MyCat的使用
一、MyCat概览
MyCat简介
支持对MySQL等数据库进行垂直切分,水平切分并实现了读写分离和负载均衡的数据库中间件
MyCat的基本元素
逻辑库
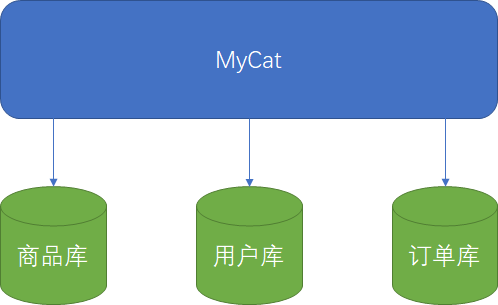
-
对于应用来说相当于MySQL的数据库
-
逻辑库可对应后端的多个物理数据库
-
逻辑库并不保存数据
逻辑表
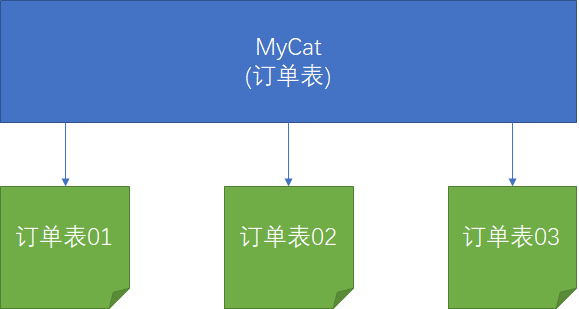
- 对于应用来说相当于MySQL的数据表
- 逻辑表可对应后端的多个物理数据表
- 逻辑表并不保存数据
逻辑表的类别
- 按照是否被水平分片划分为:分片表于非分片表
- 全局表:在所有分片数据库都存在的表
- ER关系表:按照ER关系进行分片的表(子表和夫表存在于同一数据库示例)
安装MyCat
前置条件:JDK7以上
第一步:建立MyCat运行的系统账号
adduser mycat
groupadd mycat
第二步:解压MyCat并将目录所属者
tar -zxvf Mycat-server-X.Y-RELEASE-linux.tar.gz
chgrp -R mycat mycat
第三步:配置环境变量(/etc/profile)
PATH=$PATH:/opt/mycat/bin
export MYCAT_HOME=/opt/mycat
第四步:启动mycat
mycat start
如果测试环境内存有限需要修改MyCat下
bin/wrapper.conf当中的内存限制
二、MyCat核心配置
核心配置文件总览
server.xml:配置系统参数、用户访问权限、SQL防火墙以及SQL拦截
log4j2.xml:日志配置
schema.xml - 逻辑库、逻辑表、物理库定义
rule.xml - 逻辑表水平切分规则
server.xml相关配置
系统参数配置
<system>
<!-- 1为开启实时统计、0为关闭 -->
<property name="useSqlStat">0</property>
<!-- 1为开启全局一致性检测、0为关闭 -->
<property name="useGlobleTableCheck">0</property>
<!-- 指定使用 Mycat 全局序列的类型
0 为本地文件方式
1 为数据库方式
2 为时间戳序列方式
3 为分布式 ZK ID 生成器
4 为 zk 递增 id 生成。
-->
<property name="sequnceHandlerType">2</property>
<!-- 1为开启mysql压缩协议 -->
<!-- <property name="useCompression">1</property> -->
<!-- 设置模拟的MySQL版本号 -->
<!-- <property name="fakeMySQLVersion">5.6.20</property> -->
<!-- 这个属性指定每次分配 Socket Direct Buffer 的大小 -->
<!-- <property name="processorBufferChunk">40960</property> -->
<!-- 处理器缓冲池类型
0: DirectByteBufferPool
1 ByteBufferArena
-->
<property name="processorBufferPoolType">0</property>
<!-- 默认是65535 64K 用于sql解析时最大文本长度 -->
<!-- <property name="maxStringLiteralLength">65535</property> -->
<!-- 后台任务socket非延迟 -->
<!-- <property name="backSocketNoDelay">1</property> -->
<!-- 前台任务socket非延迟 -->
<!-- <property name="frontSocketNoDelay">1</property> -->
<!-- NIO线程池大小用于处理异步任务,需求小,建议设置为较小值 -->
<!-- <property name="processorExecutor">16</property> -->
<!-- MyCat服务连接端口 -->
<!-- <property name="serverPort">8066</property> -->
<!-- MyCat管理连接端口 -->
<!-- <property name="managerPort">9066</property> -->
<!-- 连接最长闲置时间,超过时间MyCat主动断开连接,单位毫秒 -->
<!-- <property name="idleTimeout">300000</property> -->
<!-- 监听网卡 -->
<!-- <property name="bindIp">0.0.0.0</property> -->
<!-- 前端写队列大小 -->
<!-- <property name="frontWriteQueueSize">4096</property> -->
<!-- 进程数量,默认和CPU核数,建议最大值为cpu的3倍 -->
<!-- <property name="processors">32</property> -->
<!--分布式事务开关
0为不过滤分布式事务
1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤)
2为不过滤分布式事务,但是记录分布式事务日志
-->
<property name="handleDistributedTransactions">0</property>
<!-- 是否启用非堆内存处理跨分片结果集:1开启、0关闭 -->
<property name="useOffHeapForMerge">1</property>
<!-- 内存也大小,单位为m -->
