Kafka的使用
一、概述&安装
概述
Kafka是一个大数据流处理平台
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
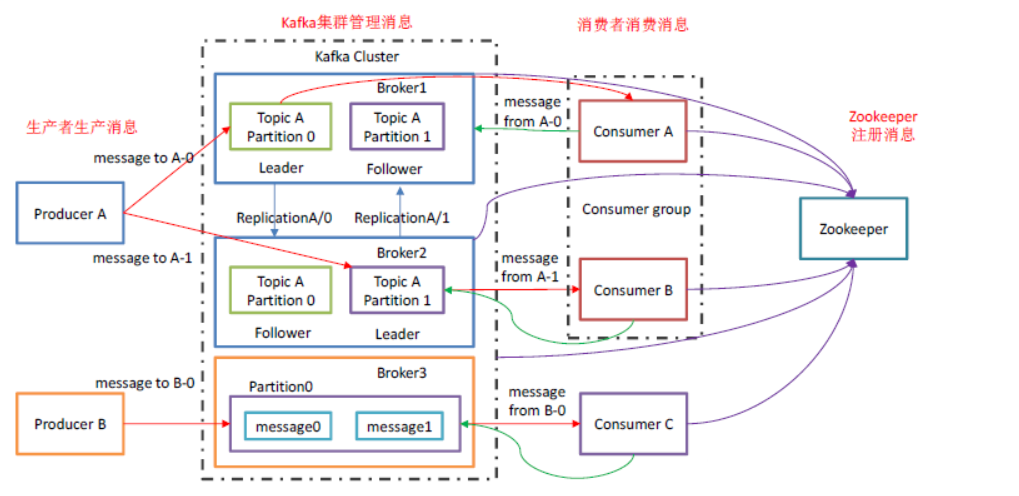
-
Producer
消息生产者
-
Consumer
消息消费者
-
Consumer Group (CG):
消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。消费者组之间互不影响,所有的消费者都属于某个消费者组
-
Broker
一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic
-
Topic
可以理解为一个队列,生产者和消费者面向的都是一个topic
-
Partition
一个topic可以分为多个partition,每个partition是一个有序的队列
-
Replica
副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower
-
leader
每个分区多个副本的”主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader
-
follower
每个分区多个副本中的”从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的follower,follower不提供面向消费者和生产者的服务
安装启动
配置server.properties文件
# *broker全局唯一编号,不能重复
broker.id=0
# *主题是否可删除
delete.topic.enable=true
# 插入一个不存在的topic时,kafka是否自动创建此topic
auto.create.topics.enable=false
# 处理网络请求的线程数
num.network.threads=3
# 处理磁盘IO的线程数
num.io.threads=8
# 发生套接字缓冲区大小
socket.send.buffer.bytes=102400
# 接收套接字缓冲区大小
socket.receive.buffer.bytes=102400
# 请求套接字缓冲区大小
socket.request.max.bytes=104857600
# 数据存储目录
log.dirs=/opt/module/kafka/config/data
# 默认分区数
num.partitions=1
# 用来恢复和清除data下数据的线程数
num.recovery.threads.per.data.dir=1
# topic的offset的备份份数。建议设置更高的数字保证更高的可用性建议以下设置为3
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# 数据文件设置
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
# *zk连接配置
zookeeper.connect=centos161:2181,centos162:2181,centos163:2181
zookeeper.connection.timeout.ms=18000
# 消费者组内消费者负载均衡延迟时间
group.initial.rebalance.delay.ms=0
常用命令
# 启动节点
kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
# 停止运行
kafka-server-stop.sh
# 查看主题列表
kafka-topics.sh --zookeeper centos161:2181 --list
# 创建Topic
# replication-factor:follower + leader数目
# partitions:分区数
kafka-topics.sh --zookeeper [ip:port] --create --replication-factor [num] --partitions [num] --topic [topicName]
# 删除主题
kafka-topics.sh --zookeeper [ip:port] --delete --topic [topicName]
# 查看某个topic详情
kafka-topics.sh --zookeeper [ip:port] --describe --topic [topicName]
# 修改分区数,只能增加
kafka-topics.sh --zookeeper [ip:port] --alter --topic [topicName] --partitions [num]
# 模拟生成
kafka-console-producer.sh --topic first2 --broker-list centos161:9092
