"note": "only life" //会根据field对应的analyzer对搜索条件做分词
}
}
}
GET /es/doc/_search
{
"query": {
"match": {
"note": { //查询的字段
"query": "only life pick",
"operator": "or", //or,and
"minimum_should_match": 2 //必须匹配两个以上
}
}
},
"profile": "true"
}
GET /es/doc/_search
{
"query": {
"multi_match": { //多字段模式
"query": "only life", //会根据field对应的analyzer对搜索条件做分词
"fields": ["note","content"] //指定field
}
}
}
词元搜索
搜索条件不分词,使用搜索条件进行精确匹配。如果搜索字段被分词,搜索条件是一段话则无法匹配这种情况下适合匹配不分词字段。
GET /es/doc/_search
{
"query": {
"term": {
"note": { //虽然note被分词,但是只匹配一个词元会匹配上
"value": "people"
}
}
}
}
==================================================================================
GET /es/doc/_search
{
"query" : {
"terms" : { //进行多个词元匹配
"note" : [ "people", "necessarily" ]
}
}
}
短语搜索
GET /es/doc/_search
{
"query": {
"match_phrase": {
"note": {
"query": "importance people", //必须满足此短语,即顺序不可变
"slop": 4 //可以移动4次实现短语匹配,移动次数越少分数越高
}
}
}
}
match phrase原理:在进行短语搜索的时候其实进行了分词操作,将短语进行分词之后在倒排索引中检索数据,检查匹配到的索引在同一个文档中是否连续(利用position判断)。【使用GET _analyze可以查看分词信息】
召回率和精准度平衡
召回率:搜索结果比例
精准度:搜索结果的准确率
如果在搜索的时候,只使用match phrase语法,会导致召回率底下,因为搜索结果中必须包含短语(包括proximity search)。如果在搜索的时候,只使用match语法,会导致精准度底下,因为搜索结果排序是根据相关度分数算法计算得到。可将两者同时使用,平衡召回率和精准度。
GET /es/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"note": "importance people"
}
},
{
"match_phrase": {
"note": {
"query": "importance people",
"slop": 50
}
}
}
]
}
}
}
搜索的优化
match一般来说,比match phrase效率高10倍左右,比proximity search高20倍左右
优化的思路是:尽量减少proximity search搜索的document数量。即先用match来搜索出需要的数据,再用proximity search来提高term距离较近的document的相关度分数,从而影响结果排序,这个过程也叫rescore(重计分)。再rescore的时候,尽量使用分页,毕竟用户通常只会查看搜索数据的前几页。
GET /es/doc/_search
{
"query": {
"match": {
"note": "importance people"
}
},
"rescore": { //开始重计分
"query": {
"rescore_query": { //重新计分查询
"match_phrase": {
"note": {
"query": "importance people",
"slop": 50
}
}
}
},
"window_size": 50 //对match搜索结果的前多少条数据执行rescore操作
},
"from": 0,
"size": 2
}
范围搜索
范围查询主要争对数值和日期类型
GET /_search
{
"query" : {
"range" : {
"emps.age" : { //数字类型的范围搜索
"gt" : 21,
"lte" : 45
}
}
}
}
==================================================================================
GET /_search
{
"query": {
"range": {
"emps.join_date": { //日期类型的范围搜索
"gte": "2018-08-10||-40d"
}
}
}
}
组合搜索
bool - 用于组合多条件,相当于java中的布尔表达式。
must - 必须符合要求,相当于java中的逻辑运算符 ==或&&。
must_not - 必须不符合要求,相当于java中的逻辑运算符 !
| should - 有任意条件符合要求即可,相当于java中的逻辑运算符 {%raw%} | {%endraw%} |
GET /emp_index/emp_type/_search
{
"query": {
"bool": { //布尔条件开始
"must": [ //必须满足
{
"match": {
"dept_name": "Sales Department"
}
}
],
"must_not": [ //不需不满足
{
"range": {
"num_of_emps": {
"gt": 10
}
}
}
],
"should": [ //满足一个即可
{
"match": {
"emps.name": "wangwu"
}
},
{
"range": {
"num_of_emps": {
"lt": 20
}
}
}
]
}
}
}
scroll搜索
如果需要一次性搜索出大量数据,那么执行效率一定不会很高,这个时候可以使用scroll滚动搜索的方式实现搜索。scroll滚动搜索类似分页,是在搜索的时候,先查询一部分,之后再查询下一部分,分批查询总体数据。可以实现一个高效的响应。scroll搜索会在第一次搜索的时候保存一个快照,这个快照保存的时长由请求指定,后续的查询会依据这个快照执行再次查询。如果这个过程中,ES中的document发生了变化,是不会影响到原搜索结果的。
-
scroll搜索时,需要指定一个排序,可以使用_doc实现排序,这种排序性能更高一些。
-
scroll搜索的2次以后请求,必须在指定的快照时长内发起,且每次请求都需要指定这个快照保存时长。
-
scroll搜索的返回结果一定会包含一个特殊的结果数据_scroll_id。这个数据就是scroll搜索的快照ID。scroll搜索的2次以后的请求,必须携带上这个ID。
scroll不是分页,不是用来替换分页技术。分页为用户提供数据的,scroll为系统内部处理分批提供数据的
=====================================第一次搜索=====================================
GET /es/doc/_search?scroll=1m
{
"size": 1,
"query": {
"match_all": {}
}
}
=====================================第二次搜索=====================================
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "【上次搜索返回的scroll_id】"
}
=====================================删除快照======================================
DELETE /_search/scroll/_all
搜索策略
基于dis_max实现best fields策略进行多字段搜索
best fields策略:如果某一个field中匹配到了尽可能多的关键词,那么就应被排在前面,即执行若干查询条件以若干分数中最高分为实际的得分进行排序
GET /student/java/_search
{
"query": {
"dis_max": {
"queries": [
{
"match" : {
"name": "james gosling"
}
},
{
"match": {
"remark": "java developer"
}
}
]
}
}
}
使用tie_breaker参数优化dis_max搜索效果
dis_max是将多个搜索query条件中相关度分数最高的用于结果排序,忽略其他query分数。这时候可以使用tie_breaker参数来优化dis_max搜索。tie_breaker参数代表的含义是:将其他query搜索条件的相关度分数乘以参数值,再参与到结果排序中。如果不定义此参数,相当于参数值为0。所以其他query条件的相关度分数被忽略。
GET /student/java/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.7,
"queries": [
{
"match" : {
"name": "james gosling"
}
},
{
"match": {
"remark": "java developer"
}
}
]
}
}
}
使用multi_match简化dis_max+tie_breaker
multi_match匹配多个字段,使用best_fields策略
GET /student/java/_search
{
"query": {
"multi_match": {
"query": "james gosling java developer",
"fields": ["name", "remark^2"], //remark的boost为2
"type": "best_fields",
"tie_breaker": 0.7,
"minimum_should_match": 2,
"analyzer": "standard"
}
}
}
multi_match+most fields实现multi_field搜索
most fields策略:指搜索结果匹配了更多的字段的document分数高
GET /student/java/_search
{
"query": {
"multi_match": {
"query": "james gosling java developer",
"fields": ["name", "remark"],
"type": "most_fields",
"analyzer": "standard"
}
}
}
cross fields搜索
cross-fields搜索,一个唯一标识,跨了多个field。比如是地址可以散落在province,city,street中。
GET student/java/_search
{
"query": {
"multi_match": {
"query": "joshua developer",
"fields": ["name", "remark"],
"type": "cross_fields",
"analyzer": "standard", //注意要使用分词器
"operator" : "and" //(name必须包含joshua且remark必须包含developer)或者
} //(remark必须包含joshua且name必须包含developer)
}
}
most fields策略是尽可能匹配更多的字段,所以会导致精确搜索结果排序问题。又因为cross fields搜索,不能使用minimum_should_match来去除长尾数据。所以在使用most fields和cross fields策略搜索数据的时候,都有不同的缺陷。所以商业项目开发中,都推荐使用best fields策略实现搜索。
suggest搜索建议
实现suggest的时,其构建的不是倒排索引,也不是正排索引,是纯的用于进行前缀搜索的一种特殊的数据结构,而且会全部放在内存中,所以suggest search进行的前缀搜索提示,性能非常高。
需要使用suggest的时候,必须在定义index时,为其mapping指定开启suggest
========================================建立索引=======================================
PUT /suggest
{
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"suggest": {
"type": "completion",
"analyzer": "ik_max_word"
}
}
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
====================================应用suggest搜索====================================
GET /suggest/doc/_search
{
"suggest": {
"suggest_by_title": {
"prefix": "大话",
"completion": {
"field": "title.suggest"
}
}
}
}
近似匹配
前缀匹配搜索
针对前缀搜索,是对keyword类型字段而言。而keyword类型字段数据大小写敏感。前缀搜索效率比较低。前缀搜索不会计算相关度分数。前缀越短,效率越低。不推荐使用。
GET /es/doc/_search
{
"query": {
"prefix": {
"note.keyword": {
"value": "May"
}
}
}
}
通配符搜索
通配符可以在倒排索引中使用,也可以在keyword类型字段中使用。性能也很低,需要扫描完整的索引。不推荐使用。
GET /es/doc/_search
{
"query": {
"wildcard": {
"note": {
"value": "*oug?"