<property name="memoryPageSize">1m</property>
<!-- 溢出文件缓冲区大小,单位为k -->
<property name="spillsFileBufferSize">1k</property>
<!-- 使用流输出,0代表否 -->
<property name="useStreamOutput">0</property>
<!-- 系统保留内存大小,单位为m -->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property>
<!-- 以下参数默认配置未出现 -->
<!-- 默认字符集 -->
<!-- <property name="charset">utf8</property> -->
<!-- Sql执行超时时间,单位秒 -->
<!-- <property name="sqlExecuteTimeout">300</property> -->
<!-- 返回数据集默认大小 -->
<!-- <property name="defaultMaxLimit">100</property> -->
<!-- 允许的最大包大小 -->
<!-- <property name="maxPacketSize">104857600</property> -->
</system>
配置用户及用户访问权限
<!-- 用户名 -->
<user name="root">
<!-- 密码 -->
<property name="password">123456</property>
<!-- 所能访问到的逻辑库,可分配多个数据库 -->
<!-- <property name="schemas">B1,DB2,DB3...</property> -->
<property name="schemas">TESTDB</property>
<!-- 使用加密密码登陆 -->
<!-- <property name="usingDecrypt">1</property> -->
<!-- 对表级DML权限设置 -->
<!-- check:是否启用这个权限
dml顺序:insert、update、select、delete(table上的表示为所有库下的默认权限)
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<!-- 用户是否时只读用户只能查询数据库 -->
<property name="readOnly">true</property>
</user>
密码可加密配置:MyCat的lib文件下执行
java -cp Mycat-server-X.Y.Z.jar io.mycat.util.DecryptUtil 0:[user]:[password]加密密码
SQL防火墙以及SQL拦截
<!--
全局SQL防火墙设置
whitehost 允许访问的名单
blacklist->check 是否启用黑名单
-->
<firewall>
<whitehost>
<host host="127.0.0.1" user="mycat"/>
<host host="127.0.0.2" user="mycat"/>
</whitehost>
<blacklist check="true">
<!-- 开启检查DELETE语句后面where是否为空 -->
<property name="deleteWhereNoneCheck">true</property>
<!-- 开启检查非基本语句的其他语句(DDL) -->
<property name="noneBaseStatementAllow">true</property>
</blacklist>
</firewall>
rule.xml相关配置
rule.xml的规则示例
<!--
tableRule代表表的分片规则,name为唯一标识符号
columns:水平切分依据的列
algorithm:代表使用的具体算法
-->
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<!--
function代表水平切分的算法,name为唯一标识符号,class为实现类
property标签:javabean规范注入的属性
-->
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property>
</function>
常用的切分算法
- 简单取模分片
<tableRule name="mod-long">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property>
</function>
对columns列进行十进制取模运算进行,所以columns列必须为整数,count为分片数量
- Hash取模分片
<tableRule name="user_login">
<rule>
<columns>user_name</columns>
<algorithm>mod-hash</algorithm>
</rule>
</tableRule>
<function name="mod-hash" class="io.mycat.route.function.PartitionByHashMod">
<property name="count">3</property>
</function>
可以对字符串、数字类型的列做hash运算之后再取模进行分片,count为分片数量
- 枚举分片
<tableRule name="sharding-by-intfile">
<rule>
<columns>area_id</columns>
<algorithm>area-map-file</algorithm>
</rule>
</tableRule>