# 模拟消费
kafka-console-consumer.sh --bootstrap-server centos161:9092, centos162:9092, centos163:9092 [--from-beginning] --topic [topicName]
群起脚本
#!/bin/bash
host_name_arr=('centos161' 'centos162' 'centos163')
for host_name in ${host_name_arr[*]}
do
echo '========================'$host_name'===================='
if [ "$1" == "start" ] ; then
ssh $host_name "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
fi
if [ "$1" == "stop" ] ; then
ssh $host_name "/opt/module/zookeeper/bin/kafka-server-stop.sh /opt/module/kafka/config/server.properties"
fi
echo -e '\n'
done
二、kafka架构
工作流程及文件存储机制
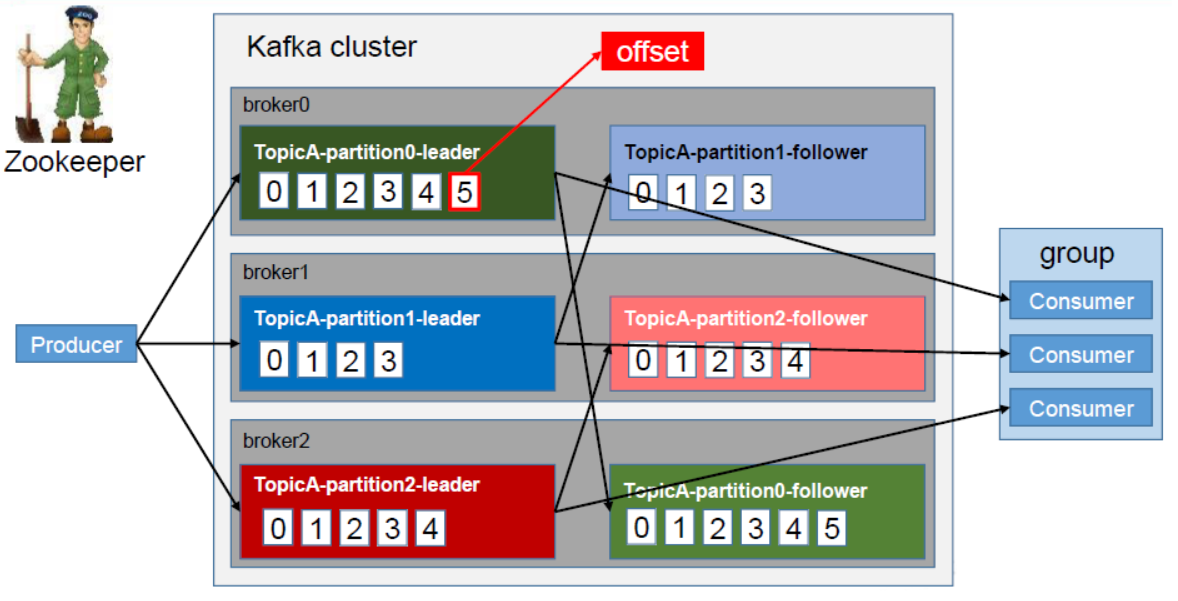
Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。 消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
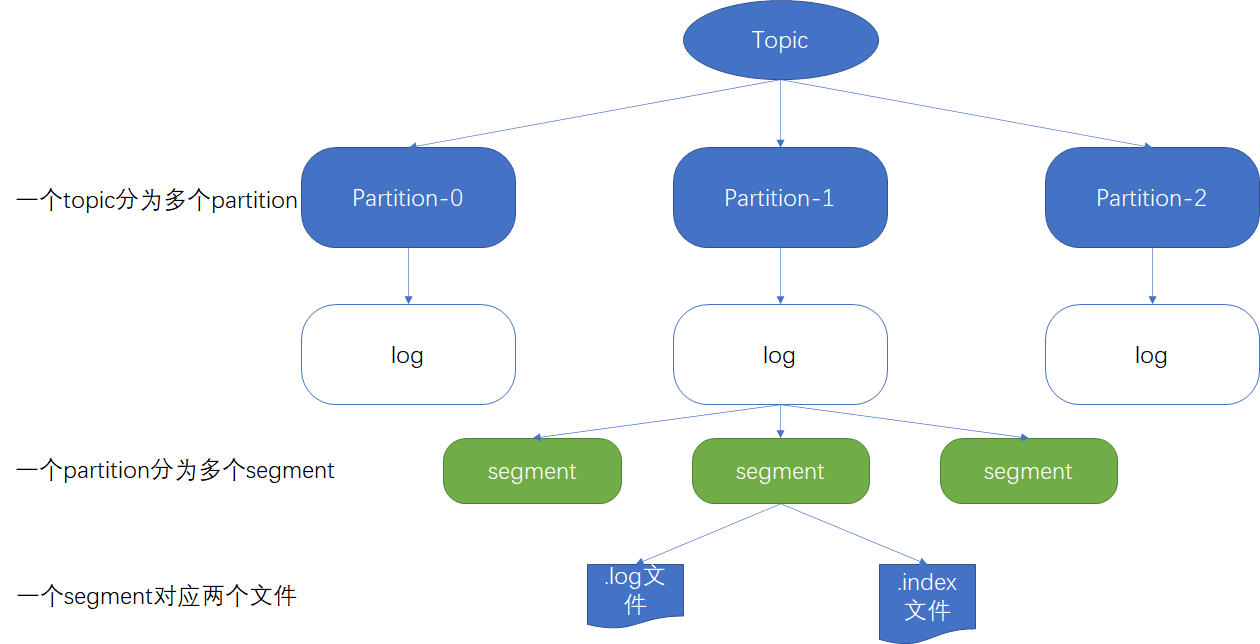
由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个patition分为多个segment。每个segment对应.index文件【存储索引】和*.1og文件【存储数据】。这些文件位于一个文件夹下,该文件夹的命名规则为topic名称+分区序号。
生产者数据可靠性保证
为保证Producer发送的数据能可靠的发送到指定的topic,topic的每个partition收到Producer发送的数据后,都需要向Producer发送ack。如果Producer收到ack,就会进行下一轮的发送,否则重新发送数据。
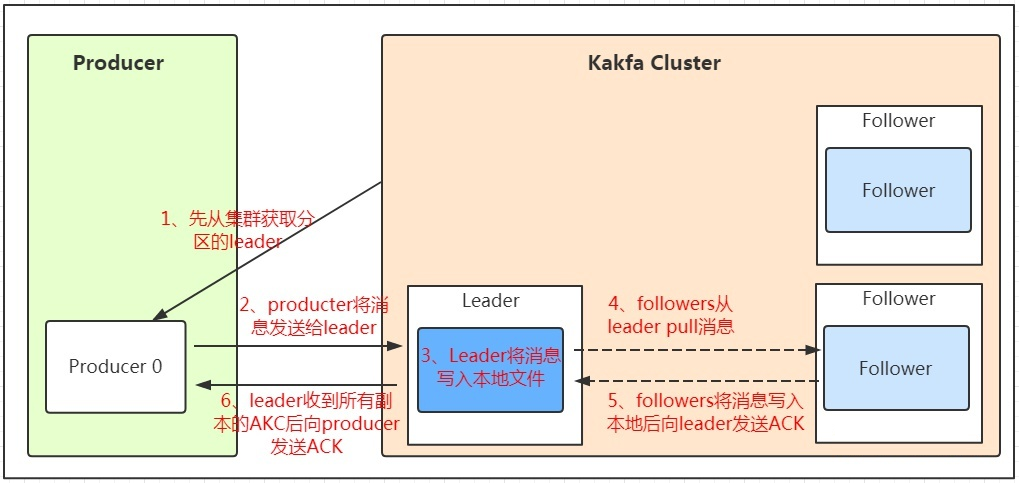
Kafka使用了等待全部ISR节点同步才发送返回的ACK的信息【并非全部follower节点】
ISR:leader维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。leader发生故障之后,就会从ISR中选举新的leader。
Kafka为用户提供了三种可靠性级别,ACK参数设置如下
| 值 | 描述 |
|---|---|
| 0 | Producer不等待broker的ack,这一操作提供了一个最低的延迟,broker接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据; |
| 1 | Producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据; |
| -1(all) | Producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader 发生故障,那么会造成数据重复。 |
offsets.commit.required.acks默认为-1
leader宕机且ISR只有leader节点
kafka在Broker端提供了一个配置参数unclean.leader.election这个参数有两个值:
- true(默认)允许不同步副本成为leader,由于不同步副本的消息较为滞后,此时成为leader,可能会出现消息不一致的情况。
- false不允许不同步副本成为leader,此时如果发生ISR列表为空,会一直等待旧leader恢复,降低了可用性。
生产者数据一致性问题【可见性】
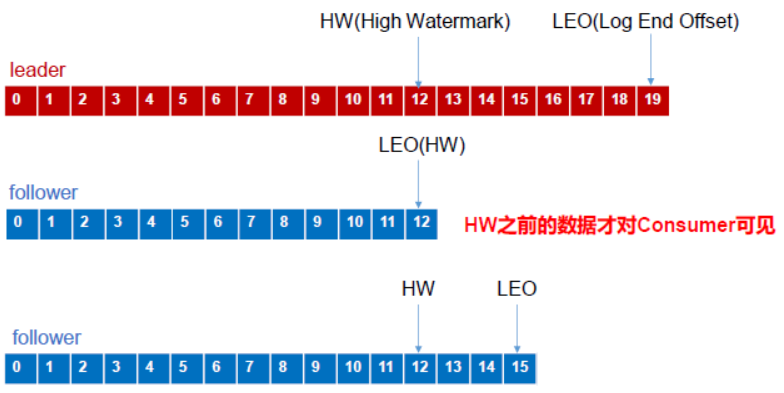
-
LEO【Log End Offset】:指每个副本的最大的offset
-
HW【High Watermark】:高水位,指消费者能看见的最大的offset
当follower故障时
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader 进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR。
当leader故障时
leader发生故障之后,会从ISR中选出一个新的leader,之后为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
Exactly Once语义
At Least Once【最少一次】、At Most Once【最多一次】、Exactly Once【精准一次】