}
}
}
}
正则搜索
ES支持正则表达式。可以在倒排索引或keyword类型字段中使用。性能也很低,需要扫描完整索引。不推荐使用。
GET /es/doc/_search
{
"query": {
"regexp": {
"note": {
"value": "[A-z]noug.?"
}
}
}
}
搜索推荐
其原理和match phrase类似,是先使用match匹配term数据,然后在指定的slop移动次数范围内,前缀匹配。
GET /es/doc/_search
{
"query": {
"match_phrase_prefix": {
"note": {
"query": "happiest of peo",
"slop": 3,
"max_expansions": 3 //用于指定prefix最多匹配多少个term,超过这个数量就不再匹配了
}
}
}
}
这种语法与的match phrase的区别只有最后一个term是执行前缀搜索的,因为效率较低,如果使用一定要使用max_expansions限定
ngram分词机制
ngram是在指定长度下,对一个单词再次实现拆分的机制,如单词hello。
ngram length = 1 -- h e l l o
ngram length = 2 -- he el ll lo
ngram length = 3 -- hel ell llo
ngram length = 4 -- hell ello
ngram length = 5 -- hello
使用ngram搜索
=================================创建edge ngram索引====================================
PUT /engram
{
"settings": {
"analysis": {
"filter": {
"engram_analyzer_filter": { //定义edge_ngram过滤器
"type": "ngram",
"min_gram" : 1,
"max_gram" : 30
}
},
"analyzer": {
"engram_analyzer": { //创建分词器
"type" : "custom",
"tokenizer" : "standard",
"filter" : [
"lowercase",
"engram_analyzer_filter"
]
}
}
}
},
"mappings": {
"doc" : {
"properties": {
"note" : {
"type": "text",
"analyzer": "engram_analyzer" //使用自定义的engram_analyzer
}
}
}
}
}
edge ngram是使用首字母向后实现单词内的逐字符拆分。如单词hello。可提高前缀搜索或搜索推荐效率
h
he
hel
hell
hello
使用edge ngram搜索
=================================创建edge ngram索引====================================
PUT /engram
{
"settings": {
"analysis": {
"filter": {
"engram_analyzer_filter": { //定义edge_ngram过滤器
"type": "edge_ngram",
"min_gram" : 1,
"max_gram" : 30
}
},
"analyzer": {
"engram_analyzer": { //创建分词器
"type" : "custom",
"tokenizer" : "standard",
"filter" : [
"lowercase",
"engram_analyzer_filter"
]
}
}
}
},
"mappings": {
"doc" : {
"properties": {
"note" : {
"type": "text",
"analyzer": "engram_analyzer" //使用自定义的engram_analyzer
}
}
}
}
}
模糊搜索
fuzzy技术就是用于解决错误拼写的(在英文中很有效,在中文中几乎无效)
GET /es/doc/_search
{
"query": {
"fuzzy": {
"note": {
"value": "peple",
"fuzziness": 2 //允许错误的个数
}
}
}
}
高亮显示
plain highlighting
默认的高亮搜索模式,也是lucene底层实现的highlighting
GET /es/doc/_search
{
"query": {
"match": {
"note": "life"
}
},
"highlight": {
"pre_tags": "<color='red'>",
"post_tags": "</color>",
"fields": {
"note": {
"fragment_size": 20, //返回每段的文本长度
"number_of_fragments": 2 //最大片段数,影响返回的片段数
}
}
}
}
posting highlighting
posting highlighting需要在创建索引的时候,在mapping中手工开启
PUT /posthightling
{
"mappings": {
"doc": {
"properties": {
"remark": {
"type": "text",
"analyzer": "standard",
"index_options": "offsets"
}
}
}
}
}
这种高亮搜索模式设定后,不会对高亮搜索语法有任何的影响。只是在底层实现逻辑不同。
①性能比plain highlight要高,因为不需要重新对高亮文本进行分词。
②对磁盘的消耗更少。
如果索引常需要搜索且需要高亮显示建议使用posting highlighting
fast vector highlighting
fast vector highlighting模式和term vector有关,是借助index-time term vector来实现高亮显示。对于大field数据【大于1M】的高亮搜索性能更高。高亮搜索语法不变。
PUT /posthightling
{
"mappings": {
"properties": {
"remark": {
"type": "text",
"analyzer": "standard",
"term_vector": "with_positions_offsets"
}
}
}
}
地理位置搜索
- 定义geo point mapping
PUT /hotel_app
{
"mappings": {
"hotels": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart"
},
"pin": {
"type": "geo_point"
}
}
}
}
}
-
搜索指定区域范围内的数据
- 矩形范围搜索【遵循左上右下】
GET /hotel_app/hotels/_search { "query": { "bool": { "filter": { "geo_bounding_box": { "pin": { "top_left": { "lat": 40.73, #latitude纬度 "lon": -74.1 #longitude经度 }, "bottom_right": { "lat": 40.717, "lon": -70.99 } } } } } } }- 多边形搜索【不需要注意多边形点的顺序】
GET /hotel_app/hotels/_search { "query": { "bool": { "filter": { "geo_polygon": { "pin": { "points": [ {"lat" : 40.73, "lon" : -74.1}, {"lat" : 40.01, "lon" : -71.12}, {"lat" : 50.56, "lon" : -90.58} ] } } } } } } -
搜索某地点附近的数据
GET /hotel_app/hotels/_search
{
"query": {
"bool": {
"filter": {
"geo_distance": {
"distance": "100km",
"pin": {
"lat": 40.73,
"lon": -71.1
}
}
}
}
}
}
Span查询
跨度查询是low-level查询,可以对指定术语的顺序和接近度进行专业控制。这些通常用于对法律文件或专利实施非常具体的查询。跨度查询不能与非跨度查询混合(span_multi查询除外)。跨度查询是非常专业的查询方式,在一般的商业应用中并不多见。
span-term【只能作用在分词字段】
如果单独使用,效果跟term查询差不多,但是一般还是用于其他的span查询的子查询。
GET cars/_search
{
"query": {
"span_term": {
"remark": {
"value": "大众"
}
}
}
}
span-multi
可以嵌套的跨度查询,可以将其他的query搜索方案包装为一个span query跨度查询。如:通配符、前缀搜索、正则搜索、模糊搜索(fuzzy)等。
========================================前缀搜索=======================================
GET cars/_search
{
"query": {
"span_multi": {
"match": {
"prefix": {
"remark": {
"value": "大众"
}
}
}
}
}
}
========================================正则搜索=======================================
GET cars/_search
{
"query": {
"span_multi": {
"match": {
"regexp": {
"remark": {
"value": "神*"
}
}
}
}
}
}
=======================================通配符搜索======================================
GET cars/_search
{
"query": {
"span_multi": {
"match": {
"wildcard": {
"remark": {
"value": "大?"