<function name="area-map-file" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">area-map-file.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
<!--
area-map-filet.txt 配置:
10000=0
10010=1
DEFAULT_NODE=1
-->
type默认值为0,0表示key为Integer,非0表示key为 String, 所有的节点配置都是从0开始,及0代表节点1
defaultNode默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点【如果不配置默认节点碰到不识别的枚举值就会报错】
- 字符串范围取模分片
<tableRule name="mod-string-rang-prefix">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-prefixpattern</algorithm>
</rule>
</tableRule>
<function name="mod-string-rang-prefix"
class="io.mycat.route.function.PartitionByPrefixPattern">
<property name="patternValue">256</property>
<property name="prefixLength">5</property>
<property name="mapFile">partition-pattern.txt</property>
</function>
<!--
partition-pattern.txt
0-127=0
128-255=1
-->
字符串范围取模分片是将字符串前缀ASCII码指定前缀相加然后进行取模运算。prefixLength:需要截取的字符串长度,patternValue:取模的模数。如果mapFile文件有些取模之后值未包含,插入取模后未包含的值会报错。
- 范围分片
此分片适用于,提前规划好分片字段某个范围属于哪个分片【start <= range <= end 】
<tableRule name="file-rang-partition">
<rule>
<columns>user_id</columns>
<algorithm>>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">file-rang-partition.txt</property>
<property name="defaultNode">0</property>
</function>
<!--
file-rang-partition.txt
0-10000000=0
10000001-20000000=1
-->
- 自然月分片
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-month</algorithm>
</rule>
</tableRule>
<function name="sharding-by-month" class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2014-01-01</property>
</function>
Mycat还提供了类似redis的crc32slot分片,需要建立槽映射表
schema.xml相关配置
schema标签定义MyCat实例中的逻辑库
<!--
name:逻辑库的名称,全局唯一
checkSQLschema
true: 如果SQL中制定了了DB名称则会呗MyCat自动删除后执行
false:不检查
sqlMaxLimit:返回结果集数量的最大值,如果schema标签有配置,则不会取server文件的配置
-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- table标签。。。 -->
</schema>
table标签定义了MyCat中的逻辑表
<!--
name:逻辑表的名称也是物理表名称,每个schema下唯一
dataNode:所属的 dataNode需要和dataNode标签中name属性的值相互对应,顺序与分片规则枚举有对应关系
rule:用于指定逻辑表要使用的规则(rule.xml中定义)必须与tableRule标签中name属性属性值一一对应
primaryKey:该逻辑表对应真实表的主键,如果分片键不是主键则会缓存主键和分片键的映射关系
如果命中缓存,则使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句给具体的DataNode
type:如果是全局表需要指定global
autoIncrement:如果使用自增ID需要配置
needAddLimit:SQL查询不包含limit时MyCat自动添加limit默认true,limit值为配置的最大返回结果集
-->
<!-- dataNode="dn1,dn2,dn3" ==> dataNode="dn$1-3" -->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" primaryKey="ID" >
<!--可能存在childTable -->
</table>
dataNode标签定义了MyCat中的数据节点
<!--
name:全局唯一标识
dataHost:对应的dataHost标签,用于指定具体数据库示例
database:真实的物理库名称
-->
<dataNode name="dn1" dataHost="DH100" database="db1" ></dataNode>
dataHost标签定义了数据库实例、读写分离配置和心跳语句
<!--
name:唯一标识dataHost标签全局唯一
balance