0.11版本的Kafka,引入了幂等性。所谓的幂等性就是指Producer不论向Server发送多少次重复数据,Server 端都只会持久化一条。幂等性结合At Least Once语义,就构成了Kafka的Exactly Once语义。即: At Least Once + 幂等性 = Exactly Once
要启用幂等性,需要将Producer的参数中enable.idompotence设置为true,此时ACK已经为-1。Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条。
但是PID重启就会变化,同时不同的Partition也具有不同主键,所以幂等性无法保证跨分区跨会话的Exactly Once。
消费者消费方式
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
消费者分区分配策略
Kafka记录offset是以
consumer group + topic + partition记录
一个consumer group中有多个consumer,一个topic有多个partition, 所以必然会涉及到partition的分配问题,即确定那个partition由哪个consumer来消费。Kafka有两种分配策略Round Robin和Range。
Range策略
Range策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。如果是4个分区3个消费者,排完序的分区将会是0,1,2,3;消费者排完序将会是C1,C2,C3。然后将partitions的个数除于消费者的总数来决定每个消费者消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。即C1消费0,3;C2消费1;C3消费2
Round Robin策略
使用RoundRobin策略有两个前提条件必须满足:
- 同一个Consumer Group里面的所有消费者的num.streams必须相等
- 每个消费者订阅的主题必须相同
Round Robin策略的工作原理:将消费者组按字典排序然后轮询分配。假设现在有CG1订阅T0[P0],CG2订阅T1[P0,P1],CG3订阅T0,T1。则分配为CG1:T0P0;CG2:T1P0;CG3:T1P1;
offset的维护
默认将offset保存在Kafka一个内置的topic中,该topic为_consumer_offsets ,默认有50个分区。记录的KEY是消费者组ID、Topic、Partition的组合。
事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。为了管理Transaction,Kafka 引入了一个新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态。Transaction Coordinator还负责将事务所有写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
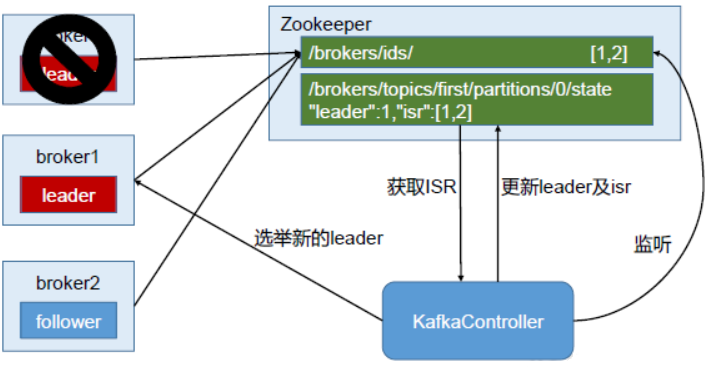
Zookeeper在Kafka中的作用
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。 Controller的管理工作都是依赖于Zookeeper的。
三、Spring boot kafka
AdminClient API
创建Topic
// 如果要修改分区数,只需修改配置值重启项目即可。修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小
// 删除Topic机会少,可使用命令行工具或者GUI工具操作
@Bean
public NewTopic initialTopic() {
return new NewTopic("test-topic", 8, Short.parseShort("2"));
}
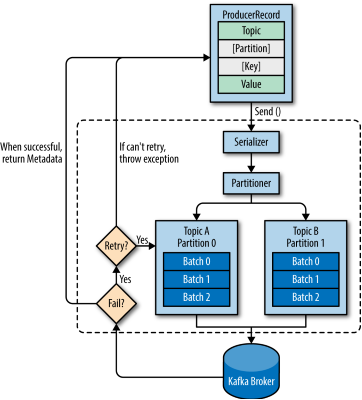
Producers API
Producer并不是一条一条发送消息的,而是批量发送。Producer最主要会启动两个线程,第一个是启动守护进程用于轮询队列元素是否满足发送条件,第二个是调用send方法是会创建一个线程用于向队列插入元素。
spring boot生产者配置
spring.kafka.bootstrap-servers=192.168.22.161:9092,192.168.22.162:9092,192.168.22.163:9092
#######################################【初始化生产者配置】#######################################
# 重试次数
spring.kafka.producer.retries=1
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=-1