}
}
}
}
}
}
========================================模糊搜索=======================================
GET cars/_search
{
"query": {
"span_multi": {
"match": {
"fuzzy": {
"remark": {
"value": "高档车",
"fuzziness": 1
}
}
}
}
}
}
span_first
跨度查询中匹配字段开头数据,其中的match对应任意一个span query类型。end代表在这个span query匹配过程中,搜索条件数据在字段中最大的匹配范围。即(position<end)
GET cars/_search
{
"query": {
"span_first": {
"match": {
"span_term": {
"remark": "中档车"
}
},
"end": 3
}
}
}
span_near
跨度搜索中的近似匹配,类似match_phrase+slop组成的近似匹配。
GET cars/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_term": {
"remark": {
"value": "大众"
}
}
},
{
"span_term": {
"remark": {
"value": "中档"
}
}
}
],
"slop": 2, //最大的跨度
"in_order": false //顺序是否绝对
}
}
}
span_or
类似should逻辑。搜索span_or中的多个搜索条件的结果并集。
GET cars/_search
{
"query": {
"span_or": {
"clauses": [
{
"span_term": {
"remark": {
"value": "专用"
}
}
},
{
"span_term": {
"remark": {
"value": "小资"
}
}
}
]
}
}
}
span_not
搜索条件的差集,不是搜索结果的差集。【大众中档车依旧会出现】
GET cars/_search
{
"query": {
"span_not": {
"include": {
"span_term": {
"remark": {
"value": "大众"
}
}
},
"exclude": {
"span_term": {
"remark": {
"value": "中档车"
}
}
}
}
}
}
span_containing
这个查询内部会有多个子查询,但是会设定某个子查询优先级更高,作用更大,通过关键字little和big来指定。Big条件是一个更加精确的条件,little条件是一个相对宽泛条件。Big条件必须包含little条件。
GET cars/_search
{
"query": {
"span_containing": {
"little": {
"span_term": {
"remark": {
"value": "大众"
}
}
},
"big": {
"span_near": {
"clauses": [
{GET /_mget查询
"span_term": {
"remark": {
"value": "肝疼"
}
}
},
{
"span_term": {
"remark": {
"value": "大众"
}
}
}
],
"slop": 12,
"in_order": false
}
}
}
}
}
span_within
这个查询与span_containing查询作用差不多,不过span_containing是基于lucene中的SpanContainingQuery,而span_within则是基于SpanWithinQuery。
搜索模板
一次性调用的template
此方式没太大意义,只能调用一次的template是没有意义的
===================================方式一【简单参数】===================================
GET /cars/sales/_search/template
{
"source": {
"query": {
"match": {
"remark": "{{kw}}" //使用双大括号表示变量
}
},
"from": "{{from}}{{\^from}}100{{/from}}", //默认值设置
"size": "{{size}}"
},
"params": { //传入变量
"kw": "大众",
"size": 2
}
}
===================================方式二【json方式】===================================
GET /cars/sales/_search/template
{
"source": "{ \"query\": { \"match\": {{#toJson}}parameter{{/toJson}} }}", //字符串
"params": {
"parameter" : {
"remark" : "大众"
}
}
}
===================================方式三【join方式】===================================
GET /cars/sales/_search/template
{
"source" : {
"query" : {
"match" : {
"remark" : "{{#join delimiter=' '}}kw{{/join delimiter=' '}}"
}
}
},
"params": {
"kw" : ["大众", "标致"]
}
}
可重复调用的template
=====================================创建template=====================================
POST _scripts/test
{
"script": {
"lang": "mustache",
"source": {
"query": {
"match" : {
"remark" : "{{kw}}"
}
}
}
}
}
=====================================调用template=====================================
GET /cars/sales/_search/template
{
"id": "test",
"params": {
"kw": "大众"
}
}
查询已定义的template
GET _scripts/test
删除template
DELETE _scripts/test
排序&分页&指定返回字段&仅获取数量
当字段类型为text时,使用字符串类型的字段作为排序依据会有问题【ES对字段数据做分词,建立倒排索引。分词后,先使用哪一个单词做排序是不固定的】,此时需要在此字段上建立keyword类型的子字段,或者建立fielddata。
GET /kibana_sample_data_ecommerce/_search
{
// 返回_source元数据的字段,如果_source被禁用则需在建立索引时指定是否store【默认false】,然后使用stored_fields获取
"_source": ["customer_id","customer_first_name","customer_full_name"],
"sort": [
{
"total_quantity": "desc"
},
{
"_score":"desc" // 如果没用有分数排序,ES将不会进行打分操作
},
{
"_doc":"asc" // 使用lucene索引时的先后顺序,分布式下可能重复
},
{
"_id":"desc" // 使用id的顺序排序
}
],
"from": 100,
"size": 20
}
GET /es/doc/_count
{
"query": {
"match": {
"note": {
"query": "only"
}
}
}
}
八、查询过滤
过滤语法
过滤的时候,不进行任何的匹配分数计算,且filter内置cache自动缓存常用的filter数据,有效提升过滤速度,相对于query来说,filter相对效率较高。Query要计算搜索匹配相关度分数。Query更加适合复杂的条件搜索。Query和Filter并行执行。
GET /es/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "test_doc_2"
}
}
],
"filter": { //过滤,在已有的搜索结果中进行过滤。满足条件的返回。
"range": {
"qt": {
"gt": 16
}
}
}
}
}
}
如果单纯的过滤数据,不需要增加额外的搜索匹配,也可以使用下述语句:
GET /es/doc/_search
{
"query": {
"constant_score": { //不进行分数判定
"filter": {
"match": {
"note": "people"
}
}
}
}
}
filter 底层执行原理
-
构建bitset
bitset是一个二进制的数组,数组下标对应的是当前index中document的搜索顺序。在bitset中,0代表不符合搜索条件,1代表符合搜索条件。ES使用bitset来标记document是否符合搜索条件,也是为了用最简单的数据结构来描述搜索结果,来节省内存的开销。
-
遍历bitset
因为一个搜索中可以有多个filter条件,搜索在ES执行后,filter对应的bitset可能有多个,ES会遍历每个filter对应的bitset,且从最稀疏的开始遍历【1最少的】,以达到效率最佳。当所有的bitset遍历结束后,所有的filter条件过滤完成。得到过滤结果。
-
caching bitset
ES会缓存bitset数据到内存中,如果后续的搜索语法中,有相同的filter条件,那么从缓存中直接使用对应的bitset来过滤数据,效率最优。其缓存机制是:最近的256个filter中,如果某个filter执行次数达到一定的数量和一定条件,则缓存bitset。【如果数据少于1000则不缓存,如果索引分段数据不足索引整体数据的3%也不缓存】
-
执行特性
-
query和filter的执行顺序
一般情况,ES会先执行filter,再执行query,因为filter效率高,能够过滤掉不符合搜索条件的数据。
-
bitset cache 自动更新
如果document的数据修改,或新增、删除了document,那么缓存的bitset会自动更新,保证缓存bitset的数据有效性。
-
bitset cache的应用时机
只要在执行query的时候包含filter过滤条件,会先检查cache中是否有这个filter的bitset cache,如果有,则直接使用,如果没有,则搜索过滤index中的document。
-
九、搜索相关
分页搜索与Deep Paging问题
GET /_search?from=0&size=10 // from从第几条开始查询,size返回的条数
执行搜索时请求发送到协调节点中,协调节点将搜索请求发送给所有的节点,而数据可能分部在多个节点中,所以会造成以下现象:集群有4个节点,每个节点有1个分片(primary shard),发起上述请求时,每个节点会返回150条数据,协调节点一共接收到600条数据,进行排序并取其中第100~150条数据,如果页数过深会造成效率低下问题。
match底层转换
ElasticSearch执行match搜索时,通常都会对搜索条件进行底层转换,来实现最终的搜索结果。
=====================================================================================
GET /student/java/_search
{
"query": {
"match": {
"remark": "java developer"
}
}
}
//转换后为:
GET /student/java/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"remark": {
"value": "java"
}
}
},
{
"term": {
"remark": {
"value": "developer"
}
}
}
]
}
}
}
====================================================================================
GET /student/java/_search
{
"query": {
"match": {
"remark": {
"query": "java developer",
"operator": "and"
}
}
}
}
//转换后为:
GET /student/java/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"remark": {
"value": "java"
}
}
},
{
"term": {
"remark": {
"value": "developer"
}
}
}
]
}
}
}
====================================================================================