0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
1:全部的readHost与stand by writeHost参与select语句的负载均衡
简单的说,当双主主备模式,正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
2:所有读操作都随机的在writeHost、readhost上分发
3:所有读请求随机的分发到wiriterHost对应的readhost执行,适合一主多从模式
dbType:后端数据库类型
writeType
0:所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个writeHost
重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties
1:所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐
switchType:
-1:表示不自动切换,如果后台已经使用MMM或MHA这种高可用管理工具,则需要关闭
1:默认值,自动切换。当第一个writeHost宕机自动切换为第二个writeHost
2:基于MySQL主从同步的状态决定是否切换,心跳语句为 show slave status
maxCon:数据库连接池最大连接数
minCon:数据库连接池最小连接数
dbDriver:native为MySQL原身协议,如果dbType不是mysql则需要设置为具体的Driver类名
-->
<dataHost name="DH100" maxCon="1000" minCon="10" balance="0" switchType="-1" writeType="0" dbType="mysql" dbDriver="native" >
<!-- heartbeat:心跳测试语句 -->
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
<!--
<readHost host="hostS1" url="localhost:3306" user="root" password="123456"/>
-->
</writeHost>
<!--
<writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/>
-->
</dataHost>
三、数据库的垂直切分
项目初期可能只是一个单一的数据库,随着业务的增长而出现了性能瓶颈。当无法通过优化来解决性能瓶颈时应该首先通过分库的方式进行解决。引入MyCat进行分库的好处是有连接池的管理和尽量少的修改后台的代码。
进行垂直切分的步骤
①、收集分析业务模块之间的关系
②、复制全量数据到其它实例(建立主从关系,在配置好MyCat之前保持数据都为线上全量数据)
③、配置MyCat垂直分库
④、通过MyCat访问DB
⑤、删除原库中已迁移的表
主从关系建立时从库上的DB名字可能发生了改变,需要使用以下命令修改备份到从数据库的名称
change replication filter replicate_rewrite_db(([masterDBName],[slaveDBName]))
垂直切分配置示例
配置MyCat垂直分库
- schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="app_db" checkSQLschema="false" sqlMaxLimit="100">
<!-- 订单模块 -->
<table name="order_cart" primaryKey="cart_id" dataNode="dn152" />
<table name="order_customer_addr" primaryKey="customer_addr_id" dataNode="dn152" />
<table name="order_master" primaryKey="order_id" dataNode="dn152" />
<table name="order_detail" primaryKey="order_detail_id" dataNode="dn152" />
<!-- 仓配模块 -->
<table name="shipping_info" primaryKey="ship_id" dataNode="dn152" />
<table name="warehouse_info" primaryKey="w_id" dataNode="dn152" />
<table name="warehouse_proudct" primaryKey="wp_id" dataNode="dn152" />
<!-- 商品模块 -->
<table name="product_brand_info" primaryKey="brand_id" dataNode="dn151" />
<table name="product_category" primaryKey="category_id" dataNode="dn151" />
<table name="product_comment" primaryKey="comment_id" dataNode="dn151" />
<table name="product_info" primaryKey="product_id" dataNode="dn151" />
<table name="product_pic_info" primaryKey="product_pic_id" dataNode="dn151" />
<table name="product_supplier_info" primaryKey="supplier_id" dataNode="dn151" />
<!-- 用户模块 -->