# broker用来识别消息是来自哪个客户端的。在broker进行打印日志、衡量指标或者配额限制时会用到
spring.kafka.admin.client-id=kun-117
# 批量发送大小
spring.kafka.producer.batch-size=16384
# 提交延时
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
spring.kafka.producer.properties.linger.ms=0
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory=33554432
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.springframework.kafka.support.serializer.JsonSerializer
# 自定义分区器
# spring.kafka.producer.properties.partitioner.class=com.kun.kafka.producer.CustomizePartitioner
# 消息的压缩发送,可选择snappy、gzip或者lz4,默认不压缩
# spring.kafka.producer.compression-type=snappy
# 事务前缀,配置即开启事务
# spring.kafka.producer.transaction-id-prefix=${spring.kafka.admin.client-id}
发送消息
// 发送消息
kafkaTemplate.send("test-topic", new UserBean("kun", 18));
// 发送消息,取key的hashcode发送到指定的partition
kafkaTemplate.send("test-topic", "key-1", new UserBean("Jack", 20));
// 发送消息,根据传入的partition发送到指定的partition
kafkaTemplate.send("test-topic", 0, "", new UserBean("Jane", 21));
// 发送消息,根据传入的partition发送到指定的partition,并添加当前时间戳作为消息头
kafkaTemplate.send("test-topic", 0, DateUtil.currentSeconds(), "", new UserBean("Lot", 33));
发送消息添加回调功能
UserBean user = new UserBean("kun", 18);
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send("test-topic", user);
future.addCallback(sendResult -> {
log.info("{}", sendResult.getRecordMetadata());
log.info("{}", sendResult.getProducerRecord());
}, throwable -> log.info("{}", throwable));
发送消息的事务功能
// 需要设置spring.kafka.producer.transaction-id-prefix
kafkaTemplate.setAllowNonTransactional(true);
kafkaTemplate.send("test-topic-1", "key-1", new UserBean("Jack", 20));
kafkaTemplate.send("test-topic-1", 0, "", new UserBean("Jane", 21));
kafkaTemplate.setAllowNonTransactional(false);
// 发送事务消息
kafkaTemplate.executeInTransaction(kafkaOperations -> {
kafkaTemplate.send("test-topic-1", new UserBean("Transaction-1", 18));
kafkaTemplate.send("test-topic-1", new UserBean("Transaction-2", 18));
if(true){
throw new RuntimeException("模拟异常");
}
kafkaTemplate.send("test-topic-1", new UserBean("Transaction-3", 18));
return true;
});
监听发送消息
// spring boot本身自带的日志打印
@Bean
public ProducerListener<Object, Object> kafkaProducerLoggingListener() {