GET /student/java/_search
{
"query": {
"match": {
"remark": {
"query": "java developer architect",
"minimum_should_match": "67%"
}
}
}
}
//转换后为:
GET /student/java/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"remark": {
"value": "java"
}
}
},
{
"term": {
"remark": {
"value": "developer"
}
}
},
{
"term": {
"remark": {
"value": "architect"
}
}
}
],
"minimum_should_match": 2
}
}
}
建议,如果不怕麻烦,尽量使用转换后的语法执行搜索,效率更高。
十、聚合搜索
前序:分析,分组,聚合,字符串排序等操作需要设置正排索引【子字段keyword】或者字段的fielddata为true(建立正排索引)
正排索引:类似数据库中的普通索引。依赖倒排索引中的数据,不做二次解析,将倒排索引内容重设一份正排索引,用于内存计算
PUT /products_index/phone_type/_mapping
{
"properties": {
"tags":{ //设置的字段
"type": "text",
"fielddata": true //fielddata开启
}
}
}
Bucket[分桶类型]
terms
在ElasticSearch中默认为分组数据做排序使用的是_count[统计个数]执行降序排列。也可以使用_key[统计列的内容]元数据
GET /cars/sales/_search
{
"size": 0, //返回查询命中记录,如果为0则不返回
"aggs": {
"group_by_color": { //聚合返回结果集的标签名
"terms": { //词元统计
"field": "color", //统计color每个词元总数
"order": {
"_count": "asc"
}
}
}
}
}
range
通过指定数值的范围来设定分桶规则
======================================range划分=======================================
GET /products_index/phone_type/_search
{
"query": {
"match_all": {}
},
"_source": "price",
"aggs": {
"rang_price": {
"range": { //范围分组
"field": "price", //分组字段
"ranges": [ //分组区间
{
"from": 500000,
"to": 700000
},
{
"from": 700000,
"to": 900000
}
]
}
}
}
}
data_range
通过指定日期的范围来设定分桶规则
GET /cars/sales/_search
{
"query": {
"match_all": {}
},
"_source": "sold_date",
"aggs": {
"rang_price": {
"date_range": {
"field": "sold_date",
"ranges": [
{
"from": "2015-01-01",
"to": "2017-01-01"
},
{
"from": "2017-01-01",
"to": "2019-01-01"
}
]
}
}
}
}
histogram
以固定间隔的策略来分割数据
====================================histogram划分=====================================
GET /cars/_search
{
"size": 0,
"aggs": {
"histogarm_by_price": {
"histogram": {
"field": "price",
"interval": 10000, //以1w区间划分
"min_doc_count" : 0, //区间最小数量,0代表即使此区间无数据也返回
"extended_bounds": {
"min": 100000, //仅min_doc_count为0时有效,为其实统计位置
"max": 2000000 //当max指定的值超过实际最大值时有效,否则按照实际最大值统计
}
}
}
}
}
data_histogram
针对日期,以固定间隔的策略来分割数据
==================================date_histogram划分==================================
GET /cars/_search
{
"size": 0,
"aggs": {
"histogarm_by_date": {
"date_histogram": { //时间区间划分
"field": "sold_date",
"interval": "month", //划分规则
"min_doc_count": 1,
"format": "yyyy-MM-dd", //最大、最小时间格式
"extended_bounds": { //时间起始值和终止值
"min": "2017-01-01",
"max": "2018-12-31"
}
}
}
}
}
geo_distance
根据距离来分割数据
===================================地理范围聚合划分=====================================
GET /hotel_app/hotels/_search
{
"size": 0,
"aggs": {
"agg_by_pin": {
"geo_distance": {
"field": "pin",
"distance_type": "arc", #sloppy_arc默认算法、arc最高精度、plane最高效率
"origin": { #原点
"lat": 52.376,
"lon": 4.894
},
"unit": "km", #距离单位
"ranges": [ #距离原点距离
{
"to": 100
},
{
"from": 100,
"to": 300
},
{
"from": 300,
"to": 3000
}
]
}
}
}
}
Metric[指标分析类型]
指标分析类型分为单值分析和多值分析两类
- 单值
- min,max,avg,sum
- cardinality
- 多值
- stats,extended stats
- percentile,percentile rank
- top hits
min,max,avg,sum
GET /cars/sales/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": { //最大值
"field": "price"
}
},
"min_price": {
"min": { //最小值
"field": "price"
}
},
"sum_price": { //总计
"sum": {
"field": "price"
}
},
"avg_price": { //聚合返回结果集的标签名
"avg": { //计算平均值
"field": "price" //计算的字段
}
}
}
}
cardinality
使用cardinality语法去除重复数据后,统计数据量。这种语法的计算类似SQL中的distinct count计算。
GET /cars/sales/_search
{
"size": 0,
"aggs": {
"count_of_province": {
"cardinality": {
"field": "brand",
"precision_threshold": 100
}
}
}
}
cardinality使用的是Hyperloglog++算法,具有一定的错误率,可使用precision_threshold设置预估唯一值数量提高准确度(默认100)。
优化cardinality
HLL算法的实现是:对所有cardinality指定字段取hash值,通过hash和bitset数据结构计算cardinality结果。可使用mapper-murmur3 plugin插件,在index_time时就计算hash值提高效率。【mapper-murmur3 plugin安装见官网】
PUT /cars
{
"mappings": {
"sales": {
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword",
"fields": {
"hash": { //在创建索引时计算hash值,进行cardinality操作使用此字段
"type": "murmur3"
}
}
},
"model": {
"type": "keyword"
},
"sold_date": {
"type": "date"
},
"remark": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
单个文档节省的时间是非常少的,但是如果聚合一亿数据,每个字段多花费10纳秒的时间,那么在每次查询时都会额外增加1秒,如果我们要在非常大量的数据里面使用 cardinality ,我们可以权衡使用。
stats,extended stats
stats会返回count、min、max、avg、sum统计信息
extended stats会返回比stats多sum_of_squares[平方和]、variance[方差]、std_deviation[标准差]、std_deviation_bounds[标准差的上下值]
GET /cars/sales/_search
{
"size": 0,
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
},
"price_extended_stats": {
"extended_stats": {
"field": "price"
}
}
}
}
percentiles,percentile_rank
percentiles:将数字字段从小到大排序,取百分比位置数据的值。用于计算百分比数据的。如:PT50、PT90、PT99等
percentile_rank:给定一个值,查看它的排名
GET /cars/sales/_search
{
"aggs": {
"price_percentiles": {
"percentiles": {
"field": "price",
"percents": [
50, //取50%位置数据值
90, //取90%位置数据值
99 //取99%位置数据值
]
}
},
"price_percentiles_rank": {
"percentile_ranks": {
"field": "price",
"values": [
1899000 //查询1899000能站多少名
]
}
}
}
}
优化percentiles和percentile_ranks
percentiles和percentile_ranks底层采用的都是TDigest算法,是用很多的节点来执行百分比计算,计算过程也是一种近似估计,有一定的错误率。节点越多,结果越精确(内存消耗越大)。
参数compression用于限制节点的最大数目,限制为:20 * compression。这个参数的默认值为100。即默认提供2000个节点。一个节点大约使用 32 字节的内存,所以在最坏的情况下(例如,大量数据有序存入),默认设置会生成一个大小约为 64KB 的 TDigest算法空间。 在实际应用中,数据会更随机,所以 TDigest 使用的内存会更少。
GET /cars/sales/_search
{
"aggs": {
"price_percentiles": {
"percentiles": {
"field": "price",
"percents": [
50,
90,
99
],
"tdigest": {
"compression": 200
}
}
}
}
}
top_hits
对组内的数据进行排序,并选择其中排名高的数据,那么可以使用top_hits来实现。
-
top_hits中的属性size代表取组内多少条数据(默认为10)
-
sort代表组内使用什么字段什么规则排序(默认使用
_doc的asc规则排序) -
source代表结果中包含document中的那些字段(默认包含全部字段)
GET /cars/_search
{
"size": 0,
"aggs": {
"group_by_brank": { //先根据brank分组
"terms": {
"field": "brand"
},
"aggs": {
"price_rank_two": { //计算各分组类价钱最高的2个
"top_hits": {
"size": 2,
"sort": [{"price": "desc"}], //排序字段
"_source": { //返回doc的信息
"includes": ["model", "price"]
}
}
}
}
}
}
}
Pipeline[管道分析类型]
管道分析,根据输出位置的不同可以分为