<table name="customer_balance_log" primaryKey="balance_id" dataNode="dn149" />
<table name="customer_inf" primaryKey="customer_inf_id" dataNode="dn149" />
<table name="customer_level_inf" primaryKey="customer_level" dataNode="dn149" />
<table name="customer_login" primaryKey="customer_id" dataNode="dn149" />
<table name="customer_login_log" primaryKey="login_id" dataNode="dn149" />
<table name="customer_point_log" primaryKey="point_id" dataNode="dn149" />
<!-- 地区信息,全局表 -->
<table name="region_info" primaryKey="region_id" dataNode="dn149,dn151,dn152" type="global"/>
</schema>
<dataNode name="dn152" dataHost="dh152" database="order_db" />
<dataNode name="dn151" dataHost="dh151" database="product_db" />
<dataNode name="dn149" dataHost="dh149" database="consumers_db" />
<dataHost name="dh152" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.1.152" url="192.168.1.152:3306" user="root" password="123456" />
</dataHost>
<dataHost name="dh151" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.1.151" url="192.168.1.151:3306" user="root" password="123456" />
</dataHost>
<dataHost name="dh149" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.1.149" url="192.168.1.149:3306" user="root" password="123456">
</writeHost>
</dataHost>
</mycat:schema>
- server.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useGlobleTableCheck">0</property>
<property name="sequnceHandlerType">2</property>
<property name="processorBufferPoolType">0</property>
<property name="serverPort">8066</property>
<property name="managerPort">9066</property>
<property name="idleTimeout">300000</property>
<property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property>
<property name="processors">4</property>
<property name="handleDistributedTransactions">0</property>
<property name="useOffHeapForMerge">1</property>
<property name="memoryPageSize">1m</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">100m</property>
<property name="useZKSwitch">false</property>
</system>
<user name="root">
<property name="password">123456</property>
<property name="schemas">app_db</property>
</user>
</mycat:server>
跨分片查询解决方法
①、使用MyCat全局表
②、冗余部分关键数据
③、使用API的方式获取数据
垂直切分的优缺点
优点
- 拆分简单明了,拆分规则明确
- 应用程序模块清晰明确,整合容易
- 数据维护方便,容易定位
缺点
- 部分表关联无法在数据库级别完成,需要在程序中完成
- 对于访问极其频繁且数据量超大的表依旧会有性能瓶颈
四、数据库的水平切分
一般情况下水平切分是在垂直切分依旧不能满足性能要求的时候进行的,应该按照性能需求和业务规则进行水平切分,即可以不水平切分的表不要水平切分。
分片后的查询处理
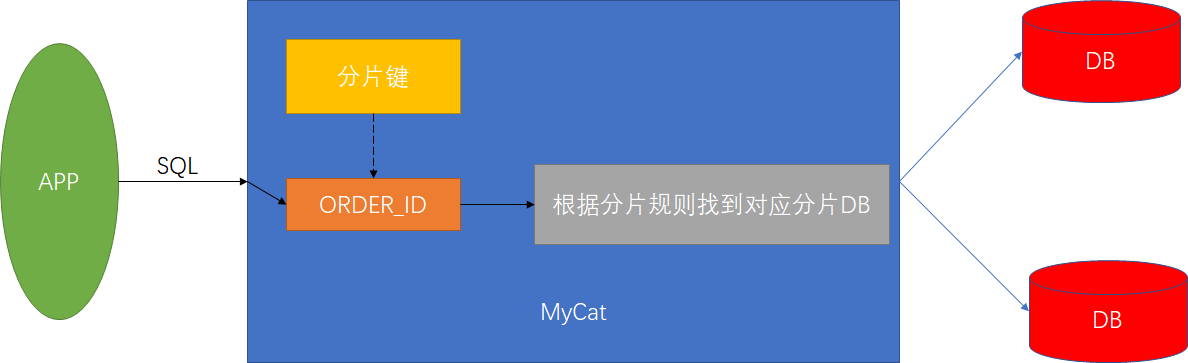
1、MyCat查找查询SQL中的表对应的分片信息
2、判断查询中是否包含分片键
-
如果查询中包含分片键,则根据分片键的分片规则进行计算查找到后台真实物理DB并发送SQL
-
如果不包含分片键则对后台所有配有此Table的物理节点发送SQL
分片键的选择
- 如果没有分片键可选那就选择主键
- 如果有多个分片键选择
- 分片键可以尽可能的将数据均匀分布到各个节点上
- 该业务字段是最频繁的或最重要的查询条件
水平切分配置示例