return new LoggingProducerListener<>();
}
// 自定义功能
@Bean
public ProducerListener<Object, Object> kafkaProducerListener() {
ProducerListener<Object, Object> listener = new ProducerListener<Object, Object>(){
private int errorCounter = 0;
private int successCounter = 0;
@Override
public void onSuccess(ProducerRecord<Object, Object> producerRecord, RecordMetadata recordMetadata) {
successCounter++;
System.out.println("成功个数" + successCounter);
}
@Override
public void onError(ProducerRecord<Object, Object> producerRecord, Exception exception) {
errorCounter++;
System.out.println("失败个数" + errorCounter);
}
};
return listener;
}
Consumer API
Consumer并不是一条一条拉取消息的,而是批量拉取,逐一消费,Consumer不是线程安全的
spring boot 消费者配置
spring.kafka.bootstrap-servers=192.168.22.161:9092,192.168.22.162:9092,192.168.22.163:9092
#######################################【初始化消费者配置】#######################################
# 默认的消费组ID
spring.kafka.consumer.properties.group.id=kun-117-consumerGroup
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
# 最大拉取条数据需要在session.timeout.ms这个时间内处理完,默认:500
spring.kafka.consumer.max-poll-records=500
# 消费超时时间,大小不能超过session.timeout.ms,默认:3000
spring.kafka.consumer.heartbeat-interval=3000
# 提交offset延时(接收到消息后多久提交offset),默认:5000
spring.kafka.consumer.auto-commit-interval=5000
# 当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
# 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费端监听的topic不存在时,项目启动是否会报错
spring.kafka.listener.missing-topics-fatal=true
# 每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回。默认:1
spring.kafka.consumer.fetch-min-size=1
# Fetch请求发给broker后,在broker中可能会被阻塞的(当topic中records的总size小于fetch.min.bytes时),此时这个fetch请求耗时就会比较长。这个配置就是来配置consumer最多等待response多久。
spring.kafka.consumer.fetch-max-wait=500
# 设置批量消费
# spring.kafka.listener.type=batch
单条消费消息并处理异常
@KafkaListener(topics = {"test-topic"},
groupId = "consumer-kun-app",
containerGroup = "consumer-kun-app",
errorHandler = "kafkaListenerErrorHandler")
public void onMessage(ConsumerRecord<String, UserBean> record,
@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) String key) throws Exception {
System.out.println("简单消费:"+record.topic()+"-"+record.partition() + "-" +record.value());
throw new Exception("模拟异常");
}
// 当不需要将失败的消息发送到其它队列时返回null即可