- parent:结果内嵌到现有聚合结果集中
- derivative【求导】
- moving average【移动平均】
- cumulative sum【累计求和】
GET /cars/sales/_search
{
"size": 0,
"aggs": {
"sold_date_agg": {
"date_histogram": {
"field": "sold_date",
"interval": "month",
"min_doc_count": 1
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"derivative_price": { //按月分割,求每月平均值的导数
"derivative": {
"buckets_path": "avg_price"
}
},
"moving_average_price": { //按月分割,求每月移动平均值的导数
"moving_avg": {
"buckets_path": "avg_price"
}
},
"cumulative_sum_price": { //按月分割,求每月平均值的累计求和
"cumulative_sum": {
"buckets_path": "avg_price"
}
}
}
}
}
}
- sibling:结果与现有聚合分析同级
- max_bucket,min_bucket,avg_bucket,sum_bucket
- stats_bucket,extended_stats_bucket
- percentiles_bucket
GET /cars/sales/_search
{
"size": 0,
"aggs": {
"brand_terms": {
"terms": {
"field": "brand"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"min_price_car": { //得到每个品牌价钱平均值的最小值
"min_bucket": {
"buckets_path": "brand_terms>avg_price"
}
},
"max_price_car": { //得到每个品牌价钱平均值的最大值
"max_bucket": {
"buckets_path": "brand_terms>avg_price"
}
},
"sum_price_car": { //得到每个品牌价钱平均值的总合
"sum_bucket": {
"buckets_path": "brand_terms>avg_price"
}
},
"avg_price_car": { //得到每个品牌价钱平均值的总合的平均值
"avg_bucket": {
"buckets_path": "brand_terms>avg_price"
}
},
"stats_price_car" : { //得到每个品牌价钱平均值的state信息
"stats_bucket": {
"buckets_path": "brand_terms>avg_price"
}
},
"extended_stats_price_car" : {//得到每个品牌价钱平均值的extended_stats_bucket信息
"extended_stats_bucket": {
"buckets_path": "brand_terms>avg_price"
}
},
"percentiles_price_car" : { //得到每个品牌价钱平均值的percentiles信息
"percentiles_bucket": {
"buckets_path": "brand_terms>avg_price",
"percents": [
10,
50,
90
]
}
}
}
}
聚合嵌套
聚合是可以嵌套的,内层聚合是依托于外层聚合的结果之上实现聚合计算。
GET /products_index/phone_type/_search
{
"query": {
"match": {
"name": "plus"
}
},
"aggs": {
"count_term_tags": { //聚合进行词元统计
"terms": {
"field": "tags"
},
"aggs": { //在词元统计的结果之下进行求平均值
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
聚合平铺
聚合类嵌套的聚合条件是平级关系
GET /cars/sales/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"avg_by_price_color": { //和group_by_brand平级
"avg": {
"field": "price"
}
},
"group_by_brand": { //和avg_by_price_color平级
"terms": {
"field": "brand"
}
}
}
}
}
}
聚合排序
聚合中如果使用order排序的话,要求排序字段必须是一个聚合相关字段,可使用_count,_key这些元数据进行排序
//使用子聚合avg_price排序
//如果引用子聚合分析的子聚合分析需要使用>连接
//如果子聚合是用stats等多值指标分析,需用.属性的方式
GET /products_index/phone_type/_search
{
"size": 0,
"aggs": {
"count_term_tags": {
"terms": {
"field": "tags",
"order": {
"avg_price": "asc"
}
},
"aggs": {
"avg_price": { //子聚合avg_price
"avg": {
"field": "price"
}
}
}
}
}
}
改变聚合的作用范围
聚合内过滤
这个过滤器只对query搜索得到的结果执行filter过滤,即聚合的实际数据比查询数据少。
GET /cars/_search
{
"size": 0,
"aggs": {
"group_by_brand_not_w": {
"filter": { //过滤Query之后的条件
"terms": {
"brand": ["大众","奥迪"]
}
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
}
}
}
}
}
}
Global Bucket
在聚合统计数据的时候,有些时候需要对比部分数据和总体数据。global是用于定义一个全局bucket,这个bucket会忽略query的条件,检索所有document进行对应的聚合统计。
GET /cars/_search
{
"size": 0,
"query": {
"term": {
"brand": "大众"
}
},
"aggs": {
"w_avg_by_price": {
"avg": {
"field": "price"
}
},
"aggs": {
"global": {}, //不会使用query搜索条件进行统计
"aggs": {
"all_avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
post_filter
只过滤搜索结果,而不过滤聚合的过滤器。即聚合结果不会发生变化,而搜索显示的数据会发生变化。
// 聚合显示所有品牌,搜索结果只有大众
GET /cars/sales/_search
{
"post_filter": {
"term": {
"brand": "大众"
}
},
"size": 10,
"aggs": {
"brand_terms": {
"terms": {
"field": "brand",
"size": 10
}
}
}
}
深度聚合和广度聚合
默认ElasticSearch执行聚合分析时,是按照top_hits深度优先的方式去执行的。会计算出每一项结果。但是遇到计算销量前五的品牌中前十的车型这种问题时,使用深度优先计算不太合适,应该逐层聚合bucket,并过滤后,在当前层的结果基础上再次执行下一层的聚合(广度优先)。
GET /cars/_search
{
"size": 0,
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand",
"size": 5,
"collect_mode": "breadth_first"
},
"aggs": {
"group_of_model": {
"terms": {
"field": "model"
}
}
}
}
}
}
聚合算法精准度
大数据聚合时精准度概论
-
易并行聚合算法
若干节点同时计算一个聚合结果,再返回给协调节点做最终计算,得到最终结果的方式。如聚合计算中的max,min等
-
近似聚合算法
有些聚合分析算法是很难使用易并行算法解决的,如:Terms。这个时候ES会采取近似聚合的方式来进行计算。近似聚合结果不完全准确,但是效率非常高,一般效率是精准算法的数十倍。
近似聚合: 延时一般在100毫秒左右,有5%左右的错误率。
精准算法: 延时一般在若干秒到若干小时之间,不会有任何错误。(批处理)
-
三角选择原则
精准度 + 实时性 :一定是数据量很小的时候,通常都在单机中执行,可以随时调用。
精准度 + 大数据 : 这是非实时的计算,是在大数据存在的情况下,保证数据计算的精准度,一次计算可能需要若干小时才能完成,通常都是批处理程序。如:hadoop
大数据 + 实时性 : 这是一种不精准的计算,近似估计,一般都会有一定错误率(一般5%以内)。如ES中的近似聚合算法。
ES非精准聚合控制
- 设置
shard数量为1,消除问题,但此时无法承载大量数据 - 聚合时合理设置
shard_size大小,即每次从shard上获取额外数据,以提升精准度。默认为size* 1.5 + 10
GET /cars/sales/_search
{
"size": 0,
"aggs": {
"brand_terms": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"_count": "desc"
},
"shard_size": 50, //每个分片返回50个数据
"show_term_doc_count_error": true //显示统计出错的最大值,如果为0则是精确计算
}
}
}
}
十一、同义词与分词器
概念
同义词:
-
为key_words提供更加完整的倒排索引。如:时态转化,单复数转化,全写简写,同义词等。
-
normalization是为了提升召回率(recall),提升搜索能力的。
-
normalization是配合分词器(analyzer)完成其功能
分词器:
- 分词器的功能是处理Document中的field即创建倒排索引过程中用于切分field数据
默认提供的常见分词器
-
standard analyzer:是ES中的默认分词器。标准分词器,处理英语语法的分词器。这种分词器也是ES中默认的分词器。切分过程中会忽略停止词等。会进行单词的大小写转换。过滤连接符或括号等常见符号。 -
simple analyzer:简单分词器。就是将数据切分成一个个的单词。使用较少,经常会破坏英语语法。 -
whitespace analyzer:空白符分词器。就是根据空白符号切分数据。使用较少,经常会破坏英语语法。 -
language analyzer:对应语言的分词器,会忽略停止词、转换大小写、单复数转换、时态转换等。
搜索条件中的key_words也需要经过分词,且搜索条件中的条件数据使用的分词器与对应的字段使用的分词器是统一的。否则会导致搜索结果丢失。
IK分词器
安装步骤
第一步:下载源码包编译打包或者下载编译完成的代码包
第二步:在elasticsearch的plugins目录下创建ik目录
第三步:将编译完成的压缩包解压到plugins的ik目录下
IK分词器种类
ik_max_word:会将文本做最细粒度的拆分,会穷尽各种可能的组合,适合 Term Query
ik_smart:会做最粗粒度的拆分,适合 Phrase 查询
IK分词器配置文件
IK的所有的dic词库文件,必须使用UTF-8字符集
config
|
+- extra_main.dic【自定义词库,配置方式为相对于IKAnalyzer.cfg.xml相对路径,非热更新】
|
+- extra_single_word.dic【自定义单字词,配置相对于IKAnalyzer.cfg.xml相对路径,非热更新】
|
+- extra_single_word_full.dic【和extra_single_word.dic内容相同】
|
+- extra_single_word_low_freq.dic【自定义单字低频词,非热更新】
|
+- extra_stopword.dic【自定义停用词库,配置方式为相对于IKAnalyzer.cfg.xml相对路径,非热更新】
|
+- IKAnalyzer.cfg.xml【配置加载外部扩展词文件】
|
+- main.dic【内置词典,一行一词,未记录的单词无法实现分词,不建议修改】
|
+- preposition.dic【内置的中文停用词】
|
+- quantifier.dic【内置数据单位词典】
|
+- stopword.dic【内置英文停用词】
|
+- suffix.dic【内置后缀】
|
+- surname.dic【内置姓氏词典】
IK词库热更新
修改IKAnalyzer.cfg.xml文件