schema.xml配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="app_db" checkSQLschema="false" sqlMaxLimit="100">
<!-- 订单模块 -->
<table name="order_cart" primaryKey="cart_id" dataNode="dn152_order" />
<table name="order_customer_addr" primaryKey="customer_addr_id" dataNode="dn152_order" />
<!-- 订单表单独水平切分 -->
<table name="order_master" primaryKey="order_id" rule="order_master_mod_long" dataNode="dn152_order01,dn151_order02,dn149_order03">
<!-- ER分片,根据joinKey来进行分片 -->
<childTable name="order_detail" primaryKey="order_detail_id" joinKey="order_id" parentKey="order_id" />
</table>
<!-- 仓配模块 -->
<table name="shipping_info" primaryKey="ship_id" dataNode="dn152_order" />
<table name="warehouse_info" primaryKey="w_id" dataNode="dn152_order" />
<table name="warehouse_proudct" primaryKey="wp_id" dataNode="dn152_order" />
<!-- 商品模块 -->
<table name="product_brand_info" primaryKey="brand_id" dataNode="dn151_product" />
<table name="product_category" primaryKey="category_id" dataNode="dn151_product" />
<table name="product_comment" primaryKey="comment_id" dataNode="dn151_product" />
<table name="product_info" primaryKey="product_id" dataNode="dn151_product" />
<table name="product_pic_info" primaryKey="product_pic_id" dataNode="dn151_product" />
<table name="product_supplier_info" primaryKey="supplier_id" dataNode="dn151_product" />
<!-- 用户模块 -->
<table name="customer_balance_log" primaryKey="balance_id" dataNode="dn149_consumers" />
<table name="customer_inf" primaryKey="customer_inf_id" dataNode="dn149_consumers" />
<table name="customer_level_inf" primaryKey="customer_level" dataNode="dn149_consumers" />
<table name="customer_login" primaryKey="customer_id" dataNode="dn149_consumers" />
<table name="customer_login_log" primaryKey="login_id" dataNode="dn149_consumers" />
<table name="customer_point_log" primaryKey="point_id" dataNode="dn149_consumers" />
<!-- 地区信息,全局表 -->
<table name="region_info" primaryKey="region_id" dataNode="dn149_consumers,dn151_product,dn152_order" type="global"/>
</schema>
<dataNode name="dn152_order01" dataHost="dh152" database="order_db01" />
<dataNode name="dn151_order02" dataHost="dh151" database="order_db02" />
<dataNode name="dn149_order03" dataHost="dh149" database="order_db03" />
<dataNode name="dn152_order" dataHost="dh152" database="order_db" />
<dataNode name="dn151_product" dataHost="dh151" database="product_db" />
<dataNode name="dn149_consumers" dataHost="dh149" database="consumers_db" />
<dataHost name="dh152" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.1.152" url="192.168.1.152:3306" user="root" password="123456" />
</dataHost>