@Bean
public KafkaListenerErrorHandler kafkaListenerErrorHandler() {
// 一下业务逻辑是重置offset,重新消费出现异常的消息,
ConsumerAwareListenerErrorHandler kafkaListenerErrorHandler = (message, exception, consumer) -> {
MessageHeaders headers = message.getHeaders();
String topicName = headers.get(KafkaHeaders.RECEIVED_TOPIC, String.class)
Integer partitionId = headers.get(KafkaHeaders.RECEIVED_PARTITION_ID, Integer.class)
Long offset = headers.get(KafkaHeaders.OFFSET, Long.class);
consumer.seek(new TopicPartition(topicName, partitionId), offset);
return null;
};
return kafkaListenerErrorHandler;
}
批量消费消息并处理异常,需设置spring.kafka.listener.type=batch
@KafkaListener(
topics = {"test-topic"},
groupId = "consumer-kun-app",
containerGroup = "consumer-kun-app",
errorHandler = "kafkaListenerErrorHandler")
public void onMessage(List<ConsumerRecord<String, UserBean>> records) throws Exception {
for (ConsumerRecord<String, UserBean> record : records) {
System.out.println("简单消费:"+record.topic()+"-"+record.partition() + "-" +record.value());
}
throw new Exception("模拟异常");
}
// 将批次中的所有位移都重置为批次中最小的offset
@Bean
public KafkaListenerErrorHandler kafkaListenerErrorHandler() {
ConsumerAwareListenerErrorHandler kafkaListenerErrorHandler = (message, exception, consumer) -> {
MessageHeaders headers = message.getHeaders();
List<String> topics = headers.get(KafkaHeaders.RECEIVED_TOPIC, List.class);
List<Integer> partitions = headers.get(KafkaHeaders.RECEIVED_PARTITION_ID, List.class);
List<Long> offsets = headers.get(KafkaHeaders.OFFSET, List.class);
Map<TopicPartition, Long> offsetsToReset = new HashMap<>();
for (int i = 0; i < topics.size(); i++) {
int index = i;
offsetsToReset.compute(new TopicPartition(topics.get(i), partitions.get(i)),
(k, v) -> v == null ? offsets.get(index) : Math.min(v,offsets.get(index)));
}
offsetsToReset.forEach((k, v) -> consumer.seek(k, v));
return null;
};
return kafkaListenerErrorHandler;
}
直接使用json反序列化消息
/**
* JsonDeserializer限制了可序列化的包名称,需要继承开放权限
* spring.kafka.consumer.value-deserializer=com.kun.kafka.AppJsonDeserializer
*
* 也可配置
* spring.kafka.consumer.value-deserializer=org.springframework.kafka.support.serializer.JsonDeserializer
* spring.kafka.consumer.properties.spring.json.trusted.packages=*