<!--这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">location</entry>
location 指url,比如 http://yoursite.com/getCustomDict,该请求需满足以下条件
-
该 http 请求需要返回两个头部(header),一个是
Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。 -
该 http 请求返回的内容格式是一行一个分词,换行符用
\n
测试IK分词器
GET /_analyze
{
"analyzer": "ik_max_word",
"text": ["中国人民共和国国歌"]
}
GET /_analyze
{
"analyzer": "ik_smart",
"text": ["中国人民共和国国歌"]
}
十二、ES分布式架构分析
分布式机制的透明隐藏特性
ElasticSearch本身就是一个分布式系统,就是为了处理海量数据的应用。隐藏了复杂的分布式机制,简化了配置和操作的复杂度。ElasticSearch在现在的互联网环境中,盛行的原因,主要的核心就是分布式的简化。
ElasticSearch隐藏的分布式内容:分片机制、集群发现、负载均衡、路由请求、集群扩容、shard重分配等。
节点变化时的数据重平衡
在节点发生变化时,ES的cluster会自动调整每个节点中的数据,也就是shard的重新分配。这个过程叫做rebalance。rebalance目的是为了提高性能,理论上,当数据量达到一定级别的时候,每个shard分片上的数据量是均等的。那么每个节点管理的shard数量是均等的情况,ES集群才能提供最好的服务性能。
master节点作用
维护集群元数据的节点。如:索引的变更(创建和删除)对应的元数据保存在master节点中。
master不是请求的唯一接收节点。只是维护元数据的特殊节点。不会导致单点瓶颈。
集群在默认配置中,会自动的选举出master节点。元数据是一个收集管理的过程。不是一个必要的不可替代的数据。master如果宕机,集群会选举出新的master,新的master会在集群的所有节点中重新收集集群元数据并管理。
节点平等的分布式架构
-
节点平等
每个节点都能接收客户端请求。不会造成单点压力。
-
自动请求路由
节点在接收到客户端请求时,会自动的识别应该由哪个节点处理本次请求,并实现请求的转发。
-
响应收集
在自动请求路由后,接收客户端请求的节点会自动的收集其他节点的处理结果,并统一响应给客户端。
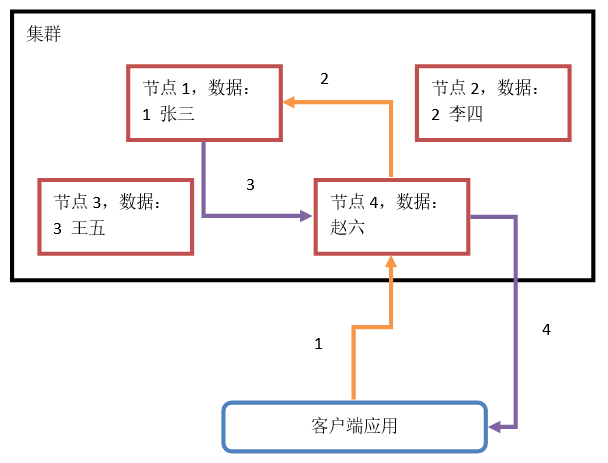
1)客户端请求ElasticSearch集群,搜索“张三”数据。请求发送到节点4。此操作代表节点的平等性。集群中每个节点的功能都是一致的。
2)节点4将请求路由到节点1上。实现数据的搜索。这是自动请求路径的过程。
3)节点1处理结束后,搜索结果会发送给节点4。这是响应收集的过程。
4)节点4将最终结果响应给客户端,这种操作就屏蔽了集群对客户端的影响。
并发冲突
-
使用内置_version【7.x版本以后废弃】
全量替换(乐观锁):ElasticSearch会检查请求中的version和存储中的version是否相等。如果不相等报错,如果相等则修改。
PUT /test_index/my_type/1?version=4 { "name":"doc_new_01" } -
使用external version
ElasticSearch提供了一个特性,可以自定义version实现ES内置的_version元数据版本管理功能。与元数据_version的区别是:元数据比对必须完全一致,且external version必须比元数据_version数据大。成功后_version修改为提供的external version数值。
PUT /test_index/my_type/1?version=9&version_type=external { "name":"doc_new_new_01" } -
使用partial update乐观锁
在ElasticSearch中,使用partial update更新数据时,内部自动使用乐观锁控制数据的并发安全。如果出现版本不一致的时候,ElasticSearch会提示更新失败。可以通过命令中的参数实现手工管理乐观锁。【retry_on_conflict和version参数不能同时使用】
POST /test_index/my_type/1/_update?retry_on_conflict=3 #retry_on_conflict尝试次数 { "name":"doc_new_post_01" } -
使用
if_seq_no和if_primary_term替代内置_versionPUT /test_index/my_type/1?if_seq_no=6&if_primary_term=3 { "name":"doc_new_01" }
十三、Document写入原理
ElasticSearch为了实现搜索的近实时,结合了内存buffer、OS cache、disk三种存储,尽可能的提升搜索能力。ElasticSearch的底层使用lucene实现。在lucene中一个index是分为若干个segment(分段)的,每个segment都会存放index中的部分数据。在ElasticSearch中,是将一个index先分解成若干shard,在shard中,使用若干segment来存储具体的数据。
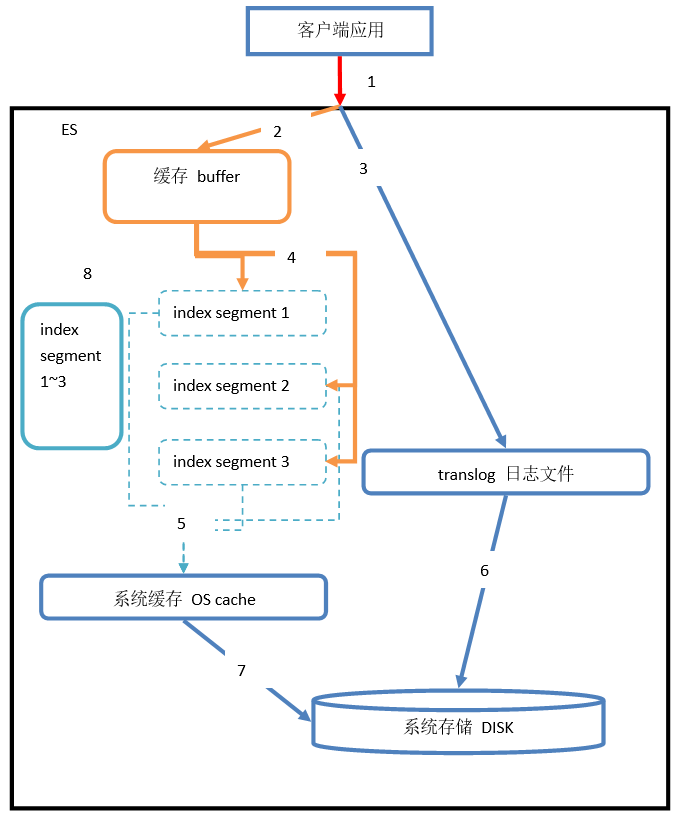
Document写入过程
1)客户端发起增删改请求,请求发送到协调节点(任意节点都能成为协调节点)
2)通过hash(routing)%number_of_primary_shards将请求转发到对应的主分片,主分片也会将请求转发到副本分片上【routing默认为id,也可指定routing】
3)副本分片接收请求到并创建成功之后返回给主分片,主分片再结合自身情况发送创建成功或失败到协调节点,协调节点将结果返回给客户端
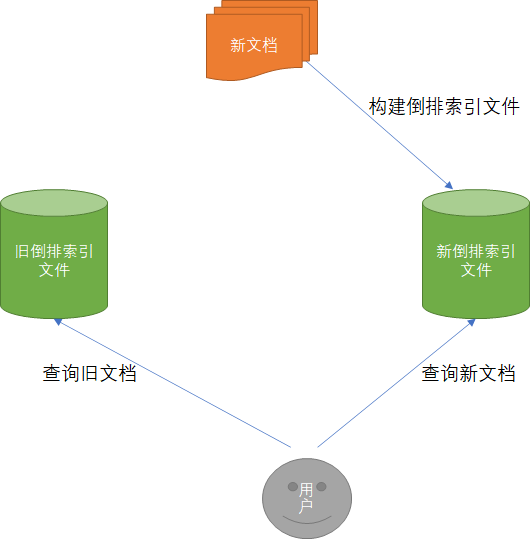
Document读取的实时性
倒排索引一旦生成是不可以更改的,有如下好处:
- 不用考虑并发写文件问题,避免了加锁的开销
- 由于文件不能更改,可以充分利用文件系统缓存,只需要载入一次,内容直接从内容中读取
- 利于生成缓存数据,不用担心数据变化带来的缓存失效问题
ElasticSearch区分新旧文档,查询时汇总新旧文档内容返回查询结果
Document写入细节

refresh
segment写入磁盘的过程依旧很耗时,可以借助文件系统缓存的特性,先将segment在缓存中创建并开放查询来提升实时性,改过程在称之为refresh。在refresh之前文档先存储在内存Buffer中,此时还不能搜索,refresh时将buffer中所有文档都清空并生成segment。es默认每秒执行一次refresh,所以一秒之后文档即可查询。
translog
es将文档写入buffer时会同时将文档写入到translog文件中,默认每个文档都会在translog文件中即时落盘(fsync),避免丢失数据。es启动时会检查translog文件将文档载入buffer。
flush

flush负责将内存中的segment写入磁盘,主要做以下工作
- 将
translog写入磁盘 - 将
index buffer清空,其中的文档生成一个新的segment相当于一个refresh操作 - 更新
commit point并写入磁盘 - 执行
fsync操作,将内存中的segment写入磁盘 - 删除旧的
translog文件
删除与更新文档
lucene专门维护一个.del的文件,记录所有已删除的文档【.del上记录的是lucene内部的id】,查询结果返回前会过滤掉.del中的所有文档。更新文档是首先删除文档,然后再创建新文档。
segment merging
随着segment的增多,由于一次查询的segment数量增多,查询速度会变慢。所以es会定时在后台执行segment merge操作,以减少segment的数量。通过froce_merge也可手动强制执行segment merge的操作。
十四、相关度评分算法
算法介绍
ES中使用了term frequency / inverse document frequency算法,简称TF/IDF算法。是ElasticSearch相关度评分算法的一部分,也是最重要的部分。【ES5.x之后使用的是BM25模型,是对TF/IDF算法的优化】
TF :计算搜索条件分词后,各词条在document的field中出现了多少次,出现次数越多,相关度越高。
IDF:计算搜索条件分词后,各词元在整个index中的所有document中出现的次数越多,相关度越低。
Field-length Norm:在匹配成功后,计算field字段数据的长度,长度越大,相关度越低。【TF算法的一部分】
ES中底层计算相关度的时候,不是简单的加减乘除,有其特有的算法。且与文档所存在的shard相关
GET /es/doc/_search
{
"query": {
"match": {
"note": "people"
}
},
"explain": true //使用explain查看评分的详细解释
}
相关度分数计算步骤
第一步:boolean model
ElasticSearch搜索的时候,首先根据搜索条件,过滤符合条件的document。这个时候ES是不做相关度分数计算的,只是记录true或false,标记document是否符合搜索要求。
第二步:TF/IDF
用于计算单个term在document中的相关度分数
第三步:
向量空间模型算法。用于计算多个term对一个document的搜索相关度分数。
ElasticSearch会根据一个term对于所有document的相关度分数,来计算得出一个query vector。在根据多个term对于一个document的相关度分数,来计算得出若干document vector。将这些计算结果放入一个向量空间,再通过一些数学算法来计算document vector相对于query vector的相似度,来得到最终相关度分数。
多shard环境中相关度分数不准确问题
在ElasticSearch的搜索结果中,相关度分数不是一定准确的。相同的数据,使用相同的搜索条件搜索,得到的相关度分数可能有误差。只要数据量达到一定程度,相关度分数误差就会逐渐趋近于0。
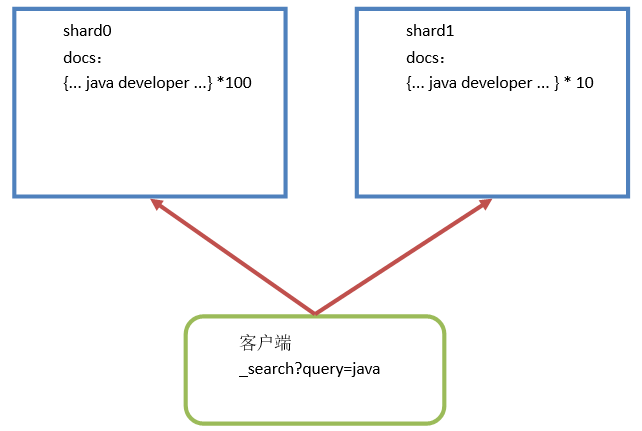
在shard0中,有100个document中包含java词组。在shard1中,有10个document中包含java词组,在执行搜索的时候,ES计算相关度分数时,就会出现计算不准确的问题。因为ES计算相关度分数是在shard本地计算的。根据TF/IDF算法,在shard0中的document相关度分数会低于shard1中的相关度分数。
调节、优化相关对评分的方式
query-time boost
指搜索的时候,提供boost,来影响相关度评分
GET /student/java/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"remark": {
"value": "developer",
"boost":2 //默认值为1
}
}
},
{
"term": {
"remark": {
"value": "architect"
}
}
}
]
}
}
}
negative boost
用于降低一个term的相关度分数比例,使之往后排列
GET /es/doc/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"note": "people"
}
},
"negative": {
"match": {
"note": "enough"
}
},
"negative_boost": 0.2 //降低negative下的得分
}
}
}
constant_score
不计算相关度评分,执行的时候会忽略相关度评分过程,所有的document的相关度分数都是1。在6.x中,constant_score内不能再使用query语法。只能通过filter来实现数据的过滤。所以这种影响相关度分数的方式已经没有太大的意义了。毕竟filter本来就不计算相关度分数。
使用function score自定义相关分数算法
ElasticSearch支持自定义相关度分数计算函数,这个自定义的相关度分数可以参与到ES的相关度分数计算结果中,甚至可以替换相关度评分,但无法跳过相关度分数计算步骤。很少使用。
GET /fscore/doc/_search
{
"query": {
"function_score": {
"query": {
"match": {
"f": "hello spark"
}
},
"field_value_factor": {
//number_of_votes所在字段
"field": "fc",
//field字段的计算公式log(1 + number_of_votes)
"modifier": "log1p",
//可以进一步影响分数,增加后,对fc字段的计算公式为log(1 + factor * number_of_votes)
"factor": 1.2
},
//决定ES计算的相关度分数与指定字段的值如何计算
"boost_mode": "sum",