<dataHost name="dh151" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.1.151" url="192.168.1.151:3306" user="root" password="123456" />
</dataHost>
<dataHost name="dh149" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.1.149" url="192.168.1.149:3306" user="root" password="123456">
</writeHost>
</dataHost>
</mycat:schema>
rule.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="order_master_mod_long">
<rule>
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property>
</function>
</mycat:rule>
水平切分引发主键问题
水平切分带来了主键自增问题,可以使用本地文件方式、数据库方式 、本地时间戳方式 、ZK ID 生成器和程序使用Redis生成自增ID的方式
Zk 递增方式
前提条件MyCat是集群模式,已加入zookeeper建立连接
- 配置
server.xml加入以下部分
<system>
<property name="sequnceHandlerType">4</property>
</system>
- 配置
sequence_conf.properties
# 全局
GLOBAL.HISIDS=
GLOBAL.MINID=10001
GLOBAL.MAXID=20000
GLOBAL.CURID=10000
# 自定义数据
ORDER.HISIDS=
ORDER.MINID=1001
ORDER.MAXID=2000
ORDER.CURID=1000
- 插入SQL改造
-- 使用全局配置
insert into order(id, ...) values(next value for MYCATSEQ_GLOBAL, ...);
-- 使用单独表配置
insert into order(id, ...) values(next value for MYCATSEQ_ORDER, ...);
五、MyCat高可用搭建
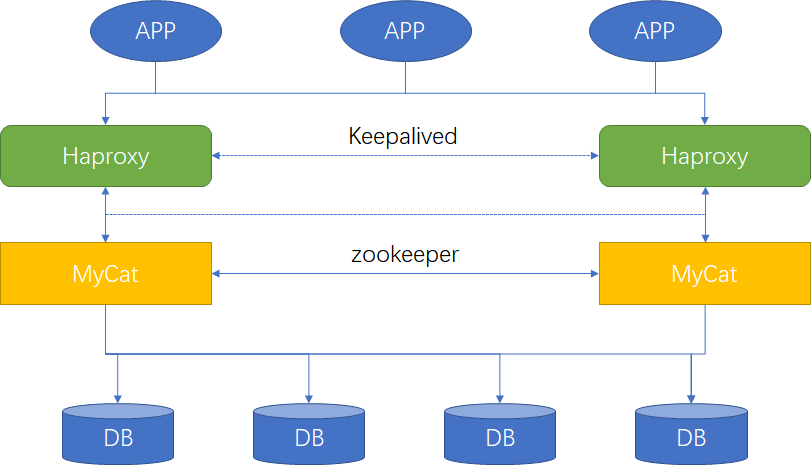
MyCat集群搭建
前期准备:搭建好zookeeper集群
第一步:拷贝修改和增加的配置文件到$MyCat/conf/zkconf下
# 需将所有修改的配置全部覆盖
cp rule.xml schema.xml server.xml zkconf/
第二步:配置$MyCat/conf/myid.properties
loadZk=true
zkURL=192.168.1.158:2181,192.168.1.158:2182,192.168.1.158:2183
# 集群ID,规划为同一个集群的clusterId要相同
clusterId=mycat-cluster
# 每个节点的ID,不能重复
myid=mycat_fz_01
# 每个节点的名称,需要全部写这里
clusterNodes=mycat_fz_01,mycat_fz_02
type=server
boosterDataHosts=dataHost1
第三步:上传文件内容到zk集群
# 这个命令需要在$MyCat/bin目录下执行否则目录位置会出现问题
init_zk_data.sh
第四步:重启mycat
此时可以查看集群中所有mycat配置是否一致
MyCat自身高可用
搭建Haproxy实现Mycat后台负载均衡
第一步:安装Haproxy
yum install haproxy
第二步:修改/etc/haproxy/haproxy.cfg的配置
global
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
# 使用tcp时注释掉要不会有警告
# option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
# haproxy管理员登陆界面
listen admin_stats
bind 0.0.0.0:4001
mode http
stats uri /stats
stats realm Haproxy\ Statistics
stats auth admin:admin
stats admin if TRUE
# mycat服务负载
listen allmycat_service
bind 0.0.0.0:8069
mode tcp
option tcplog
balance roundrobin
server mycat1 192.168.1.158:8066 check inter 5s rise 2 fall 3
server mycat2 192.168.1.149:8066 check inter 5s rise 2 fall 3
option tcpka #keepalived死链检测
# mycat监控端口负载
listen allmycat_admin
bind 0.0.0.0:9069
mode tcp
option tcplog
balance roundrobin
server mycat1 192.168.1.158:9066 check inter 5s rise 2 fall 3
server mycat2 192.168.1.149:9066 check inter 5s rise 2 fall 3
option tcpka #keepalived死链检测
第三步:检查启动
# 检查配置文件是否正确
haproxy -c -f /etc/haproxy/haproxy.cfg