*/
public class AppJsonDeserializer extends JsonDeserializer {
@Override
public void configure(Map configs, boolean isKey) {
super.configure(configs, isKey);
getTypeMapper().addTrustedPackages("com.kun.kafka.bean");
}
}
@KafkaListener(
topics = {"test-topic"},
groupId = "consumer-kun-app",
containerGroup = "consumer-kun-app")
public void onMessage(@Payload UserBean record,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topicName) {
System.out.println("topicName: " + topicName);
System.out.println("record: " + record);
}
消费失败将消息转发到另一队列,此功能是Spring提供,并非死信队列
@KafkaListener(
topics = {"test-topic"},
groupId = "consumer-kun-app",
containerGroup = "consumer-kun-app",
errorHandler = "kafkaListenerErrorHandler")
@SendTo("test-error-topic")
public void onMessage(@Payload UserBean record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topicName,
@Header(KafkaHeaders.RECEIVED_TIMESTAMP) Long time) throws Exception {
System.out.println("topicName: " + topicName);
System.out.println("record: " + record);
System.out.println("time: " + time);
throw new Exception("模拟异常");
}
@Bean
public KafkaListenerErrorHandler kafkaListenerErrorHandler() {
ConsumerAwareListenerErrorHandler handler = (message, exception, consumer) -> message.getPayload();
return handler;
}
Streams API
kafka stream是提供了对存储于Kafka内的数据进行流式处理和分析的功能,是一个程序库
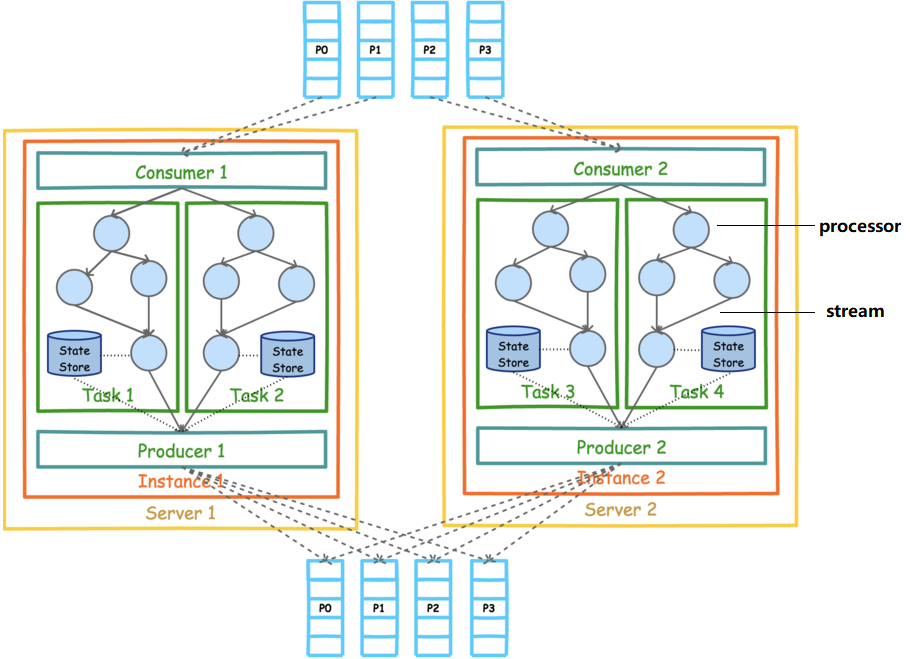
名称解释
- 流处理器【处理流数据的业务处理器】
- 流【业务处理器之间的流向】
- 流处理拓扑【流处理器和流组合形成的拓扑关系】
- Source处理器【数据的来源处理器】
- Slink处理器【数据的结果处理器】
配置 spring boot
spring.kafka.streams.bootstrap-servers=192.168.22.161:9092,192.168.22.162:9092,192.168.22.163:9092
spring.kafka.streams.application-id=stream-kun-117
spring.kafka.streams.properties.default.key.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
spring.kafka.streams.properties.default.value.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
# 缓存文件的目录,目录即使被删除数据依然累计,只是为了加快速度,数据存储在kafka主题中
spring.kafka.streams.state-dir=F:\\dir
统计value重复个数
@Bean
public KStream<String, String> kStream(StreamsBuilder streamsBuilder){
KStream<String, String> stream = streamsBuilder.stream("word-topic");
stream.flatMapValues((values) -> Arrays.asList(values.split(" "))).
groupBy((k, v)-> v).
count().
toStream().