//限制字段fc最终计算出来的分数的最大值
"max_boost": 0.3
}
}
}
十五、数据建模
一对一数据建模
一般对数据进行组合存储。将某一个数据结构作为一部分(对象类型属性)实现数据的存储。
PUT person_index
{
"mappings": {
"persons": {
"properties": {
"last_name": {
"type": "keyword"
},
"first_name": {
"type": "keyword"
},
"age": {
"type": "byte"
},
"identification_id": { //身份证信息和个人是一对一关系
"properties": {
"id_no": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
}
}
}
一对多数据建模
==================================一个用户对应多个地址==================================
PUT /user
{
"mappings": {
"doc" : {
"properties": {
"login_name" : {
"type" : "keyword"
},
"age " : {
"type" : "short"
},
"address" : {
"properties": {
"province" : {
"type" : "keyword"
},
"city" : {
"type" : "keyword"
},
"street" : {
"type" : "keyword"
}
}
}
}
}
}
}
优点:思想简单,建模方便,查询方便
缺点:数据大量冗余、耦合程度高、不易修改与维护
nested object
如果使用”一个用户对应多个地址”的存储方式,查询市和街道同时满足条件会返回大量不是我们想要的数据【返回中包含市匹配而街道不匹配的和街道匹配而市不匹配的】,原因是ElasticSearch对底层对象做了扁平化处理。
//查询北京、建材城西路上述数据也会返回但是并不是我们需要的
{
"login_name" : "jack",
"address.province" : [ "北京", "天津" ],
"address.city" : [ "北京", "天津" ]
"address.street" : [ "西三旗东路", "古文化街" ]
}
建立nested索引使ElasticSearch不进行扁平化处理
PUT /user
{
"mappings": {
"doc" : {
"properties": {
"login_name" : {
"type" : "keyword"
},
"age " : {
"type" : "short"
},
"address" : {
"type": "nested",
"properties": {
"province" : {
"type" : "keyword"
},
"city" : {
"type" : "keyword"
},
"street" : {
"type" : "keyword"
}
}
}
}
}
}
}
ElasticSearch内部存储结构会变为
{
{
"login_name" : "jack"
},
[
{
"address.province" : "北京",
"address.city" : "北京",
"address.street" : "西三旗东路"
},
{
"address.province" : "北京",
"address.city" : "北京",
"address.street" : "西三旗东路",
}
]
}
nested查询&聚合语法
=========================================查询=========================================
GET /user_index/doc/_search
{
"query": {
"nested": { //指定nested查询
"path": "address", //指定nested字段
"query": {
"bool": {
"must": [
{
"match": {
"address.province": "北京"
}
},
{
"match": {
"address.street": "建材城西路"
}
}
]
}
}
}
}
}
================================聚合条件只包含nested字段================================
GET /user_index/user/_search
{
"size": 0,
"aggs": {
"group_by_address": {
"nested": { //指定nested字段信息
"path": "address"
},
"aggs": {
"group_by_province": {
"terms": {
"field": "address.province"
},
"aggs": {
"group_by_city": {
"terms": {
"field": "address.city"
}
}
}
}
}
}
}
}
================================聚合条件不仅包含nested字段===============================
GET /user_index/user/_search
{
"size": 0,
"aggs": {
"group_by_address": {
"nested": {
"path": "address"
},
"aggs": {
"group_by_province": {
"terms": {
"field": "address.province"
},
"aggs": {
"reverse_aggs": {
"reverse_nested": {}, //标识子聚合不在nested字段中进行
"aggs": {
"avg_by_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
}
}
}
}
虽然语法变的复杂了,但是在数据的读写操作上都不会有错误发生,是推荐的设计方式。
父子关系数据建模
父子关系数据建模是模拟关系型数据库的建模方式,用不同的索引保存各自的数据,通过底层提供的父子关系,让ElasticSearch辅助实现类似关系型数据库的多表联合查询。这种建模方式,数据几乎没有冗余,且查询效率高。
==================================建立父子关系mapping==================================
PUT /ecommerce_products_index
{
"mappings": {
"ecommerce": {
"properties": {
"category_name": {
"type": "text",
"analyzer": "ik_max_word"
},
"product_name": {
"type": "text",
"analyzer": "ik_max_word"
},
"remark": {
"type": "text",
"analyzer": "ik_max_word"
},
"price": {
"type": "long"
},
"sellpoint": {
"type": "text",
"analyzer": "ik_max_word"
},
"ecommerce_join_field": { //描述父子关系
"type": "join", //类型为join
"relations": { //关系描述,父在前,子在后
"category": "product"
}
}
}
}
}
}
=======================================插入数据========================================
POST /ecommerce_products_index/ecommerce/_bulk
{"index" : {"_id" : "1"}}
{"category_name" : "电视", "ecommerce_join_field" : { "name" : "category" }}
{"index" : {"_id" : "2"}}
{"category_name" : "电脑", "ecommerce_join_field" : { "name" : "category" }}
{"index" : {"_id" : "3"}}
{"category_name" : "手机", "ecommerce_join_field" : { "name" : "category" }}
{"index" : {"_id" : "4", "routing" : "1"}}
{"product_name" : "长虹电视", "remark" : "国产电视", "price" : 199800, "sellpoint" : "便宜,个大", "ecommerce_join_field" : { "name" : "product", "parent" : "1" }}
{"index" : {"_id" : "5", "routing" : "1"}}
{"product_name" : "西门子电视", "remark" : "进口电视", "price" : 599800, "sellpoint" : "就是贵", "ecommerce_join_field" : { "name" : "product", "parent" : "1" }}
{"index" : {"_id" : "6", "routing" : "2"}}
{"product_name" : "Thinkpad T99", "remark" : "不知道啥时候生产", "price" : 2999800, "sellpoint" : "可能会生产吧?", "ecommerce_join_field" : { "name" : "product", "parent" : "2" }}
{"index" : {"_id" : "9", "routing" : "3"}}
{"product_name" : "IPhone X", "remark" : "齐刘海手机", "price" : 899800, "sellpoint" : "卖肾买手机", "ecommerce_join_field" : { "name" : "product", "parent" : "3" }}
在父子关系数据模型中,要求有关系的父子数据必须在同一个shard中保存,否则ES无法实现数据的关联管理,所以在保存子数据的时候,必须使用其对应的父数据在存储时使用的routing。默认情况下,ES使用document的id作为routing值,所以子数据在保存的时候,必须使用父数据的id作为routing才可,否则无法建立父子关系。
父子关系查询数据
=================================查询类型指定父类型的数据================================
GET /ecommerce_products_index/ecommerce/_search
{
"query": {
"parent_id": {
"type": "product",
"id": 1
}
}
}
===============================查询满足条件的父类型的子类型===============================
GET /ecommerce_products_index/ecommerce/_search
{
"query": {
"has_parent": {
"parent_type": "category",
"query": {
"match": {
"category_name": "电脑"
}
}
}
}
}
===============================查询满足条件的子类型的父类型===============================
GET /ecommerce_products_index/ecommerce/_search
{
"query": {
"has_child": {
"type": "product",
"query": {
"range": {
"price": {
"gte": 500000,
"lte": 1000000
}
}
}
}
}
}
父子关系聚合数据
==================================计算品类下产品的均价===================================
GET /ecommerce_products_index/ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_category": {
"terms": {
"field": "category_name.keyword"
},
"aggs": {
"products_bucket": {
"children": {
"type": "product"
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
Nested与Parent/Child对比