# 启动
haproxy -f /etc/haproxy/haproxy.cfg
搭建keepalived作用于haproxy实现高可用
第一步:安装keepalived
yum install keepalived
第二步:修改/etc/keepalived/keepalived.conf的配置
! Configuration File for keepalived
global_defs {
# 每个节点不一样
router_id 152
}
# 检查脚本配置。必须在使用脚本之前配置好
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 2 #检测时间间隔
weight -20 #如果条件成立则权重减20
}
vrrp_instance VI_1 {
# 分为MASTER和BACKUP
state MASTER
# 网卡
interface enp0s3
# 同一组keepalive此值一样用于区分组
virtual_router_id 101
# 优先级别
priority 100
# 非抢占模式,MASTER有用
nopreempt
# 广播优先级间隔时间
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.101
}
# 要放在VIP后面
track_script {
check_haproxy
}
}
第三步:配置检查脚本【必须要有执行权限】
#!/bin/bash
A=`ps -C haproxy --no-header |wc -l`
if [ $A -eq 0 ];then
echo "`date` haproxy is dead" >> /tmp/lvs.log
haproxy -f /etc/haproxy/haproxy.cfg
sleep 2
fi
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
echo "`date` haproxy cannot start,stop keepalived" >> /tmp/lvs.log
# 杀死keepalived
ps -C keepalived --no-header | awk '{print $1}'|xargs kill -9
exit 0
else
echo "`date` haproxy restart" >> /tmp/lvs.log
exit 1
fi
第四步:启动keepalived和查看日志
keepalived -f /etc/keepalived/keepalived.conf
tail -f -n 50 /var/log/messages
六、MyCat监控
使用MyCat生成执行SQL记录
在server.xml的system标签下配置拦截
<system>
<!-- 配置拦截器 -->
<property name="sqlInterceptor">
io.mycat.server.interceptor.impl.StatisticsSqlInterceptor
</property>
<!-- 配置拦截SQL类型 -->
<property name="sqlInterceptorType">
select,update,insert,delete
</property>
<!-- 配置SQL生成文件位置 -->
<property name="sqlInterceptorFile">
/opt/mycat/InterceptorFile/sql.txt
</property>
</system>
MyCat命令行管理工具
使用名 mysql -u[username] -p -P[管理端口,默认9066] -h[ip]连接MyCat命令行管理端
-- 帮助命令
show @@help \G;
-- 重新加载配置
reload @@config;
reload @@config_all;
-- 显示物理服务器信息
show @@databases \G;
-- 显示datanode节点
show @@datanode \G;
-- 显示所有连接信息
show @@connection \G;
-- 杀死连接
kill @@connection id1,id2,...
-- 展示后台链接详细信息
show @@backend \G;
-- 显示当前缓存信息(ER分片信息、主键缓存、路由缓存)
show @@cache \G;
-- 显示配置的物理服务器信息
show @@datasource \G;
MyCat的GUI管理工具
使用mycat-web可以更加直观的看到mycat集群状态,下载地址,配置时注意修改mycat-web/WEB-INF/classes/mycat.properties,默认访问地址 http://ip:8082/mycat
# 只需修改zookeeper这行
zookeeper=localhost:2181
七、MyCat的限制
MyCat不支持的SQL语句
- DDL语句【如:create table like xxx / create table select xxx / create table】
- 跨库多表关联,子查询
- select for update/select lock in share mode【这俩语句只会随机发送到后端一个节点导致数据库出现问题】
- 多表update或update分片键
- 跨分片的带有limit的update/delete
对事务的支持有限(XA 事务)
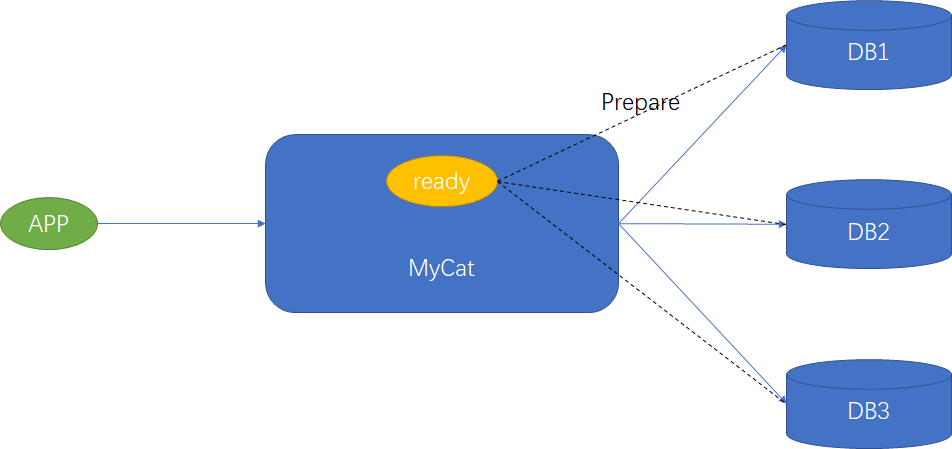
第一步:像后台数据库发送begin
第二步:发送执行的SQL,等待所有节点都返回成功才执行下面步骤,如果有任何一个返回失败,全部rollback
第三步:执行commit等待所有节点返回,等待结果返回给客户端,如果有任何一个返回失败,返回事务处理失败
如果有commit过程中任意一个节点报错,数据一致性将无法保证(可能性很小)