to("result-topic", Produced.with(Serdes.String(), Serdes.Long()));
return stream;
}
Connector API
四、Kafka特性
Kafka高效读写数据
1、顺序写磁盘:Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。
2、零复制技术:采用零拷贝
Kafka的吞吐量大原因
-
均是批量发送接收消息,且有压缩功能
- 有partition机制
- 日志的顺序读写和快速检索
Kafka自有特点
Kafka可以消费以前的数据
Kafka限制
Kafka只能保证Partition内有序,无法保证Topic消息是有序的
消费者&消费者组
- 消费者组是kafka的消费单位
- 单个Partition只能由消费者组中的某个消费者消费
- 消费者组中的单个消费者可以消费多个partition
Kafka如何保证顺序性
第一种:使用单Partition【生产环境不会用】
第二种:使用Kafka的 Key + offset 可以做到业务有序,即顺序业务Key需要相同
Kafka的Topic删除
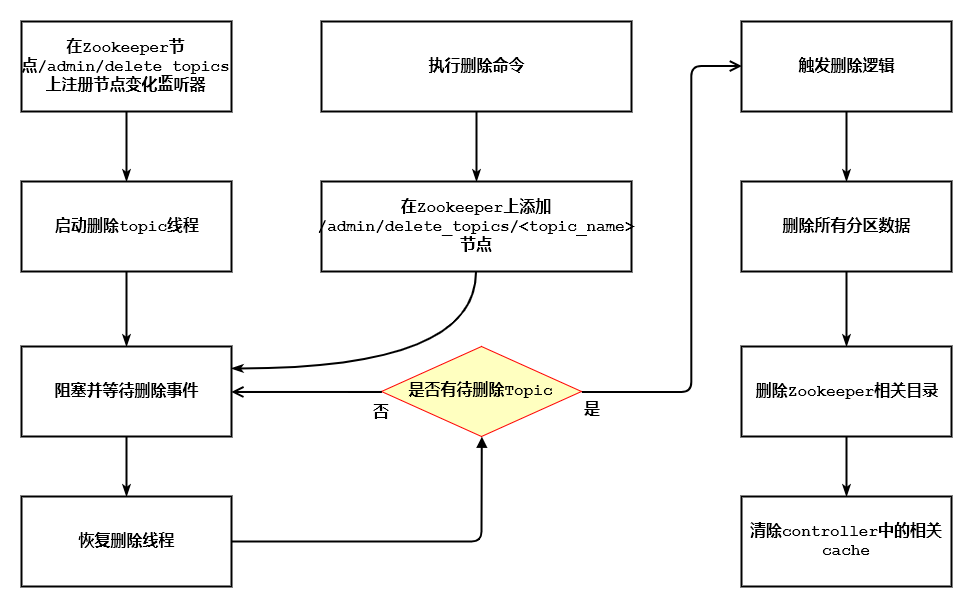
Kafka删除Topic的过程
- Kafka的broker在被选举成controller后,会执行下面几步
- 注册DeleteTopicsListener,监听zookeeper节点/admin/delete_topics下子节点的变化,delete命令实 际上就是要在该节点下创建一个节点,名字是待删除topic名,标记该topic是待删除的
- 创建一个单独的线程DeleteTopicsThread,来执行topic删除的操作
- DeleteTopicsThread线程启动时会先在awaitTopicDeletionNotification处阻塞并等待删除事件的通知,即有新的topic被添加
- 当我们使用了delete命令在zookeeper上的节点/admin/delete_topics下创建子节点< topic_name >
- DeleteTopicsListener会收到ChildChange事件会依次判断如下逻辑:
- 查询topic是否存在,若已经不存在了,则直接删除/admin/delete_topics/< topic_name >节点
- 查询topic是否为当前正在执行Preferred副本选举或分区重分配,若果是,则标记为暂时不适合被删除
- 将该topic添加到queue中,让删除线程继续往下执行
删除线程执行删除操作的真正逻辑是:
- 它首先会向各broker更新原信息,使得他们不再向外提供数据服务,准备开始删除数据。
- 开始删除这个topic的所有分区
- 给所有broker发请求,告诉它们这些分区要被删除。broker收到后就不再接受任何在这些分区上的客户端请求了
- 把每个分区下的所有副本都置于OfflineReplica状态,这样ISR就不断缩小,当leader副本最后也被置于OfflineReplica状态时信息将被更新为-1
- 将所有副本置于ReplicaDeletionStarted状态
- 副本状态机捕获状态变更,然后发起StopReplicaRequest给broker,broker接到请求后停止所有fetcher线程、移除缓存,然后删除底层log文件
- 关闭所有空闲的Fetcher线程
- 删除zookeeper上节点/brokers/topics/< topic_name >
- 删除zookeeper上节点/config/topics/< topic_name >
- 删除zookeeper上节点/admin/delete_topics/< topic_name >
- 并删除内存中的topic相关信息
五、Kafka Manager
CMAK下载地址,编译需要JDK11
第一步:安装SBT
curl https://bintray.com/sbt/rpm/rpm > bintray-sbt-rpm.repo
mv bintray-sbt-rpm.repo /etc/yum.repos.d/
yum install -y sbt
第二步:编译
./sbt clean dist
第三步:提取编译完成文件在target/universal/cmak-[version]
第四步:配置config/application.conf中ZK地址
第五步:启动
nohup bin/cmak -java-home /opt/module/cmak/jdk11 -Dhttp.port=8222 >> output.log 2>&1 &