| 对比 | Nested Object | Parent/Child |
|---|---|---|
| 优点 | 文档存储在一起所以读性能高 | 父子文档可以独立更新,互不影响 |
| 缺点 | 更新父或子文档时需要更新整个文档 | 为了维护join关系,需要占用部分内存读取性能较差 |
| 场景 | 子文档偶尔更新,查询频繁 | 子文档更新频繁 |
文件系统数据建模
用于实现文件目录搜索
=======================================创建索引========================================
PUT /code
{
"settings": {
"analysis": {
"analyzer": {
"path_analyzer": { //创建路径分析器
"tokenizer": "path_hierarchy"
}
}
}
},
"mappings": {
"doc": {
"properties": {
"path": {
"type": "text",
"analyzer": "path_analyzer", //使用路径分析器
"fields": {
"stand": {
"type": "text",
"analyzer": "standard"
}
}
},
"author": {
"type": "text",
"analyzer": "standard"
},
"content": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}
=======================================查询数据========================================
GET /code/doc/_search
{
"query": {
"match": {
"path": "/com" //只能搜索出/com/kun路径开始的doc
}
}
}
GET /code/doc/_search
{
"query": {
"match": {
"path.stand": "/com/kun" //能搜索包含/com/kun的路径
}
}
}
十六、重建索引&零停机
重建索引-reindex
索引类型一旦建立便不可更改,如果要修改数据类型,只能重建索引:用新的设置创建新的索引并把文档从旧的索引复制到新的索引。
方法一:用 scroll 从旧的索引检索批量文档 ,然后用 bulk API 把文档推送到新的索引中
//准备数据
PUT /old_index/test_type/1
{
"field" : "2018-08-08"
}
PUT /old_index/test_type/2
{
"field" : "2018-08-07"
}
PUT /old_index/test_type/3
{
"field" : "2018-08-06"
}
//新建索引mapping
PUT /new_index
{
"mappings": {
"test_type":{
"properties":{
"field":{
"type": "keyword"
}
}
}
}
}
//读取信息
GET old_index/test_type/_search?scroll=1m
{
"query" : {
"match_all" : {}
},
"sort" : [ "_doc" ],
"size" : 1
}
GET /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "根据具体返回结果替换"
}
//bulk批量添加数据
POST /_bulk
{"index" : {"_index" : "new_index", "_type" : "test_type", "_id" : "1"}}
{"field" : "2018-08-08"}
方法二:使用_reindex迁移索引数据
//默认情况下一次批处理1000条记录,也可支持远程索引重建
//wait_for_completion=false 后台执行执行,返回任务id,通过id查看进度 GET _tasks/[taskId]
POST _reindex?wait_for_completion=false
{
"conflicts": "proceed", //冲突时覆盖并继续
"source": {
"index": "old_index" //还可以添加query条件
},
"dest": {
"index": "new_index"
}
}
零停机
零停机问题:reindex索引,操作指向新的index,则必须停止后台服务,更改索引名称,这样会引起停机问题。
解决方案:可以使用索引别名来解决reindex中的索引名变更问题。
别名特性:在ElasticSearch中一个别名可以指向多个索引,一个索引也可以被多个别名指向。
//定义索引别名
PUT index_name/_alias/alias_index
//原子操作,移除就别名指向,添加新别名指向
POST _aliases
{
"actions": [
{
"add": {
"index": "new_index",
"alias": "current_index"
}
},
{
"remove": {
"index": "old_index",
"alias": "current_index"
}
}
]
}
建议:在应用中使用别名而不是索引名。这样可以在任何时候重建索引,且别名的开销很小
其它使用场景:如电商中有手机索引,座机索引,使用别名电话设备作为两个索引的别名。访问电话设备,则可以在两个索引中搜索数据。
十七、正排索引
ElasticSearch在存储document时,会根据document中的field类型建立对应的索引。通常来说只创建倒排索引,倒排索引是为了搜索而存在的。但是如果对数据进行排序、聚合、过滤等操作的时候,就需要创建正排索引(doc values)。doc values会保存到磁盘中,如果OS的内存足够会被缓存。
Doc values只在不分词的字段中存在。倒排索引只在分词的字段中出现。正排索引和倒排索引不是在同一个字段同时存在的。但可以使用fielddata替代doc values正排索引和倒排索引在同一个字段出现。
如果字段类型为text。那么默认是需要分词的,则只有倒排索引。
如果真的需要同时使用倒排索引和正排索引,都是使用子字段的方式来实现。
Doc Values与聚合分析内部原理
假设倒排索引的内容如下【文档模型中只有一列body】
Term Doc_1 Doc_2 Doc_3
-------------------------------------------------------------------------------------
brown | X | X |
dog | X | | X
dogs | | X | X
fox | X | | X
foxes | | X |
in | | X |
jumped | X | | X
lazy | X | X |
leap | | X |
over | X | X | X
quick | X | X | X
summer | | X |
the | X | | X
-------------------------------------------------------------------------------------
GET /my_index/_search
{
"aggs" : {
"popular_terms": {
"terms" : {
"field" : "body"
}
}
}
}
聚合部分,则无法使用正拍索引【不容易确定原doc内容】。Doc values 通过转置两者间的关系来解决这个问题。倒排索引将词项映射到包含它们的文档,doc values(正排索引) 将文档映射到它们包含的词项
Doc Terms
--------------------------------------------------------------------------------------
Doc_1 | brown, dog, fox, jumped, lazy, over, quick, the
Doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer
Doc_3 | dog, dogs, fox, jumped, over, quick, the
--------------------------------------------------------------------------------------
当数据被转置之后,收集到 Doc中的token信息会非常容易。获得每个文档行,获取所有的词项即可。
Doc values 不仅可以用于聚合。还包括排序,访问字段值的脚本,父子关系处理。Doc values是在不可分词的类型field中创建的。如:keyword、int、date、long等
doc values特征总结
-
doc values也是索引创建时生成的,简单来说,就是数据录入索引时创建正排索引(index-time)
-
doc values也有缓存应用(内存级别, OS cache等),如果内存不足时,doc values 会写入磁盘文件
ElasticSearch大部分操作都是基于系统缓存进行的,而不是JVM。官方建议不要给JVM分配太多的内存空间,这样会导致GC开销太大。通常来说,给JVM分配的内存不超过服务器物理内存的1/4。
fielddata
如何没有建立doc value可设置fielddata=true,这样可以反转倒排索引并加载到内存中。大量消耗资源不推荐使用。默认fielddata在query time时产生。
如果必须在text类型的field上,执行聚合分析。则由两种实现方案:
-
为text类型的field增加一个子字段,子字段类型为keyword,执行聚合分析的时候,使用自字段(推荐方案)
-
在text类型的field中,设置fielddata=true,辅助完成聚合分析。【以内存为代价】
fielddata内存
- fielddata对内存的开销极大,可以通过参数来设置内存限制。在配置文件config/elasticsearch.yml中增加
indices.fielddata.cache.size : 20%
- fielddata内存监控命令
GET _stats/fielddata?fields=*
GET _nodes/stats/indices/fielddata?fields=*
GET _nodes/stats/indices/fielddata?level=indices&fields=*
- circuit breaker短路器
如果一次聚合操作时,加载的fielddata超过了总内存容量,则会抛出内存溢出错误(OOM out of memory),这个时候可以增加短路器circuit breaker,circuit breaker会估算本次操作要加载的fielddata大小,如果超出了总内存容量,则请求短路,直接返回错误响应,不会产生OOM错误导致ES所在节点宕机或应用关闭。
indices.breaker.fielddata.limit : 60% # fielddata的内存限制,默认60%
indices.breaker.request.limit: 40% # 执行聚合的一次请求的内存限制,默认40%
indices.breaker.total.limit: 70% # 综合上述两个限制,总计内存限制多少。默认无限制。
fielddata的filter过滤
在创建index时,为fielddata增加filter过滤器,实现一个更加细粒度的内存控制。
min:只有聚合分析的数据在大于min的document中出现过,才会加载fielddata到内存中。
max:只有聚合分析的数据在小于max的document中出现过,才会加载fielddata到内存中。
min_segment_size: 只有segment中的document数量大于min_segment_size时,才会加载到内存中。
PUT /fieddata_filter
{
"mappings": {
"doc": {
"properties": {
"note": {
"type": "text",
"fielddata": true,
"fielddata_frequency_filter": {
"min": 0.001,
"max": 0.1,
"min_segment_size": 500
}
}
}
}
}
}
fielddata的预加载
fielddata是一个query-time生成的正排索引,如果某index中必须使用fielddata,又希望可以提升其效率,则可以使用预加载的方式来实现性能的提升。预加载fielddata会提高query过程的效率,但是降低index写入数据的效率。且始终对内存有很高的压力。不建议使用。
PUT /fieddata_filter
{
"mappings": {
"doc": {
"properties": {
"note": {
"type": "text",
"fielddata": true,
"fielddata_frequency_filter": {
"min": 0.001,
"max": 0.1,
"min_segment_size": 500
},
"eager_global_ordinals": true //开启预加载,默认false
}
}
}
}
}